大数据平台实战(05)深入Spark Cluster集群模式YARN vs Mesos vs Standalone vs K8s
Posted 程序员交流互动平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据平台实战(05)深入Spark Cluster集群模式YARN vs Mesos vs Standalone vs K8s相关的知识,希望对你有一定的参考价值。
Spark可以以分布式集群架构模式运行,如果我们不熟Spark Cluster,这个时候需要集群管理器帮助我们管理Spark 集群。 集群管理器根据需要为所有工作节点提供资源,操作所有节点。负责管理和协调集群节点的程序一般叫做:Cluster Manager,集群管理器。
目前搭建Spark 集群,可以的选择包括Standalone,YARN,Mesos,K8s,这么多工具,在部署Spark集群时很难选择,哪些是最好的Apache Spark集群管理器?
互联网科技发展蓬勃兴起,人工智能时代来临,抓住下一个风口。为帮助那些往想互联网方向转行想学习,却因为时间不够,资源不足而放弃的人。我自己整理的一份最新的大数据进阶资料和高级开发教程,大数据学习群: 740041381就可以找到组织学习 欢迎进阶中和进想深入大数据的小伙伴加入接下来我们会详细介绍了每个集群管理器的功能,并详细介绍调度原理,HA(高可用性),安全性和监控机制。
Apache Spark是一个高性能分布式大数据处理引擎,可以以分布式集群模式运行。 Spark应用程序作为集群上的独立进程集运行,所有这些都由中央协调器协调。这个中央协调器可以连接4个不同的集群管理器:Spark的Standalone,Apache Mesos和YARN(Yet Another Resource Negotiator),还有最新的K8s。
在群集上以分布式模式运行Spark应用程序时,Spark使用主/从体系结构,中央协调器(coordinator也称为驱动程序)是应用程序中的主进程,运行创建SparkContext对象的代码。此Driver驱动程序进程负责将用户应用程序转换为称为Task任务的较小执行单元。然后,这些任务由执行程序执行,执行程序是运行各个任务的工作进程。如下图所示:
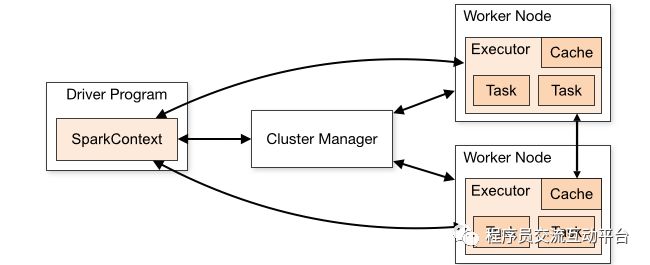
在群集中,有一个Master和任意数量的Worker。驱动程序可以在独立进程中运行,也可以在集群的工作程序中运行,从集群管理器请求执行程序。然后,它会在从集群管理器获取的执行程序上调度组成应用程序的任务。集群管理器负责在构成集群的主机上调度和分配资源。
Spark与底层集群管理器无关,可以独立运行,也可以结合集群管理器。集群管理器都有控制部署资源使用和其他功能的选项,并且都带有监控工具。
那么如何确定哪个是最好的集群管理器?要回答这个问题,我们将从介绍开始,然后详细对比每个集群管理器的扩展功能,节点管理,高可用性(HA),安全性和监控。
1、Spark集群管理器类型
Spark目前支持多个集群管理器,比较著名的,成熟的管理器方案是下面4个:
1)Standalone - Spark自带的简单集群管理器,可以轻松设置集群。
2)Apache Mesos - 一个通用的集群管理器,也可以运行Hadoop MapReduce和服务应用程序。
3)Hadoop YARN - Hadoop 2中新增的资源管理器。
4)Kubernetes - K8s,谷歌开源的容器管理工具,是个开源系统,用于自动化容器化应用程序的部署,扩展和管理。
也有第三方开源第三方项目扩展(Spark项目官方不支持),使用添Nomad作为集群管理器的尝试项目。
2、Spark集群调度原理
Spark应用程序作为集群上的独立进程集运行,由主程序中的SparkContext对象(称为驱动程序)协调。
Spar分布式集群模式运行,Java等开发的大数据程序使用SparkContext对象连接到几种集群管理器(Standalone,Mesos或YARN),管理器负责调度分配资源。 连接后,Spark会在集群中的节点上获取executors执行程序,这些executors执行程序是为应用程序运行计算和存储数据的进程。 接下来,它将我们编写的Java大叔应用程序代码(传递给SparkContext的JAR或Python文件定义)发送给executors执行程序。 最后,SparkContext定义Job概念,并且将Job分解的大数据计算任务tasks发送给executors执行程序,一个集群多个节点,一个节点至少有一个executors,一个executors可以有多个Task。
3、Spark 4个集群管理
Spark现在支持4种集群管理器:Spark的Standalone,Apache Mesos和YARN(Yet Another Resource Negotiator),K8s。
1)Spark Standalone集群管理器是一个简单的集群管理器,可作为Spark发行版的一部分。它具有主服务器的HA,对工作人员故障具有弹性,具有管理每个应用程序资源的功能,并且可以与现有Hadoop部署一起运行并访问HDFS(Hadoop分布式文件系统)数据。该分发包括脚本,以便在Amazon EC2上本地或在云中轻松部署。它可以在Linux,Windows或Mac OSX上运行。
2)Apache Mesos是开源分布式资源管理框架,支持Master主服务器和Slave从服务器的HA,可以管理分布式应用程序的资源,并且支持Docker容器。。Mesos最初是由加州大学伯克利分校的AMPLab开发的,后在Twitter得到广泛使用。它可以运行Spark作业,Hadoop MapReduce或任何其他服务应用程序。它有适用于Java,Python和C ++的API。它可以在Linux或Mac OSX上运行。
3)Hadoop YARN,作业调度和集群资源管理分布式计算框架,具有Master和Slave高可用HA特性,支持非安全模式Docker容器,Linux和Windows容器executors安全模式,和可插拔调度。可以在Linux和Windows系统上运行。
4)Kubernetes(K8s)是一个谷歌开源资源管理系统,用于Dockers自动化容器化应用程序的部署,扩展和管理。 它将构成应用程序的容器分组为逻辑单元,以便于管理和发现。 Kubernetes拥有15年在Google运行生产工作负载的经验,并结合了社区中的最佳创意和实践。
4、Spark集群安全性
Spark的安全性同样非常重要,主要是身份验证和数据加密问题。怎么保持大数据的安全,和如何保证执行者的权限正确。几种不同的集群模式,支持的授权和安全体系也存在差异,有些借助第三方安全框架如Kerberos来实现集群安全。
4.1)Spark独立模式支持通过所有集群管理器的共享密钥进行身份验证。独立管理器要求用户使用共享密钥配置每个Spark节点。可以使用SSL为通信协议加密数据。数据块传输支持SASL加密。其他选项也可用于加密数据。可以通过访问控制列表ACL控制对Web UI中的Spark应用程序的访问。
4.2)Mesos也可以为与Spark集群提供身份验证。这包括向Master主服务器注册的Slave从服务器,提交给集群的框架(即应用程序),以及使用HTTP等端点的运算器。可以使集群中的每一个实体都能够使用身份验证。 Mesos的默认验证模块Cyrus SASL,可以替换为自定义安全模块。ACL访问控制列表用于授权访问Mesos中的服务。默认情况下,Mesos中模块之间的通信未加密。我们可以启用SSL / TLS来加密此通信。 Mesos WebUI也支持HTTPS安全协议。
4.3)Hadoop YARN的安全机制依赖于第三方标准,具有身份验证,服务级别授权SLA,Web控制台身份验证和数据机密性的安全性。 Hadoop身份验证使用Kerberos验证,Kerberos对每个用户和服务进行了身份验证。SLA服务级别授权可确保使用Hadoop服务的客户端有权限使用它们。可以通过访问控制列表ACL精确控制对Hadoop服务的访问。此外,客户端和服务之间的数据通信可以使用SSL加密,使用HTTPS在Web控制台和客户端之间传输数据。这种方式也是互联网常见的数据加密方式
4.4)Kubernetes可以调度Apache Spark资源,并且为Spark提供一个安全可靠的运行隔离环境,大数据在多用户之间传输和存储的安全性非常重要,Kubernetes Secrets可用于为Spark应用程序提供访问安全服务的凭据。Kubernetes和Spark可以利用Kerberos这样的认证体系,进行HDFS和Spark的Job执行的权限控制和授权,这是Spark on K8s试解决的问题。Spark中的安全性默认为OFF。 很容易受到默认攻击。 在运行Spark之前,生产环境建议启用安全。
集群安全比较复杂,默认我们使用第一种方式,相对简单,容易配置实现。
5、Spark集群高可用
分布式系统另外一个重要的问题就是高可用HA,分布式系统协调复杂,安全性重要,但是如果某个节点宕机出错,可能会影响整个集群的运行,Spark集群的管理器也需要解决HA高可用问题。
5.1)Spark独立集群管理器支持HA,支持使用ZooKeeper仲裁模式,可以把备用主服务器自动恢复主服务器。 它还支持使用文件系统进行手动恢复。 无论是否启用了Master恢复,Spark群集都对Worker失败具有弹性。
5.2)Apache Mesos集群管理器,同样使用Apache ZooKeeper自动恢复Master主服务器。 能够恢复Master。 在故障转移的情况下,当前正在执行的任务将继续执行。
5.3)Apache Hadoop YARN支持使用命令行实用程序进行手动恢复,并支持通过ResourceManager中嵌入的基于Zookeeper的ActiveStandbyElector进行自动恢复。 因此,与Mesos和Spark独立集群管理器不同,不需要运行单独的ZooKeeper故障转移控制器。 ZooKeeper仅用于记录ResourceManagers的状态。
5.4)Spark可以在Kubernetes管理的集群上运行。 此功能使用已添加到Spark的本机Kubernetes调度程序。Kubernetes调度程序目前是实验性的。 在未来的版本中,可能会出现围绕配置,容器映像和入口点的行为变化。
6、Spark集群监控
分布式集群监控,默认Spark提供了监控工具,Web网页方式。但是其他的集群管理器应该也提供了自己的监控面板,比如Mesos和K8s。6.1)每个Apache Spark应用程序都有一个Web UI来监视应用程序。 Web UI显示有关在应用程序,执行程序和存储使用中运行的任务的信息。此外,Spark的独立集群管理器具有Web UI,可以查看集群和作业统计信息以及每个作业的详细日志输出。如果应用程序在其生命周期内记录了事件,则Spark Web UI将在应用程序存在后自动重建应用程序的UI。如果Spark在Mesos或YARN上运行,则可以在应用程序通过Spark的历史记录服务器退出后重建UI。Spark每个驱动程序都有一个Web UI,通常在端口4040上,显示有关运行任务,执行程序和存储使用情况的信息。 只需在Web浏览器中访问http:// :4040即可访问此UI。 监控指南还介绍了其他监控选项。
6.2)Apache Mesos为通过URL访问的主节点和从节点提供了许多指标。这些指标包括,例如,分配的CPU的百分比和数量,使用的总内存,可用内存的百分比,总磁盘空间,分配的磁盘空间,选定的主站,主站的正常运行时间,从站注册,连接的从站等。此外,支持每个容器网络监视和隔离。
6.3)Hadoop YARN具有ResourceManager和NodeManager的Web UI。 ResourceManager UI为集群提供度量,而NodeManager为每个节点以及节点上运行的应用程序和容器提供信息。
6.4)Kubernetes提供了2个主要的监控模块cAdvisor和Heapster 。监控agent, 在每个Kubernetes Node上都会运行cAdvisor 。cadvisor 会收集本机以及容器的监控数据(例如CPU、 memory、filesystem 、network statistics)。Heapster收集所有Kubernetes Node信息,然后汇总数据,然后可以导到第三方工具(如Influxdb)。Heapster 可以以Pod的方式运行在Kubernetes平台里,也可以单独运行以standalone的方式。
7、结论
Apache Spark与底层集群管理器无关,因此选择使用哪个管理器取决于您的目标。在上面的部分中,我们讨论了Spark的独立集群管理器,Apache Mesos、Hadoop YARN、K8s的几个方面,包括:调度、HA高可用性、安全、监控。
所有4个集群管理器都提供各种调度功能,但Mesos提供了最好的粒度控制选择。
所有4个集群管理器都提供高可用性,但Spark独立、Hadoop YARN和K8s不需要运行单独的ZooKeeper故障转移控制器。
所有Spark集群管理器都提供安全保障。 Apache Mesos支持可插拔架构作为其安全模块,使用Cyrus SASL的默认模块。Spark独立集群管理器使用共享密钥,Hadoop YARN使用Kerberos,K8s。这3个都使用SSL进行数据加密。
对比来看,默认的Apache Standalone Cluster Manager最简单,是最容易配置的,如果集群不需要复杂的VM虚拟化设置,不需要安装K8S,自带的集群管理器已经并提供了一套相当完整的功能。因此,如果搭建Spark大数据集群,这是最快的方式。其次可以推荐使用Mesos一起搭建。
以上是关于大数据平台实战(05)深入Spark Cluster集群模式YARN vs Mesos vs Standalone vs K8s的主要内容,如果未能解决你的问题,请参考以下文章
[Spark/Scala] 180414|大数据实战培训 Spark大型项目实战:电商用户行为分析大数据平台 大数据视频教程