如何运用领域驱动设计 - 聚合
Posted dotNET知音
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何运用领域驱动设计 - 聚合相关的知识,希望对你有一定的参考价值。
出处:https://www.cnblogs.com/uoyo/p/12061334.html
概述
在前几篇的博文中,我们已经学习到了如何运用实体和值对象。随着我们所在领域的不断深入,领域模型变得逐渐清晰,我们已经建立了足够丰富的实体和值对象。但随着实体和值对象的数量逐渐增多,它们之间的关系也显得越来越复杂:实体A与实体B存在一对一的关系,实体B又与实体C存在一对多的关系。就这样一层套一层,本来约束已经足够好的领域对象们彷佛已经开始对我们不太友好。为了处理这一系列的问题,我们需要将一些实体和值对象划分在一个统一的边界内,原来存在多重关联关系的大模型被分解为较小的领域对象群。
而这种强有力的划分手法就是领域驱动设计战术模式中的“聚合”。可能大家已经听过它的一个重要部分“聚合根”,那么我们什么情况下考虑使用聚合根呢?聚合根又是从什么地方来?聚合与实体之间又有什么关系?如何确定和划分一个合理的聚合?本文将从不同的角度来带大家重新认识一下“聚合”这个概念,并且给出相应的代码片段(本教程的代码片段都使用的是C#,后期的实战项目也是基于 DotNet Core 平台)。
何为聚合
还是先来看看原著《领域驱动设计:软件核心复杂性应对之道》 中对聚合的有关解释:
在具有复杂关联的模型中要想保证对象更改的一致性是很困难的。不仅互不关联的对象需要遵守一些固定规则,而且紧密关联的各组对象也要遵守一些固定规则。然而,过于谨慎的锁定机制又会导致多个用户之间臺无意义地互相干扰,从而使系统不可用。
首先,我们需要用一个抽象来封装模型中的引用。AGGREGATE就是一组相关对象的集合,我们把它作为数据修改的单元。每个AGGREGATE都有一个根(root)和一个边界(boundary).边界定义了AGGREGATE的内部都有什么。根则是AGGREGATE中所包含的一个特定Entity。在AGGREGATE中,根是唯一允许外部对象保持对它的引用的元素,而边界内部的对象之间则可以互相引用。除根以外的其他Entity都有本地标识,但这些标识只有在AGGREGATE内部才需要加以区别,因为外部对象除了根Entity之外看不到其他对象。
演化案例
还记得我们在上一篇博文 如何运用领域驱动设计 - 实体 中所展开的一个关于旅行记账的案例吗? 在学习实体的时候,我们已经构建了一个叫做Itinerary的实体,并且赋予了它应用的行为操作。 到目前为止,我们那个案例好像还和主题离的稍微有点远,我们虽然实现了行程这个东西,但是怎么记账呢?
接下来,让我们完善这个案例,让它更贴近于我们真实的项目需求:
当用户创建一个行程时,则证明该旅程的账单已经被开启了。创建该行程的用户被认定为管理员,他可以添加参与该行程的小伙伴。所有参与行程的小伙伴,都可以在旅行的过程中记账(比如小伙伴C和小伙伴A吃了一顿火锅花了300块钱,小伙伴C则可以记入本笔开销,而该笔开销的参与者是小伙伴C和A),当大家旅行完成了之后就可以进行结算,讲费用平摊到每个人身上,谁需要补钱,谁需要退钱等都可以被该应用计算出来。
这是简化后的版本,为的是希望大家能大致明白我们需要做一个什么样的东西,并且如何用我们所学到的领域驱动设计知识来建模和编码,为了让大家更清晰的理解需求,我粗浅的为大家绘制了一个原型图:
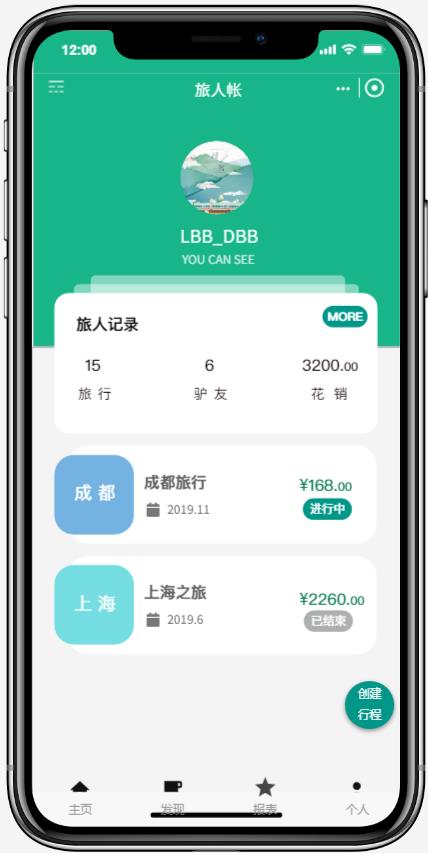
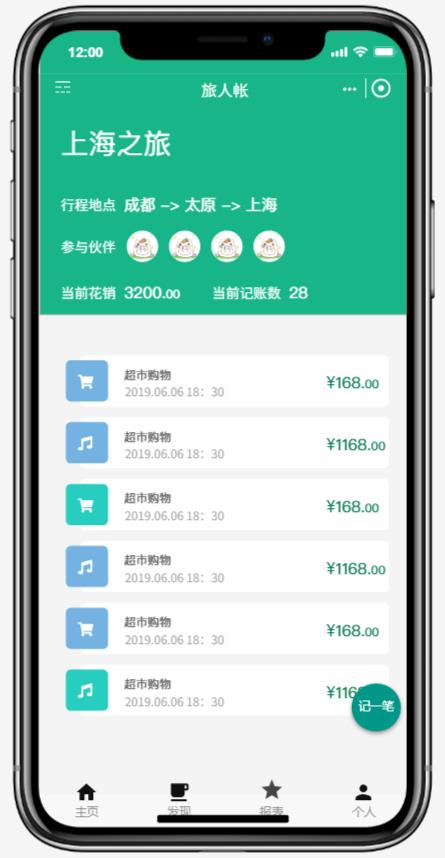
发现实体关系
根据需求描述,再结合我们已有的领域设计知识,我们马上就能找出另外一个重要的实体对象出来。没错,那就是账单。在这个案例中,我们暂定将账单命名为记账薄(Account book)。在第二个原型图中,我们大致能够理解记账薄是一个什么东西,它记录了行程中所有的开销内容和开销金额。这一行一行的开销信息,我们将它命名为开销项(Overhead item)。这里为了简化起见,我们忽略了每条开销项中的其它信息,例如参与人员,参与地点等等。
接下来,我们来分析已经发现的两个事物:记账薄 与 开销项。先来说开销项吧,它是属于实体还是值对象呢?结合前两篇博文中我们说学到的内容,它需要一个ID来辨识它吗? 也许还是有些困惑,因为好像它不像性别、姓名这一类东西具有很明显的无ID特征。所以我们需要来识别该对象拥有的属性:开销内容、开销金额、开销时间。“在2019年10月12日,买了一个冰糕花费了3元人民币”,在我们当前的领域,我们需要使用一个ID来区分它吗?很显然我们是需要的,我们不能说只要在同一时间花了同样的钱买了同样的东西就是一样的东西了,比如用户A在行程A中和用户B在行程B中同时间同样的钱买了同样的东西,我们会认为是一样的吗?很显然,不能。所以开销项是一个实体。那么记账薄呢?很显然,它也是一个实体,我们需要通过ID来识别到底是哪个记账薄。
此时我们已经捕获出了两个实体对象:记账薄 与 开销项。而且可以清楚的看到,它们之间是一个一对多的关系。然后来尝试将它们转换为我们熟悉的C#代码吧:
public class AccountBook
{
public Guid ID { get; private set; }
public List<OverheadItem> OverheadItems {private get;private set; }
//ctor
// 记账薄的行为
// ....
}
public class OverheadItem
{
public Guid ID { get; private set; }
//开销内容
public OverheadContent Content { get;private set; }
//开销金额
public OverheadMoney Money { get;private set; }
// ctor
// 开销项目的行为
// ....
}
public class Itinerary
{
public int ID { get; set; }
public List<Person> Participants { get;private set; }
public List<Address> Places { get;private set; }
public ItineraryNote Note { get;private set; }
public ItineraryTime TripTime { get;private set; }
public ItineraryStatus Status { get;private set; }
//ctor
// 行程的行为
// ....
}
OK,此时我们已经完成了记账有关的模型。再来回顾我们之前的行程实体模型:“当旅程建立的时候,则证明该旅程的账单已经被开启了”,因此我们可以看出,旅程和账薄是连接在一起的,一个旅程就对应着其拥有的对应账薄,所以它们是一个一对一的关系。
到目前为止,我们拥有了三个比较明显的实体:旅程、记账薄、开销项目,还有该领域中很多大大小小的值对象。旅程和记账薄是一对一的关系,记账薄和开销项目是一对多的关系。多读一下它们之间的关联关系,唉!!!好累,那是不是再引入一个领域对象进来,就会让它们之间的关系更复杂呢?这样一层绕一层,就仿佛滚毛线球一样,越理越乱了。
开始划分边界吧
我根据目前所涉及的领域对象,大致绘了一个领域之间的图,当然这个图并不是规范的,里面缺少了很多我们已经捕获出来的值对象等等,它只是为了帮助你大致回顾一下我们目前所Get到的领域模型结果:
图中将“旅行记账”的部分于“推荐”的部分用了方块给隔离开来,这个结果我想大家也很容易理解,因为有关推荐的这些东西,比如推荐餐馆呀,推荐花店呀对我们的旅行记账来说并没有太大的关系。关系域于关系域中,我们通过划分了一个合理的边界来隔离它们,那么反过来思考,一个域中的各个领域对象,我们能不能通过一个什么手段来划分它们呢?将它们通过边界的隔离,实现区域内的自治,这样更方便我们来处理它们之间的逻辑关系。
假如用户想查看当前行程的记账薄,按照常规处理我们会怎么办呢? 用户会访问有关记账薄的仓储(仓储的有关概念将在下一篇文章讲解),获取到当前记账薄。此时,用户获取到了账薄的有关信息,比如开销项啊,总开销金额啊等等,但是对用户来说,它是很迷茫的,因为它仅仅获取到了账薄的信息,它不知道这个账薄属于哪次行程,所以它必须又得去获取一下行程的信息。而这种场景往往都是一起出现的,你只要获取账薄你就必须要获取行程。
可能你已经发现了,它们其实可以是一体的。就像开销项和记账薄是一体的一样,行程和记账薄这两个大实体居然也是可以是一体的。而这种关系,就是我们今天的主题——“聚合”。
我们可以将旅行行程、记账薄、行程人员、开销项、行程时间等一系列有关的对象都划分在行程的边界内,因为确确实实它们是属于行程的,一旦脱离了行程它们好像都没有任何意义。
选取一个聚合根
行程和记账薄是一体的,且它们是一对一的关系。如果将这个关系转换为我们熟悉的代码,我们需要将一个类作为另一个类的属性,那么在这个案例中,我们是用行程包含记账薄,将记账薄作为属性呢?还是记账薄包含行程呢? 你也许会说,它们可以相互包含。确实,现在的ORM框架可以运行你将两者互相包含并映射到数据库,但是在这里我们没有必要这么做,因为我们已经知道,它们是一个整体,获取一者另外一者同样会被获取到,不需要再次嵌套。回到刚才那个问题,是谁在外层呢?其实答案也很清晰了,因为从该例子来说,我们更关注的是行程,所以我们很自然的就会将行程作为主要的实体对象,而在这个聚合关系中,被我们选取出来作为边界范围的实体就是我们所说的聚合根。
此时我们的代码可能已经可以改变成这样了:
public class Itinerary
{
public int ID { get; set; }
public List<Person> Participants { get;private set; }
public List<Address> Places { get;private set; }
public ItineraryNote Note { get;private set; }
public ItineraryTime TripTime { get;private set; }
public ItineraryStatus Status { get;private set; }
//将记账薄放置在了旅行中
public AccountBook AccountBook{get;private set;}
//ctor
// 行程的行为
// ....
}通过聚合根保护你的内部对象
当识别出了一个聚合根的时候,就要保证该聚合的内部是自治的。我们不能从外界直接访问聚合根内部的任何领域对象,比如在上面的案例中,我们则不能直接记账薄这个实体。如果我们确确实实需要获取记账薄中的有关信息,我们必须通过聚合根,也就是上面的行程来访问。也就是说我们得从仓储中获取行程后再来得到记账薄的有关信息。
此时,你可能会说,那这样不就会很麻烦了吗?我只要记一笔账,但我必须要得到旅程的所有信息。这样数据库和应用程序不是增加了一些压力吗? 是的,这样做我们会将更多的数据加载到内存之中来。但是这是合理的,回顾刚才一下上面的案例,我们有什么情况下需要只获取账薄,不获取旅程信息呢? 是的,没有,它们永远是一起出现的。
当聚合内部的对象无法直接访问的时候,很显然也不能直接调用该对象所公开出来的行为了。比如记账薄可能会拥有一个叫做“记一笔账(RecordAnAccount)”的行为,我们通过访问该行为操作就可以将开销项增加到记账薄中。但是现在我们不能直接访问记账薄了,我们怎么记账呢? 通过转移行为给聚合根来完成,比如我们会将该行为转移到行程中,并公布一个叫做“记录行程中一笔账”的行为供客户端调用。
public class Itinerary
{
//Other Property....
public List<Person> Participants { get;private set; }
public AccountBook AccountBook{get;private set;}
//ctor
public void RecordAnAccountInItinerary(
int PersonID,
string itemName,
double costMoney)
{
bool hasThisPerson = Participants.Any(Person=>Person.ID = PersonID);
if(!hasThisPerson)
throw new PersonNotInThisItineraryException();
AccountBook.RecordAnAccount(itemName,costMoney);
}
}这样一来,聚合根内部的所有对象都不会被外界肆意访问,而且通过聚合根所表达出来的行为也更容易让人能够理解。
聚合的一些特性
到了现在,再回头去看一下概述中原著对聚合概念的阐述。我们可以已经大致理解了什么是聚合,聚合根又是怎么来的:
聚合是一个明确的边界
聚合的出现是为了解决领域模型之间的复杂关联关系的
聚合封装了一系列的相关对象,它是这些对象的集合
聚合应该有一个根,并且这个根是通过集合中的一个实体选出来的
聚合外部的事务想引用聚合只能通过根的ID来访问
再来给大家举一个原著中的例子,加深印象:汽车修配厂的软件可能会使用一个汽车模型。汽车是一个具有全局标识的ENTITY:我们需要将这部汽车与世界上所有其他汽车区分开(即使是一些非常相似的汽车),我们可以使用车辆识别号来进行区分,车辆识别号是为每辆新汽车分配的唯一标识符。我们可能想跟踪4个轮胎的历史转数。我们可能想知道每个轮胎的里程数和磨损度。要想知道哪个轮胎在哪儿,必须将轮胎标识为Entity。轮胎被安在汽车上,也不会有人要系统中查询特定的轮胎,然后看看这个轮胎在哪辆汽车上。人们只会在数据库中查找汽车,然后临时查看一下这部汽车的轮胎情况,因此,汽车聚合中的根Entity,而轮胎只是处于这个聚合的边界之内。
作为一名普通的手机用户,当屏幕摔碎的时候,他会选择将整个手机送至维修中心。因为对他来说手机是一个整体。会不会有人自己把屏幕单独送去维修中心呢?有吧,可能他是维修师傅。通过ID引用
public class Student
{
public int ID { get; set; }
public string LastName { get; set; }
public string FirstMidName { get; set; }
public DateTime EnrollmentDate { get; set; }
public ICollection<Enrollment> Enrollments { get; set; }
}
public class Enrollment
{
public int EnrollmentID { get; set; }
public int CourseID { get; set; }
public int StudentID { get; set; }
public Grade? Grade { get; set; }
public Course Course { get; set; }
public Student Student { get; set; }
}该代码摘自aspnetcore基础教程
这样的代码是很常见的,许多开发人员都找到了一种自然方式在代码中将关系建模为对象引用。特别是在使用EF Core中,我们会很自然的将不同对象之间的关系通过对象引用来表示。这是因为我们以往并没有聚合的这一概念,所以我们要完成一个关联的操作就需要加载所有的关联对象然后通过遍历一个一个的实例对象来处理。很显然,这会造成性能上的浪费,虽然我们可以使用延迟加载的技术来处理,但是延迟加载会让模型的处理更加复杂。
在上面的例子中,假如我们需要知道这个行程创建的管理员用户是谁。我们会怎么处理呢?管理员用户被抽象为了一个单独的聚合根User,该聚合包含了User所有的信息(身份,姓名,性别等等)。我们会在Itinerary聚合根中添加一个类型为User的属性作为管理员吗?不需要,在该领域中,我们为什么要关心管理员的其他信息呢,以至于每次加载行程都还需要带出用户的信息。很显然,我们在Itinerary聚合中并不会关心另外聚合的情况。所以,当一个聚合需要引用到另外一个聚合的时候,千万不要直接使用类型的强引用方式来实现,而是通过使用引用聚合的ID来维持聚合与聚合的关系。
这样做的好处在分布式系统中更容易体现,旅程和用户这两者往往会被放在不同的系统中,旅程边界中根本就找不到一个叫做User的实体,而它们之间的引用关系只能通过ID来标记。
聚合真的是不变的吗
可能我们通过分析领域模型,已经建立了一个相对来说很好的聚合了,并且提取出了聚合根,将领域对象控制在聚合根的内部。但是?聚合根里面的实体就永远存在聚合根之内吗?答案是不一定的。我们之所以将实体放置在聚合根之内是因为我们知道他与聚合根是一体的,外界访问该实体的时候一定会携带上访问聚合根实体。但是!!!!!假如我们需求的变更让我们确确实实需要单独访问目前聚合根里面的实体呢? 是的,它可能会被单独提升为一个聚合根。而且通过ID之间的引用保持对原有聚合根之间的关联关系。
所以考虑聚合根的重要一点是:在领域中我们是否会单独访问该实体?
小的聚合
有时候,聚合的优势可能会成为糖衣炮弹,它会让你疯狂的将大量的实体和值对象融入在其中去,最后的结果是造成聚合越来越大。这样会造成性能的瓶颈,特别是在某个实体存在大量结果的情况下,这简直是一个噩梦。所以在考虑聚合之前,我们要多思考,我们是否将聚合设计的过大了。
哪怕在某个领域设计出来的聚合是正确的,我们有时候也会拆分它。原因很简单,性能问题。当聚合A中的实体EntityA存在大量数据的时候,我们访问聚合A不得不去加载它们,这样会让性能造成大量损失。哪怕建模的结果是正确的,但是我们还是会考虑折中的办法,将EntityA提升为一个单独的聚合供外界单独访问。
一致性
聚合中的所有对象都应该保持一致的变更,这是毫无疑问的。因此一个聚合在持久化的时候理应在一个事务中完成。但是当一个业务用例可能会操作多个聚合的时候,修改了聚合A的同时也更改了聚合B,这是一个很常见的操作,我们也必须保证多个聚合之间的一致性。这在单体应用中很容易实现,但是在分布式系统中我们不得不考虑最终一致性。有关分布式的相关信息将在后期 《分布式中的领域驱动设计》 系列中讲述。
总结
本次我们介绍了有关领域驱动设计中“聚合”的内容,我们知道了什么是聚合根,已经聚合根与实体之间的关系,以及怎么去考虑设计一个聚合根。在实际的项目中,其实聚合根是一个非常常见的领域对象,因为我们大量的业务逻辑和表达都是通过聚合根来完成操作的。回顾一下你现在正准备尝试或者已经在写的DDD项目,你使用聚合根了吗?你又是怎么来表达聚合根的?
下一期的文章中,是关于仓储的,它与聚合根其实有密不可分的关系。
以上是关于如何运用领域驱动设计 - 聚合的主要内容,如果未能解决你的问题,请参考以下文章