01 | 微服务反模式与陷阱:数据驱动架构迁移
Posted ACE1985
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了01 | 微服务反模式与陷阱:数据驱动架构迁移相关的知识,希望对你有一定的参考价值。
译者简介:ASCE1885, 《Android 高级进阶》作者。
本文首发于Source Code Chain开发者社区,欢迎使用我的专属邀请链接加入一起交流。

本系列是对《Microservices AntiPatterns and Pitfalls》一书的翻译,仅用于交流使用,谢谢!
微服务是用来创建大量小的,分布式且目的单一的服务的技术,每个服务拥有自己的数据。这种服务和数据耦合的方式符合边界上下文的设计理念,同时也是一种无共享的架构,其中每个服务及其相关的数据与其他所有服务区分并完全独立开来,只对外暴露一个定义良好的接口(契约)。边界上下文使得服务的开发和测试变得快速简单,最少化服务间的部署依赖。
数据驱动架构迁移反模式主要发生在将应用从单体架构迁移到微服务架构的场景下。之所以说它是反模式是因为一开始大家可能认为在创建微服务时把服务功能和相关的数据拆分出来是个好主意,但正如你将在本文学到的,这会让你走上一条高风险,超额成本和更多迁移工作的道路。
微服务拆分有两个主要目标,第一是把单体应用按照功能拆分为小的,单一目的的多个服务;第二是把单体应用的数据拆分到各个微服务所拥有的独立数据库中(或者独立的 schemas 中)。图 1-1 展示的是典型的将单体应用的服务代码和相关的数据在架构迁移时同时拆分的场景。
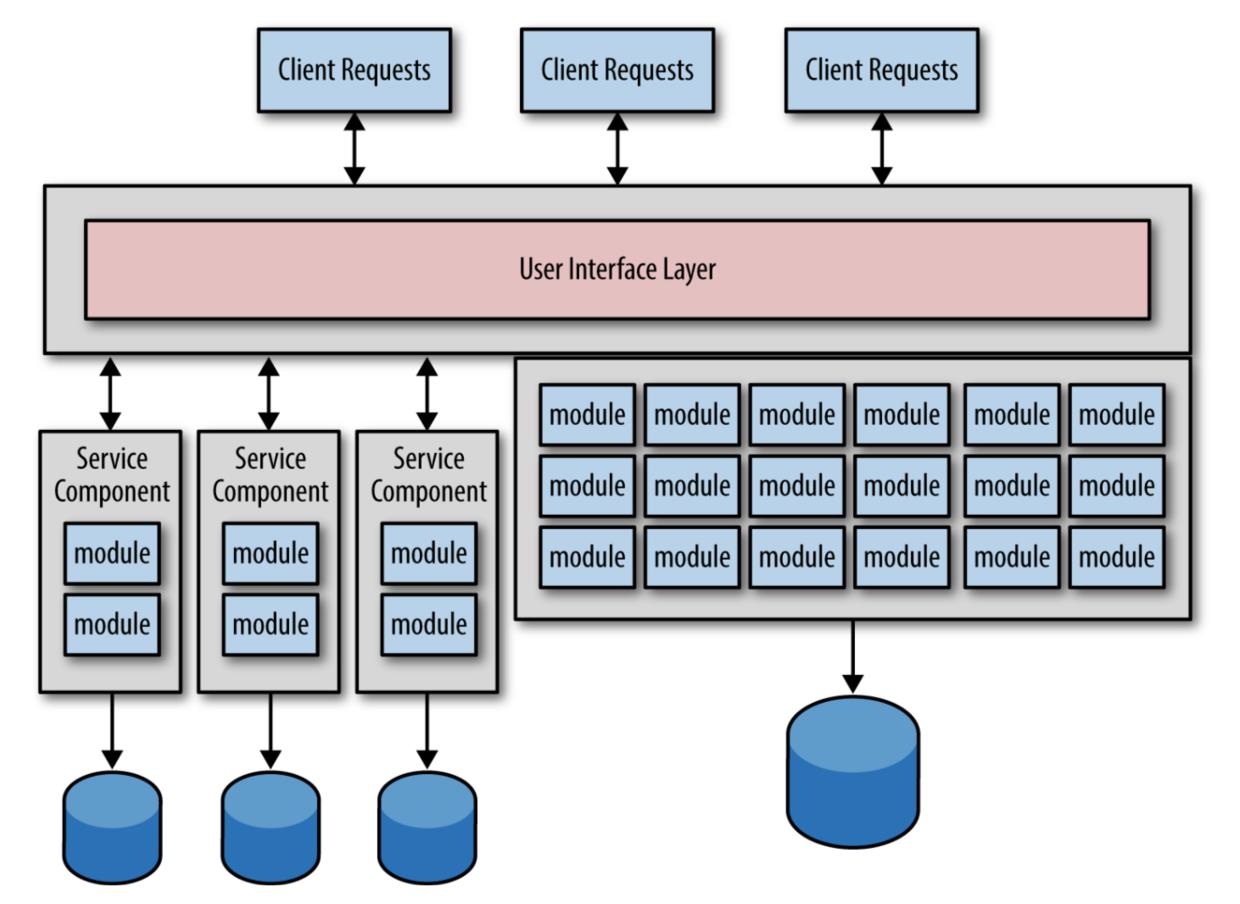
可以看到,从单体应用中拆分出了三个微服务,它们拥有自己独立的数据库。这是很自然的一个迁移过程,因为我们是按照边界上下文的理念来创建每个服务和相关数据的。然而,这种常见的做法将会把你带入数据驱动的架构迁移反模式。
频繁的数据迁移
这种类型架构迁移的主要问题在于一开始你很难把握好每个服务的拆分粒度。请记住,开始的时候以粗粒度的方式拆分服务是个好的方法,然后在以后随着对拆分出来的服务理解越来越深,可以继续拆分,你可能需要在实践中不断调整服务的拆分粒度。如图 1-1 所示,我们来看下最左边的服务,如果随着对服务了解越深,我们发现当初的拆分粒度太粗,那么需要进一步拆分成更小的服务。相反,左边剩下的两个服务当初的拆分粒度太细,那么需要把这两个服务统一成一个。在这两种情况下,你都面临两种迁移的工作,一是服务功能的迁移,一是数据库的迁移。如图 1-2 所示。
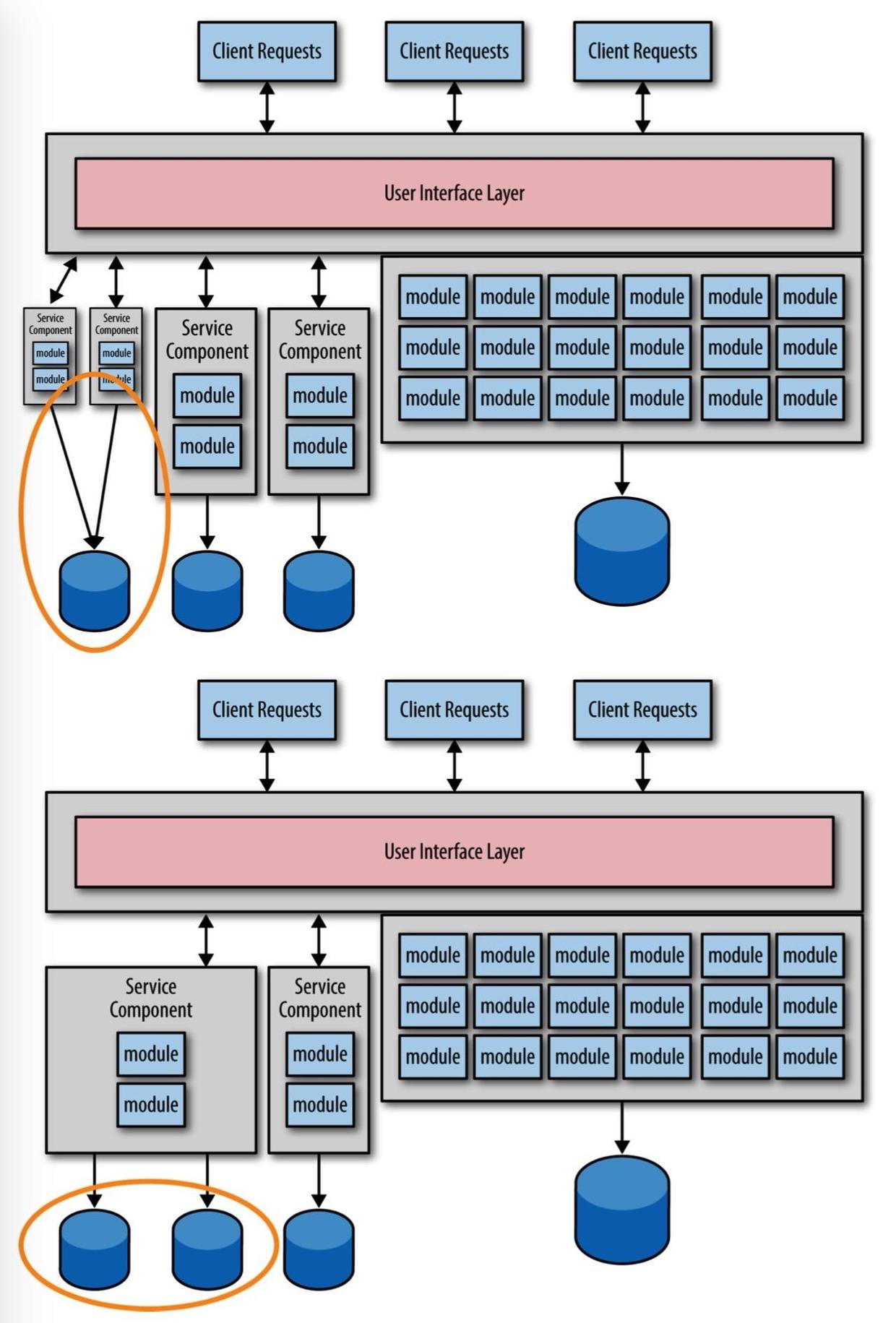
我的好朋友和同事 O’Reilly 作者 Alan Beaulieu(Learning SQL)曾经跟我说:“数据是企业资产,而不是应用资产”。考虑到 Alan 的说法,我们需要对持续的数据迁移所涉及的风险有所评估,并引起足够的重视。相比代码的迁移,数据迁移要复杂而且容易出错得多,最理想的情况是你只需要为每个服务迁移一次数据。了解数据迁移涉及的风险和“数据高于功能”的重要性是避免这种反模式的第一步。
优先迁移功能,最后迁移数据
避免本文所说的反模式的最主要技巧是先迁移服务的功能,以后再考虑服务间的边界上下文和涉及的数据。随着你对拆分出来的服务了解的越多,你很可能会需要对服务的拆分粒度作调整,例如统一多个服务,或者进一步拆分服务。当你确信服务已经按照正确的粒度拆分后,才进行数据的迁移,从而构建出更合适的服务和数据的边界上下文。
这个技巧如图 1-3 所示。可以看到开始时虽然三个服务都被拆分出来,但数据库还是连接到原来单体应用的数据库。对于临时解决方案来说这是很非常好的,因为这样你可以对服务是如何使用的以及每个服务能够更好对处理哪种请求有更多的了解。
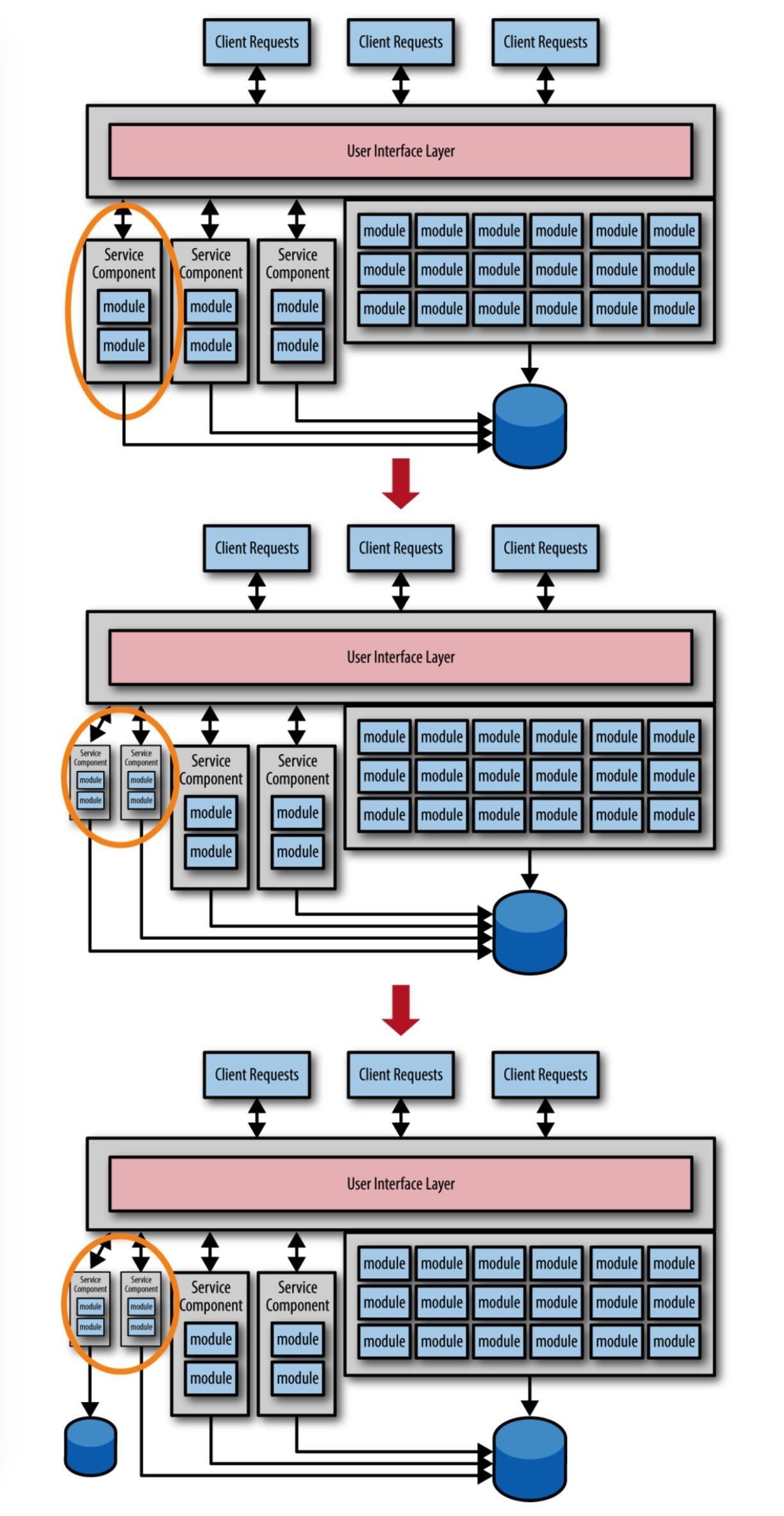
在图 1-3 中,可以看到,最左边的服务在第一次拆分后,使用过程中发现拆分的粒度太粗,随之被继续拆分为两个更小的服务。现在拆分粒度符合实际业务场景,服务相关的数据也就可以继续进行迁移,从而构建出更合适的服务和数据的边界上下文。这个技巧避免了昂贵和重复的数据迁移,并使得在需要时更容易调整服务的粒度。鉴于我们无法知道一个服务的功能拆分出来后,要等多长时间才可以进行数据迁移,因此需要知道这种技巧的缺点是导致一个较差的边界上下文。在服务拆分后和相关数据最终迁移前这段时间内,服务之间是存在数据耦合的。这也意味着当数据库模式发生改变时,所有使用到这个模式的服务要进行变更控制和发布时间点的协调,这往往是引入微服务时所希望避免的。然而,这个权衡很有价值,它通过避免多次昂贵的数据库迁移降低了服务拆分的风险。
以上是关于01 | 微服务反模式与陷阱:数据驱动架构迁移的主要内容,如果未能解决你的问题,请参考以下文章