YARN and SPARK
Posted HadoopSummit
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了YARN and SPARK相关的知识,希望对你有一定的参考价值。
演讲嘉宾:Jeff Markham, APAC CTO at Hortonworks
文字记录:王宇熙
本篇文章是Hortonworks的APAC CTO Jeff Harkham在China HADOOP Summit 2016北京站的演讲文字版。感谢王宇熙的整理。Jeff的英语发音字正腔圆,饱满纯正,语速已经放慢以适应国内听众。读者可以对照着本文来聆听Jeff的演讲音频,会有更好的效果。对于想练习英语听力的同学们,这也是个非常好的现实素材。限于微信文字不能超过2万字,只能将第一段后的文字全部转换为图片发上来。想看纯正文字版的,请戳阅读原文。
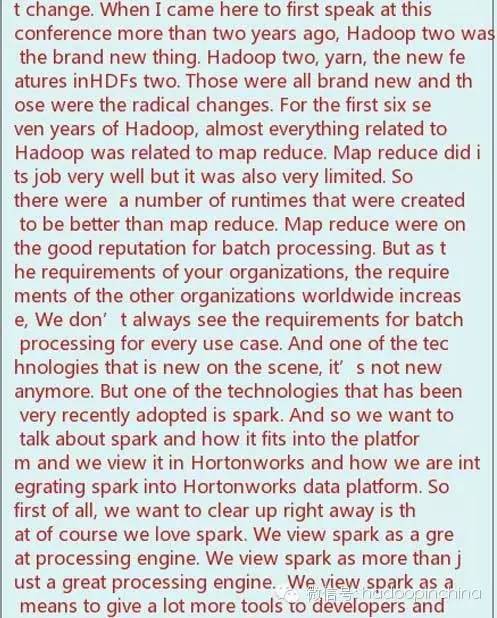
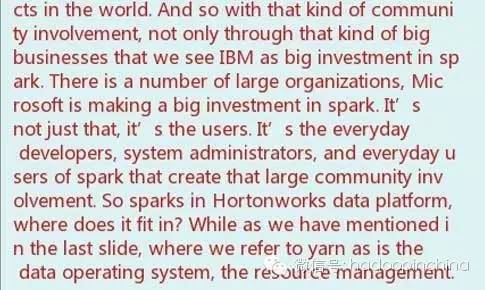
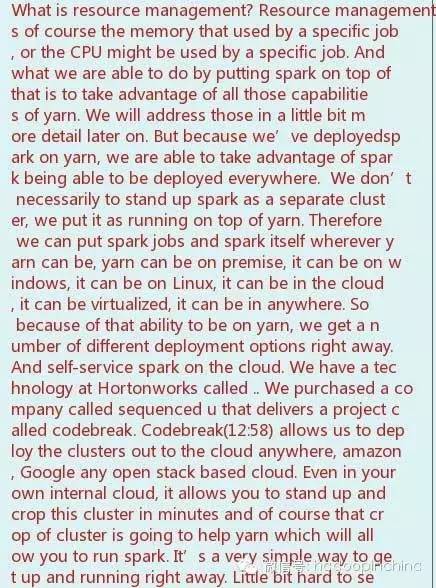
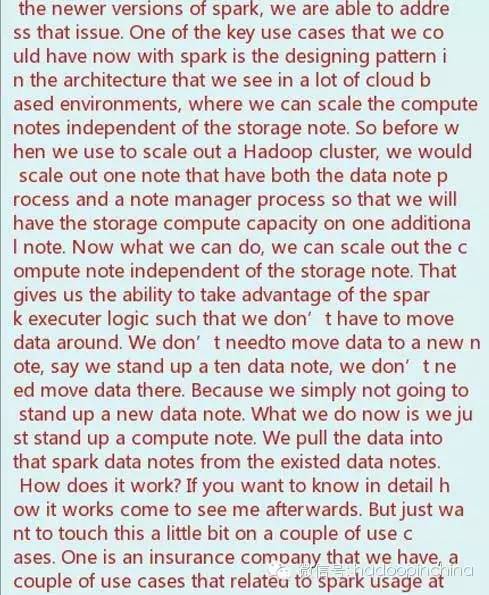
What an incredible turn on, it is really hard to believe two years ago I was in this room. It’s the first time I met the conferences’ organizers, right in this hotel, right in this room. I accepted the invite to come to this conference and speak. I thought I would be speaking infront of a handful of people. But there was a huge room of people just like this. So congratulations to the conference organizers for getting a turn out just like this. I wish I could speak Chinese, I wish I could have my QR code put on the screen just like everybody else, but I will hand my phone around later on so that you can scan my wechat code. Yes, this is a great conference to be here. I really appreciate your time to come here and talk about all the new things that is happening in hadoop. Whenever I come here, I do like to just kind of get an update on some of the new things that are going on the Hortonworks data platform. And of course I want to start out by saying that this year, this year is the ten year anniversary of Hadoop. It’s hard to believe Hadoop has been around for ten years. Ten years ago, a group of engineers of Yahoo decided to do so do something different, and do something disruptive. The storage they were using at that time, the










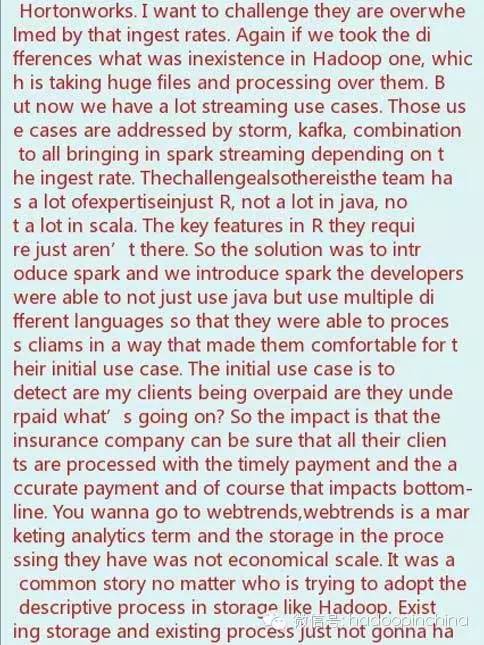

PPT和音频的文件下载,请猛戳“阅读原文”。
China HADOOP Summit 2016 上海站将于7月29日30日在上海市召开,现向业界召集演讲。有兴趣的朋友请联系我们。
征集但不限于下列内容:
大数据生态系统 大数据安全;存储;YARN;HDFS命名空间等;
大数据与工业4.0 电力、电网、能源、炼钢等;
大数据与电子商务 国内互联网主流电商企业应用与架构分享
金融大数据 银行、证券、个人征信、企业征信、量化投资与大数据
智慧城市与大数据 交通、医疗、安防、税务工商、旅游等
计算引擎与实时计算 Spark、Tez、Impala、Flink、Google Mesa、Storm、Fafka等
大数据即服务 Azure、AWS、阿里云、Docker/Container、Mesos等
NewSQL/NoSQL HBase/Druid;MongoDB/CouchDB;VoltDB;SequaioDB;Hana等
数据挖掘与图计算 R语言、GraphLab、GraphX、OrientDB等
数据仓库与可视化 EBay Kylin、LinkedIn Cubert、QlikView、Tableaue等
大数据创业与融投资 分享大数据领域的创业团队和故事
以上是关于YARN and SPARK的主要内容,如果未能解决你的问题,请参考以下文章
Spark两种提交方式Yarn-client and Yarn-cluster
Determine YARN and MapReduce Memory Configuration Settings