04 | 微服务反模式与陷阱:直达式报告反模式
Posted ACE1985
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了04 | 微服务反模式与陷阱:直达式报告反模式相关的知识,希望对你有一定的参考价值。
译者简介:ASCE1885,《Android 高级进阶》 和 《Android 高级进阶(源码剖析篇)》作者。
本文首发于Source Code Chain开发者社区,欢迎使用我的专属邀请链接加入一起交流。

本系列是对《Microservices AntiPatterns and Pitfalls》一书的翻译,仅用于学习交流使用,谢谢!
在微服务架构风格中,服务和相关的数据是包含在边界上下文中的,也就是服务相关的数据通常会迁移到独立的数据库(或 schema)中。虽然这对服务来说效果很好,但它对微服务体系架构中报告方面造成严重的破坏。
微服务体系架构中主要有四种技术可以用来处理报告,它们分别是数据库拉模型,HTTP 拉模型,批量拉模型和基于事件的推模型。前面三种技术都是从每个微服务的数据库中拉取数据,因此,我们把这种反模式命名为直达式报告反模式。由于前三种模型代表了与这个反模式相关的问题,所以我们先来了解这些技术以及为什么它们会给你带来麻烦。
微服务中报告伴随的问题
报告有两方面的问题:如何及时获取报表数据,同时保持服务和相关数据的边界上下文。要记住一点,微服务中的边界上下文包含服务本身和它相关的数据,而且维持它是至关重要的。
通常微服务体系架构中处理报告的方式之一是使用所谓的数据库拉模型,它通过一个报告服务(或者报告请求)直接从微服务的数据库中拉取数据,这种方式如图 4-1 所示。
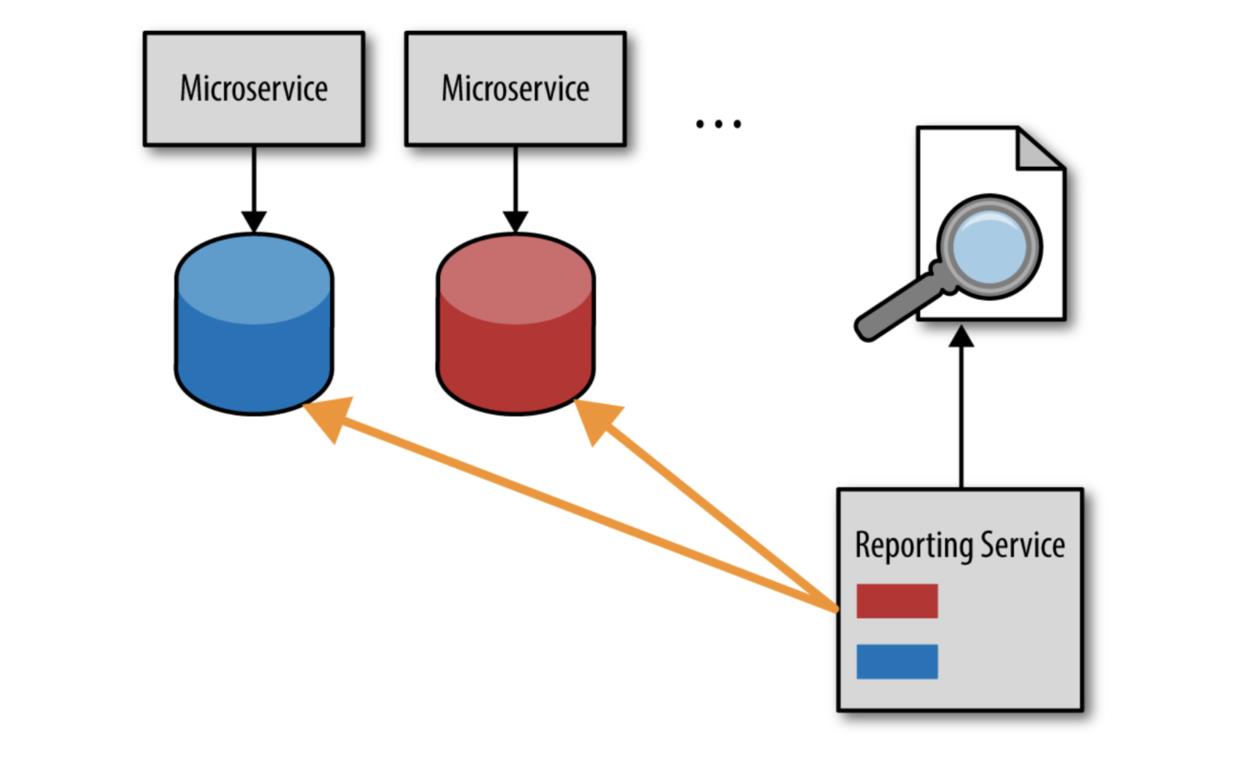
从逻辑上讲,获取及时数据最快也是最简单的方法就是直接访问它。虽然初看起来这是个好方法,但它会导致各个服务与报告服务之间产生显著的依赖关系。这是共享数据库集成风格的一种典型实现,它通过共享数据库将应用耦合在一起。这意味着服务不再拥有它们自己的数据。任何对服务数据库 schema 的更改或者数据库重构都必须同时修改报告服务,从而打破服务和数据之间重要的边界上下文。
避免服务间数据耦合问题的方法是使用另外一种被称为 HTTP 拉模型的技术。在这种模型中,不是直接访问每个服务的数据库,而是通过报告服务对每个服务发起 HTTP 请求来获取数据的。这个模型如图 4-2 所示。

虽然这种模型保留了服务间的边界上下文,但不幸的是它太慢,特别是对于复杂的报告请求而言。此外,取决于具体所请求的报告,可能存在某个报告的数据量对于普通的 HTTP 请求而言太大。
为了解决 HTTP 拉模型存在的问题,我们有第三个选择,就是批量拉模型,如图 4-3 所示。请注意,这个模型使用一个独立的数据库或者数据仓库来存储经过聚合和压缩的报表数据。报告数据库通常通过在晚上运行的批处理任务来进行数据填充,这个批处理任务会从各个微服务的数据库中拉取所有更新的报告数据,经过聚合和压缩,将数据插入到报告数据库或者数据仓库中。
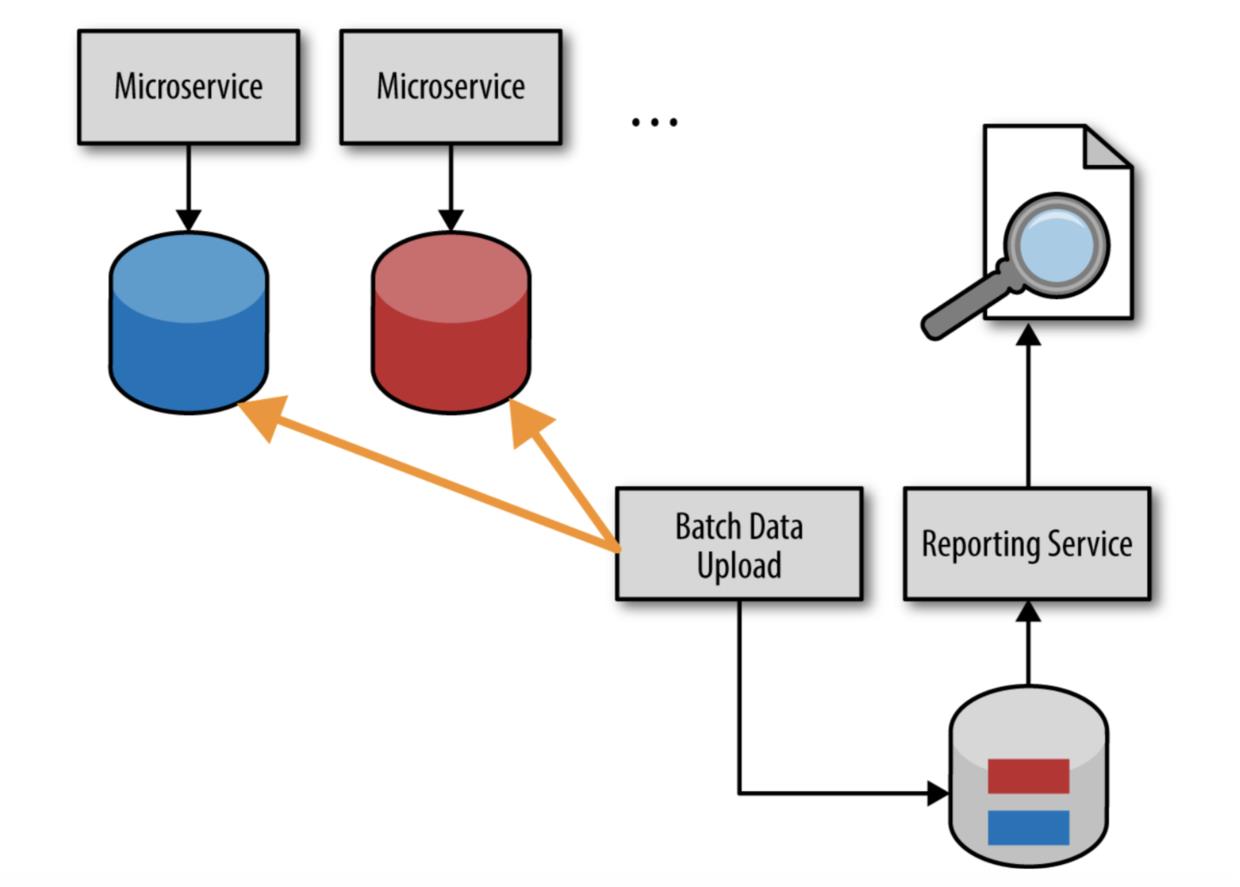
批处理模型和数据库拉模型有相同的问题,它们都实现了共享数据库集成风格,因此打破了服务间的边界上下文。如果服务的数据库 schema 改变了,那么批处理任务的数据上传过程也要作相应的修改。
异步事件推模型
避免直达式报告反模式的解决方案是使用所谓的基于事件的推模型。 Sam Newman 在他的《构建微服务》一书中,把这种技术称为数据泵。这种模型如图 4-4 所示,它依赖于异步事件处理来确保报告数据库能够及时获取正确的数据。
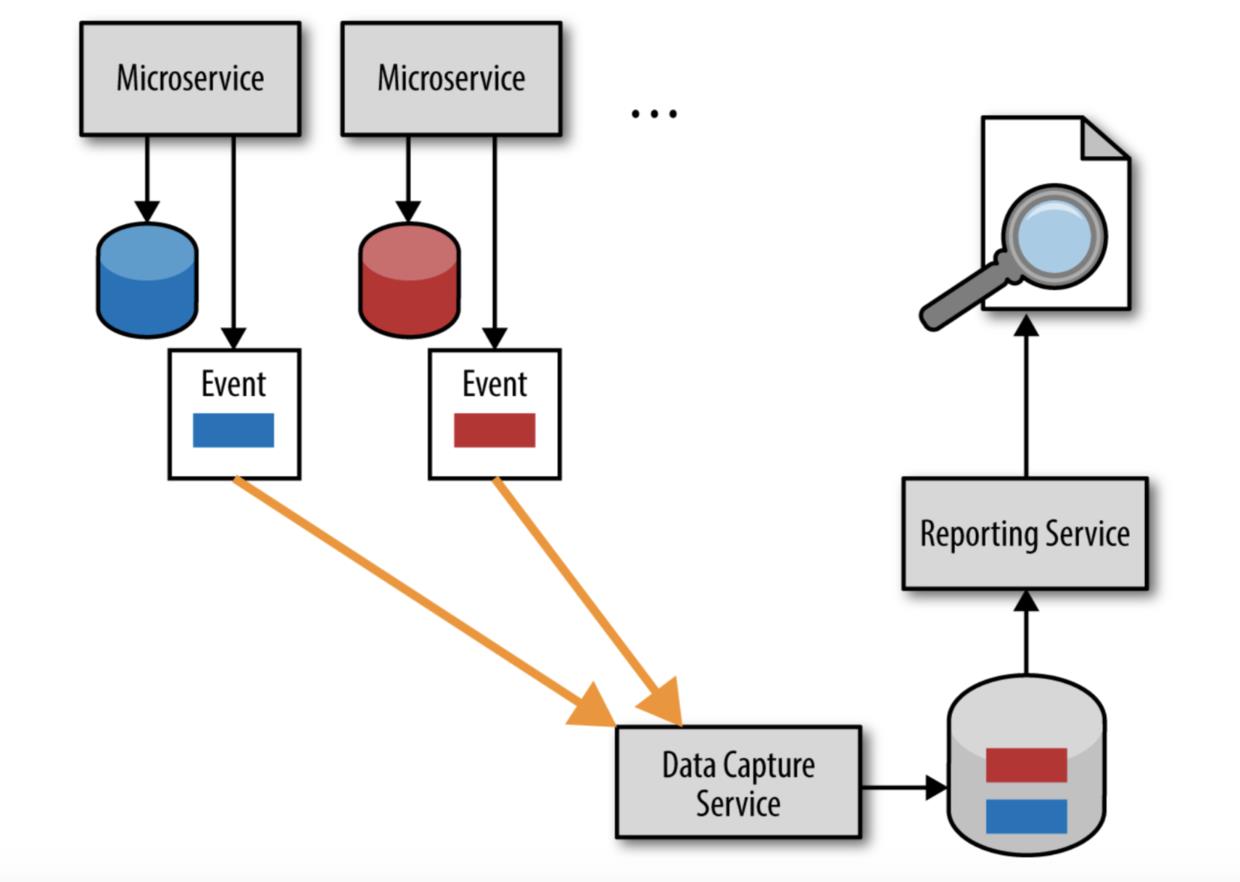
虽然事实上基于事件的推模型相对而言实现复杂,但它在保留每个服务之间的边界上下文的同时,也保证了数据的合理及时性。与批量拉模型类似,这个模型中报告服务也拥有独立的数据库。然而,与批量拉模型不同,每个微服务会异步的将值得关注的数据(也就是报告服务所需要的数据)的更新作为一个独立事件发送给数据捕获服务,然后数据经过数据捕获服务的聚合压缩,最终更新到报告数据库中。
基于事件的推模型要求每个微服务和数据捕获服务之间达成一个契约,基于这个契约来实现数据的异步发送,但该契约又是和数据库 schema 分开的,由服务所拥有。然而,这些服务间存在某种程度的耦合,因为每个服务必须知道何时发送需要用于报告目的的信息。
在图 4-5 中,我们可以看到数据库拉模型最大限度的提高了数据的及时性,但打破了服务间的边界上下文。而 HTTP 拉模型保留了边界上下文,但存在及时性和数据量相关的问题。批量拉模型是四种模型中最不希望选用的模型,因为它既不能保留边界上下文,又不能保证数据的及时性。相比之下,只有基于事件的推模型既保留了服务间的边界上下文,又保证了报告数据获取的及时性。

以上是关于04 | 微服务反模式与陷阱:直达式报告反模式的主要内容,如果未能解决你的问题,请参考以下文章