浅谈mysql数据库分库分表那些事-亿级数据存储方案
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅谈mysql数据库分库分表那些事-亿级数据存储方案相关的知识,希望对你有一定的参考价值。
参考技术A mysql分库分表一般有如下场景其中1,2相对较容易实现,本文重点讲讲水平拆表和水平拆库,以及基于mybatis插件方式实现水平拆分方案落地。
在 《聊一聊扩展字段设计》 一文中有讲解到基于KV水平存储扩展字段方案,这就是非常典型的可以水平分表的场景。主表和kv表是一对N关系,随着主表数据量增长,KV表最大N倍线性增长。
这里我们以分KV表水平拆分为场景
对于kv扩展字段查询,只会根据id + key 或者 id 为条件的方式查询,所以这里我们可以按照id 分片即可
分512张表(实际场景具体分多少表还得根据字段增加的频次而定)
分表后表名为kv_000 ~ kv_511
id % 512 = 1 .... 分到 kv_001,
id % 512 = 2 .... 分到 kv_002
依次类推!
水平分表相对比较容易,后面会讲到基于mybatis插件实现方案
场景:以下我们基于博客文章表分库场景来分析
目标:
表结构如下(节选部分字段):
按照user_id sharding
假如分1024个库,按照user_id % 1024 hash
user_id % 1024 = 1 分到db_001库
user_id % 1024 = 2 分到db_002库
依次类推
目前是2个节点,假如后期达到瓶颈,我们可以增加至4个节点
最多可以增加只1024个节点,性能线性增长
对于水平分表/分库后,非shardingKey查询首先得考虑到
基于mybatis分库分表,一般常用的一种是基于spring AOP方式, 另外一种基于mybatis插件。其实两种方式思路差不多。
为了比较直观解决这个问题,我分别在Executor 和StatementHandler阶段2个拦截器
实现动态数据源获取接口
测试结果如下
由此可知,我们需要在Executor阶段 切换数据源
对于分库:
原始sql:
目标sql:
其中定义了三个注解
@useMaster 是否强制读主
@shardingBy 分片标识
@DB 定义逻辑表名 库名以及分片策略
1)编写entity
Insert
select
以上顺利实现mysql分库,同样的道理实现同时分库分表也很容易实现。
此插件具体实现方案已开源: https://github.com/bytearch/mybatis-sharding
目录如下:
mysql分库分表,首先得找到瓶颈在哪里(IO or CPU),是分库还是分表,分多少?不能为了分库分表而拆分。
原则上是尽量先垂直拆分 后 水平拆分。
以上基于mybatis插件分库分表是一种实现思路,还有很多不完善的地方,
例如:
浅谈分库分表那些事儿
本文适合:需要从单库单表改造为多库多表的新手。
分库:从单个数据库拆分成多个数据库的过程,将数据散落在多个数据库中。
分表:从单张表拆分成多张表的过程,将数据散落在多张表内。
单库部署情况下,如果数据库宕机,那么故障影响就是100%,而且恢复可能耗时很长。
如果我们拆分成2个库,分别部署在不同的机器上,此时其中1个库宕机,那么故障影响就是50%,还有50%的数据可以继续服务。
如果我们拆分成4个库,分别部署在不同的机器上,此时其中1个库宕机,那么故障影响就是25%,还有75%的数据可以继续服务,恢复耗时也会很短。

在线渠道:每天产生3w笔聊天会话,假设,其中50%的会话会生成一笔离线工单,那么每天可生成 3w * 50% = 1.5w 笔工单;
离线渠道:假设离线渠道每天直接生成3w笔。
问题单需要:1.46亿/500w = 29.2 张表,我们就按32张表来切分;
操作日志需要 :32 * 10 = 320 张表,我们就按 32 * 16 = 512 张表来切分。
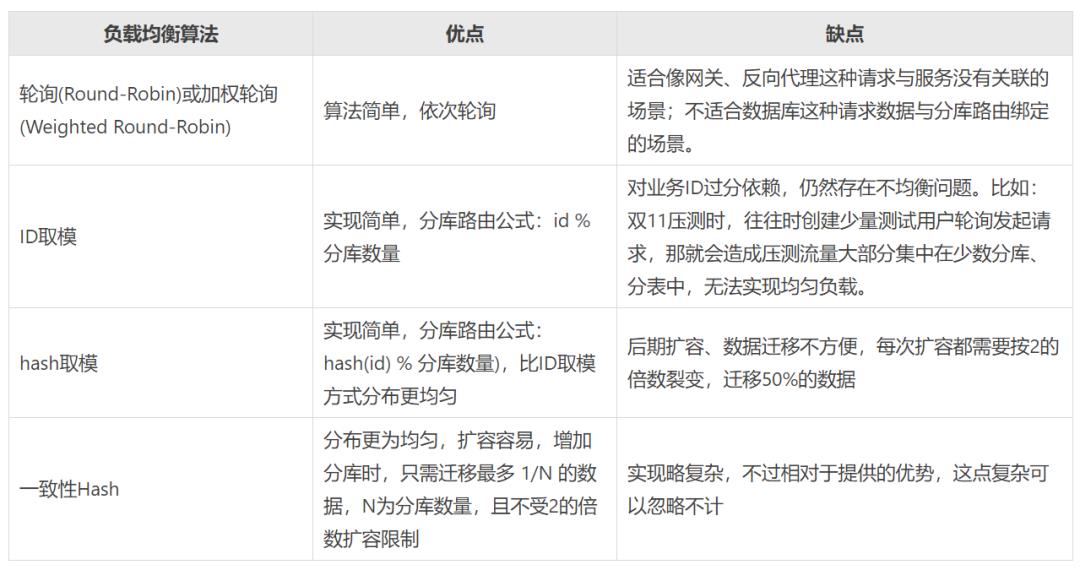
一致性Hash通过类似 hash(DB的IP) % 2^32 公式计算DB在Hash环的位置。如果DB数量较少,需要通过增加虚拟节点来解决Hash环偏斜问题,而且DB的位置可能会随着IP的变动而变化,尤其是在云环境下。
数据均匀分布到Hash环的问题,经过之前的判断,我们可以通过 Math.abs(buyerId.hashCode()) % 4096 计算定位到Hash环位置,那么剩下的问题就是让DB也均匀分布到这个Hash环上即可。由于我们都是使用阿里的TDDL中间件,只需要通过逻辑上的分库索引号定位DB,因此,我们把分库DB均分到这个Hash环上即可,如果是hash环有4096个环节,拆分4库的话,那么4个库分别位于第1、1025、2049、3073个节点上。分库的索引定位可通过 (Math.abs(buyerId.hashCode()) % 4096) / (4096 / DB_COUNT) 这个公式计算得出。
/*** 分库数量*/public static final int DB_COUNT = 4;/*** 获取数据库分库索引号** @param buyerId 会员ID* @return*/public static int indexDbByBuyerId(Long buyerId) {return (Math.abs(buyerId.hashCode()) % 4096) / (4096 / DB_COUNT);}
第X库、第Y次分配的ID段起始索引就是:
X * 步长 + (Y-1) * (库数量 * 步长)第X库、第Y次分配的ID段结束索引就是:
X * 步长 + (Y-1) * (库数量 * 步长) + (1000 -1)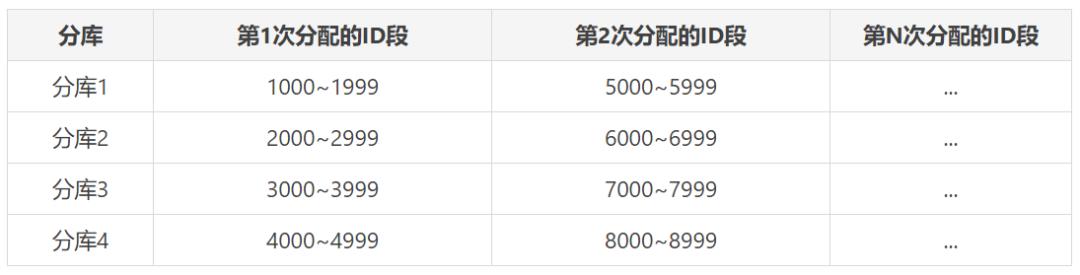
import lombok.Setter;import org.apache.commons.lang3.time.DateFormatUtils;/*** 问题单ID构建器* <p>* ID格式(18位):6位日期 + 2位版本号 + 2位库索引号 + 8位序列号* 示例:180903010300001111* 说明这个问题单是2018年9月3号生成的,采用的01版本的ID生成规则,数据存放在03库,最后8位00001111是生成的序列号ID。* 采用这种ID格式还有个好处就是每天都有1亿(8位)的序列号可用。* </p>*/public class ProblemOrdIdBuilder {public static final int DB_COUNT = 4;private static final String DATE_FORMATTER = "yyMMdd";private String version = "01";private long buyerId;private long timeInMills;private long seqNum;public Long build() {int dbIndex = indexDbByBuyerId(buyerId);StringBuilder pid = new StringBuilder(18).append(DateFormatUtils.format(timeInMills, DATE_FORMATTER)).append(version).append(String.format("%02d", dbIndex)).append(String.format("%08d", seqNum % 10000000));return Long.valueOf(pid.toString());}/*** 获取数据库分库索引号** @param buyerId 会员ID* @return*/public int indexDbByBuyerId(Long buyerId) {return (Math.abs(buyerId.hashCode()) % 4096) / (4096 / DB_COUNT);}}
优点:由应用服务器/数据库去管理事务,实现简单。
缺点:性能代价较高,尤其是涉及到分库数量较多时尤为明显。而且,还依赖于一些特定的应用服务器/数据库提供的分布式事务实现方案。
原理:大事化小,将多个大事务拆分成可由单个分库处理的小事务,由应用程序去控制这些小事务。
优点:性能良好,少了一个分布式事务协调处理层。
缺点:需要从应用程序自身上做事务控制的灵活设计。从业务应用上做处理,应该改造成本高。
以会员维度查询相关进度数据,包含会员问题数据,以及对应的问题处理操作日志/进度数据;
以会员视角提交相关凭证/反馈新情况等数据,或者是客服小二代会员提交这些数据。提交的数据也可能会决定问题是否解决(被完结)。
<beans><bean id="vtabroot" class="com.taobao.tddl.interact.rule.VirtualTableRoot" init-method="init"><property name="dbType" value="MYSQL" /><property name="defaultDbIndex" value="PROBLEM_0000_GROUP" /><property name="tableRules"><map><entry key="problem_ord" value-ref="problem_ord" /><entry key="problem_operate_log" value-ref="problem_operate_log" /></map></property></bean><!-- 问题(诉求)单表 --><bean id="problem_ord" class="com.taobao.tddl.interact.rule.TableRule"><property name="dbNamePattern" value="PROBLEM_{0000}_GROUP" /><property name="tbNamePattern" value="problem_ord_{0000}" /><property name="dbRuleArray" value="((Math.abs(#buyer_id,1,4#.hashCode()) % 4096).intdiv(1024))" /><property name="tbRuleArray"><list><value><![CDATA[def hashCode = Math.abs(#buyer_id,1,32#.hashCode());int dbIndex = ((hashCode % 4096).intdiv(1024)) as int;int tableCountPerDb = 32 / 4;int tableIndexStart = dbIndex * tableCountPerDb;int tableIndexOffset = (hashCode % tableCountPerDb) as int;int tableIndex = tableIndexStart + tableIndexOffset;return tableIndex;]]></value></list></property><property name="allowFullTableScan" value="false" /></bean><!-- 问题操作日志表 --><bean id="problem_operate_log" class="com.taobao.tddl.interact.rule.TableRule"><property name="dbNamePattern" value="PROBLEM_{0000}_GROUP" /><property name="tbNamePattern" value="problem_operate_log_{0000}" /><!-- 【#buyer_id,1,4#.hashCode()】 --><!-- buyer_id 代表分片字段;1代表分库步长;4代表一共4个分库,当执行全表扫描时会用到 --><property name="dbRuleArray" value="((Math.abs(#buyer_id,1,4#.hashCode()) % 4096).intdiv(1024))" /><property name="tbRuleArray"><list><value><![CDATA[def hashCode = Math.abs(#buyer_id,1,512#.hashCode());int dbIndex = ((hashCode % 4096).intdiv(1024)) as int;int tableCountPerDb = 512 / 4;int tableIndexStart = dbIndex * tableCountPerDb;int tableIndexOffset = (hashCode % tableCountPerDb) as int;int tableIndex = tableIndexStart + tableIndexOffset;return tableIndex;]]></value></list></property><property name="allowFullTableScan" value="false" /></bean></beans>
首先,要选择一个夜黑风高、四处无人的夜晚。寒风刺骨能让你清醒,四处无人,你好办事打劫偷数据,我们就挑了个凌晨4点寂静无人的时候做切换;如果可以,能临时关闭业务访问入口最好。
然后,在DTS上面新增一个全量的数据复制任务,把单库的数据复制到新的分库中(这个过程很快,千万级数据应该10分左右就能搞定)。
之后,切换TDDL配置(单库->分库),并重启应用,检查是否生效。
最后,开放业务访问入口,提供服务。
首先,同样需要选择一个夜黑风高的夜晚,来衬托你的帅气。
然后,通过DTS复制某个时间点前的数据,比如:今天前的历史数据。
之后,从单库切换到分库(最好是提前发布好应用、准备好配置),这样切换时只需要几分钟重启生效即可。在切换到分库前,联系DBA在切换期间停止老的单库读写。
最后,分库切换完成后,再通过DTS增量复制老的单库中今天凌晨之后产生的数据。
最后的最后,持续观察一段时间,如果没问题,老的单库就可以下线了。
// 在 Java 中System.out.println(5 / 3); // 结果 = 1// 在 Groovy 中println (5 / 3); // 结果 = 1.6666666667println (5.intdiv(3)); // 结果 = 1(Groovy整除正确用法)
招聘
欢迎加入 新零售技术事业群 CCO技术部,CCO技术部旨在建立更高的客户服务标准,让客户在阿里享受到最“爽”的服务,为阿里经济体提供一站式服务解决方案。通过我们的产品、数据智能、技术去提升阿里集团服务客户的能力,提升全网客户体验。同时我们的产品通过阿里云、钉钉侧,赋能企业和商家以提升服务数字化能力,用服务改变未来。我们期待你的加入!
社招岗位:Java技术专家/Java高级开发工程师/前端开发工程师
校招岗位:Java开发工程师、前端开发工程师、算法工程师、测试工程师
面向2022届应届毕业生(毕业时间:2021年11月~2022年10月)
欢迎联系我们:binga.wbg@alibaba-inc.com
参考资料
[1]https://baijiahao.baidu.com/s?id=1622441635115622194&wfr=spider&for=pc
[2]http://www.zsythink.net/archives/1182
[3]https://www.aliyun.com/product/dts
[4]https://docs.groovy-lang.org/latest/html/documentation/core-syntax.html#integer_division
[5]https://github.com/alibaba/tb_tddl
电子书免费下载
《Apache RocketMQ 源码解析》
《RocketMQ 技术内幕》作者推出,从RocketMQ ACL、RocketMQ消息轨迹、RocketMQ多副本等多个方面深入解析,带你彻底掌握Apache RocketMQ。
点击“阅读原文”,立即下载吧~
以上是关于浅谈mysql数据库分库分表那些事-亿级数据存储方案的主要内容,如果未能解决你的问题,请参考以下文章