用Django编写后端任务流程
Posted 点融黑帮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用Django编写后端任务流程相关的知识,希望对你有一定的参考价值。
什么是Django
Django是Python编程语言开发一种开源Web框架,这里将用到其自带的ORM(数据库对象关系映射)。阅读本篇代码需要Python基础和Django基础。
为什么用Django
因为我们的目标是提供用户自定义任务流程,所以需要有一种交互方式,这里选用B/S架构,用户使用浏览器来和我们的服务交互。当然,也可以选择其他Web框架。不过,本篇不会涉及到前端实现。
什么是后端任务流程
例如,执行传统应用发布:
代码构建——程序测试——程序分发——程序重载
又如执行Docker镜像发布:
代码构建——Docker镜像构建——Docker镜像测试——Docker分发和重载(k8s等)
还有很多不同种类的后端任务,需要多个步骤,且相互又关联的任务流程,符合本篇讲述的对象。
任务流程的设计
☞自定义的任务流程
按照我们的构想,用户自定义地来定制自己的任务流程,那么,任务流程不可能是写死的代码,只能是可以修改的数据,所以我们需要用数据库来存储任务流程。
根据这个设计,我们可以用代码表示出来:
from django.db import models
class Task(models.Model):
create_at = models.DateTimeField(auto_now_add=True)
name = models.CharField(max_length=100)
content = models.TextField()
其中,假设我们的操作存储到content字段中。
☞任务流程的形态
任务有了,但是他们是各自独立的,并没有相互之间的关系,而我们构想的任务流程,实际上是若干和任务,相互关联起来形成的任务链,任务树(无循环,否则就成死循环了),所以,还需要定义任务之间的关系。
那么,我们这里就直接使用Django下的ORM自关联关系了。
代码如下:
from django.db import models
class Task(models.Model):
create_at = models.DateTimeField(auto_now_add=True)
name = models.CharField(max_length=100)
content = models.TextField()
# 自关联多对多关系,取消对称,因为不能让下一个task的next_tasks能关联到当前task
next_tasks = models.ManyToManyField("self", symmetrical=False) # 查询当前task上一个task,就用self.task_set.all() 好了,设计这样的任务的ORM类,就可以对其进行关系处理了。
示例代码:
task1 = Task(name=u"起始任务", content="operation1") # 创建起始任务
task2 = Task(name=u"子任务", content="operation2") # 创建起始任务的子任务
task1.next_tasks.add(task2) # 将子任务加入到起始任务的next_tasks关系中 其关系如图
有了这样的关系,我们可以给起始任务创建和关联其他子任务,给子任务创建和关联孙子任务等。
通过这种关系,我们就可以创建任务链和任务树了。
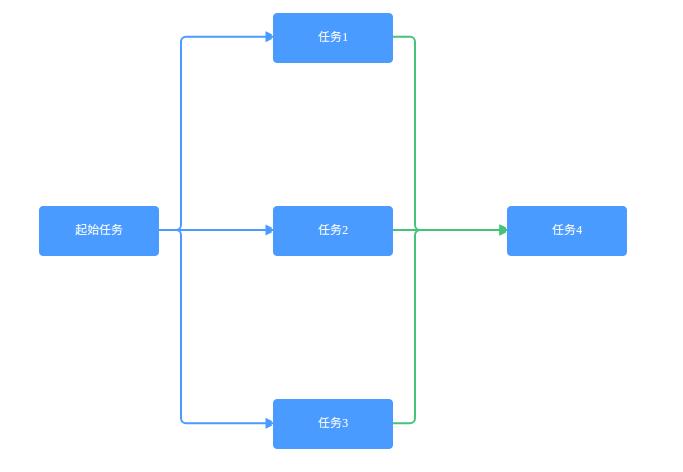
☞漏斗型任务流程
有时候,我们在应用场景的某些操作,需要在操作1,2,3都完成的情况下,才能执行,这种情况从流程图来看,类似一个漏斗。
那么,怎样操作任务关系才能符合要求呢。聪明的你肯定知道,代码操作就是给任务1,2,3都添加这个子任务到他们的next_tasks下。
示例代码:
task1 = Task(name=u"任务1", content="operation1")
task2 = Task(name=u"任务2", content="operation2")
task3 = Task(name=u"任务2", content="operation3")
task4 = Task(name=u"任务2", content="operation4")
task1.next_tasks.add(task4)
task2.next_tasks.add(task4)
task3.next_tasks.add(task4) 其关系如图
☞任务组标识
完成前三步的设计,任务流程已经初具规模了,让人觉得,将其对应的后端操作完善,是否就可以算是完成了呢?不急,这里还有一个重要的细节需要处理。
由于我们定义的类是任务,而无论任务链,任务树,任务漏斗,都是由若干各任务组成的,虽然我们已经通过定义的关联关系得知他们的关系,但是,我们无法快速区分不同的任务链等。
这里引入任务组这样一个概念,定义了隶属于一个任务链等结构的任务。
可以定义一个TaskGroup类来存储任务组,不过为了简单,我们直接给Task类增加一个字段root来进行划分。
代码如下:
from django.db import models
class Task(models.Model):
create_at = models.DateTimeField(auto_now_add=True)
name = models.CharField(max_length=100)
content = models.TextField(default="")
next_tasks = models.ManyToManyField("self", symmetrical=False)
root = models.IntegerField(default=0) # 用来标识第一个任 值得注意的是,我们定义root这个字段默认为数字0,实际编程中,我们会将其子任务的root设为起始任务的数据记录id。
通过查询root字段为0的Task的实例,可以得到所有的起始任务,根据某个起始任务的id字段值,我们可以查出所有属于这个起始任务的后代任务。
☞编排与运行的区别
我们可以留意到,上述设计,都是针对任务编排做的,也就是用户如何去进行任务流程的定义,但却并没有涉及到任务的运行。
简单地设想下,给Task类增加一个run方法执行操作,添加一个result字段保存结果是否就满足需求了呢。聪明如你,肯定要说NO!因为result字段,不可能存储每次任务执行的结果,即便该字段无限大,检索某次任务执行结果的成本也是很大的。所以,需要将任务执行结果单独存放,以便检索。
我们定义一个Job类,代码如下:
class Job(models.Model):
start_at = models.DateTimeField(blank=True, null=True)
result = models.TextField(blank=True, null=True)
task = models.ForeignKey(Task, blank=True, null=True, on_delete=models.SET_NULL)
# 自关联多对多关系,取消对称,因为不能让下一个job的next_jobs能关联到当前job,设计job的上下游关系,是为了执行漏斗型的编排任务,这样才能方便地查询上游job。
next_jobs = models.ManyToManyField("self", symmetrical=False) # 查询当前job上游job,就用self.job_set.all()
root = models.IntegerField(default=0) # 用来标识第一个job 可以注意到,除了result字段来存储结果外,我们还保留了运行结果的对应任务流程的关联关系和运行结果组的定义。
这样做的好处是,编排任务的执行不一定全部成功,那么运行结果的关联关系就显得很重要了。而一个任务对应很多运行结果,所以定义结果组也是有必要的。
这里定义job和task的关系,当task删除时job不删除(on_delete=models.SET_NULL),是为了保存操作结果,以便审计。
任务流程的运行
☞给任务添加run方法
任务的创建就是为了运行,最好是成功地运行。
根据之前的任务流程设计可以这样设计run方法:
任务运行成功的情况下,才调用下一个任务的运行(任务链,任务树);
当前任务运行之前,先检查当前任务的所有前置任务是否都运行成功(任务漏斗);
当前任务运行成功后,返回的是产生的运行结果的实例(Job的实例);
根据以上设计,得出代码如下:
def run(self, prev_job=None): # 根据prev_job得知当前的运行结果组,如果没有,则当前运行结果就是起始任务的运行结果
job = Job(task=self)
prev_job_list = []
if prev_job:
job.root = prev_job.root
job.save()
prev_job_list = Job.objects.filter(root=prev_job.root, task__in=self.task_set.all()).all()
# 执行前的判断:所有前置任务都已经通过,才执行本任务,all_success方法,自行根据单个任务的操作和结果来定义,返回值为True or False
if {prev_job.task for prev_job in prev_job_list if prev_job.all_success()} == set(self.task_set.all()):
for _prev_job in prev_job_list:
if not _prev_job.next_jobs.filter(task=self).exists(): # 此处对运行结果进行关联
job.job_set.add(_prev_job)
else:
print("已存在当前任务的该次job,删除当前job,当前task:{0}".format(self.argument))
job.delete() # 此处删除运行结果,是因为如果已存在当前任务的数据库记录,但是又再一次需要运行当前任务,证明当前任务依赖多个前置任务的成功运行,只能存在一份运行结果,所以新的job实例就删除掉,并且退出运行。
return
result = operate(self.content) #虚拟的操作和运行结果
job.result = result
job.save()
for next_task in self.next_tasks.all():
next_task.run()
return job
上述代码已经基本实现了我们对run方法的设计。当我们对起始任务调用run方法时,任务会一直阻塞,直到所有任务线都完成或失败,才会返回结果。
可以使用多线程编程的方法,让起始任务直接返回它的任务结果,然后其子任务分别在各自的线程执行即可,多线程编程不在本篇讨论范围之内,聪明如你,一定会自行想办法完成改进该示例代码。
☞展示运行的结果
有了run方法之后,你一定会迫不及待地运行你的任务组,运行之后的结果,会保存到数据库中。
使用Job类来查询当次运行结果,可以这样操作:
root_task = Task.objects.filter(name=u"起始任务").first()
root_job = root_task.run()
sub_jobs = Job.objects.filter(root=root_job.id).all()
if len(sub_jobs) == len(Task.objects.filter(root=root_task.id).all()) and root_job.all_success() and all([sub_job.all_success() for sub_job in sub_jobs]):
print "任务组运行成功"
else:
print "任务组运行失败" 上述代码只能粗略地展示该任务组下的任务是否全部运行成功。如果需要详细地展示每个任务的运行成功和失败情况,则需要细致查询了。
那么,如何方便和直观地查看任务运行结果呢,这就需要结合Web前端来进行展示了,示例图如下:
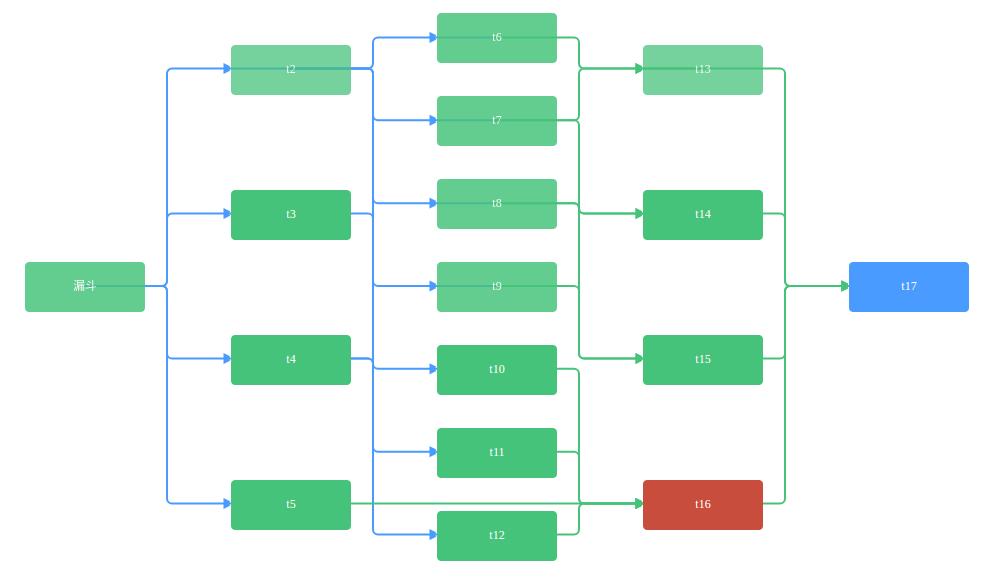
如图所示,当任务运行成功,则将任务变成绿色,如果运行失败,将任务变成红色,后续未运行的任务保持蓝色。
至于如何利用Web前端来展示任务运行结果的具体实现,就不属于本篇讨论范围了。
总结
通过对实现目标的设想,以及细致地对自定义任务流程的设计,我们遇到和解决了很多细节问题。
任务的运行依赖与之前任务流程的设计。
任务运行结果的展示,依赖于对操作和运行结果的解析。
当实现了简单的任务流程之后,还可以考虑更加灵活的任务流程和扩展需求,例如任务结果非成功依赖,非阻塞任务(运行该任务的同时,无论其是否运行和运行结果如何,直接运行其子任务)等。
当然,灵活的代价就是管理成本和复杂度的增加,适当考虑应用场景,使用恰当的手段非常重要。


点击回顾往期精彩内容
以上是关于用Django编写后端任务流程的主要内容,如果未能解决你的问题,请参考以下文章