大数据技术架构(组件)——Hive:环境准备1
Posted mylife512
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据技术架构(组件)——Hive:环境准备1相关的知识,希望对你有一定的参考价值。
1.0.1、环境准备
1.0.1.0、maven安装
1.0.1.0.1、下载软件包
1.0.1.0.2、配置环境变量
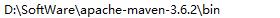
1.0.1.0.3、调整maven仓库
打开$MAVEN_HOME/conf/settings.xml文件,调整maven仓库地址以及镜像地址
<settings xmIns="http://maven.apache.org/SETTINGS/1.0.0"
xmIns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0
https://maven.apache.org/xsd/settings-1.0.0.xsd">
<localRepository>你自己的路径</localRepository>
<mirrors>
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorof>
</mirror>
</mirrors>
</settings>1.0.1.1、cywin安装
该软件安装主要是为了支持windows编译源码涉及到的基础环境包
1.0.1.1.1、下载软件包
1.0.1.1.2、安装相关编译包
需要安装cywin,gcc+相关的编译包
binutils
gcc
gcc-mingw
gdb1.0.1.2、源码包下载
https://downloads.apache.org/hive/hive-2.3.9/
1.0.1.3、JDK安装
1.0.1.3.1、下载软件包
1.0.1.3.2、配置环境变量
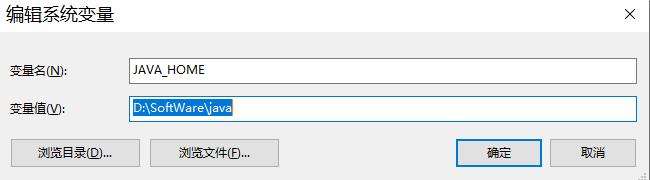
1.0.1.3.2.1、创建JAVA_HOME系统变量
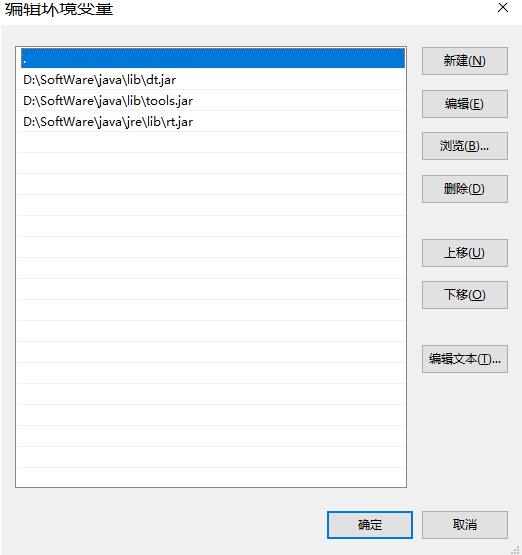
1.0.1.3.2.2、创建CLASSPATH系统变量

1.0.1.3.2.3、追加到Path变量中

1.0.1.4、Hadoop安装
1.0.1.4.1、下载软件包
1.0.1.4.2、配置环境变量
创建HADOOP_HOME系统变量,然后将该变量追加到Path全局变量中


1.0.1.4.3、编辑配置文件
注意:下载的软件包中可能不包含下列的文件,但提供了template文件,直接重命名即可。由于该篇是属于学习自用,所以只需要配置基础核心信息即可。下列文件位于$HADOOP_HOME/etc/hadoop目录下。
1.0.1.4.3.1、修改core-site.xml文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>1.0.1.4.3.2、修改yarn-site.xml文件
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>1.0.1.4.3.3、修改mapred-site.xml文件
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>1.0.1.4.4、初始化启动
# 首先初始化namenode,打开cmd执行下面的命令
$HADOOP_HOME/bin> hadoop namenode -format# 当初始化完成后,启动hadoop
$HADOOP_HOME/sbin> start-all.cmd
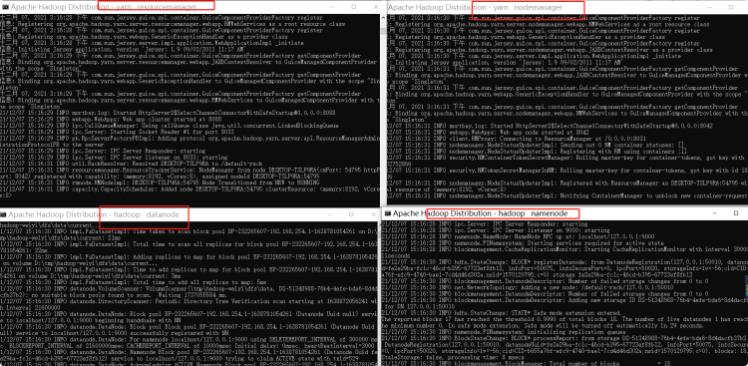
当以下进程都启动成功后,hadoop基本环境也算是搭建成功了!
以上是关于大数据技术架构(组件)——Hive:环境准备1的主要内容,如果未能解决你的问题,请参考以下文章