3秒复制任何人的嗓音!微软音频版DALL·E细思极恐,连环境背景音也能模仿
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了3秒复制任何人的嗓音!微软音频版DALL·E细思极恐,连环境背景音也能模仿相关的知识,希望对你有一定的参考价值。
萧箫 发自 凹非寺
量子位 | 公众号 QbitAI
只需3秒钟,一个根本没听过你说话的AI,就能完美模仿出你的声音。
例如这是你的一小句聊天语音:
这是AI根据它模仿你说话的音色:
是不是细思极恐?
这是微软最新AI成果——语音合成模型VALL·E,只需3秒语音,就能随意复制任何人的声音。
它脱胎于DALL·E,但专攻音频领域,语音合成效果在网上放出后火了:
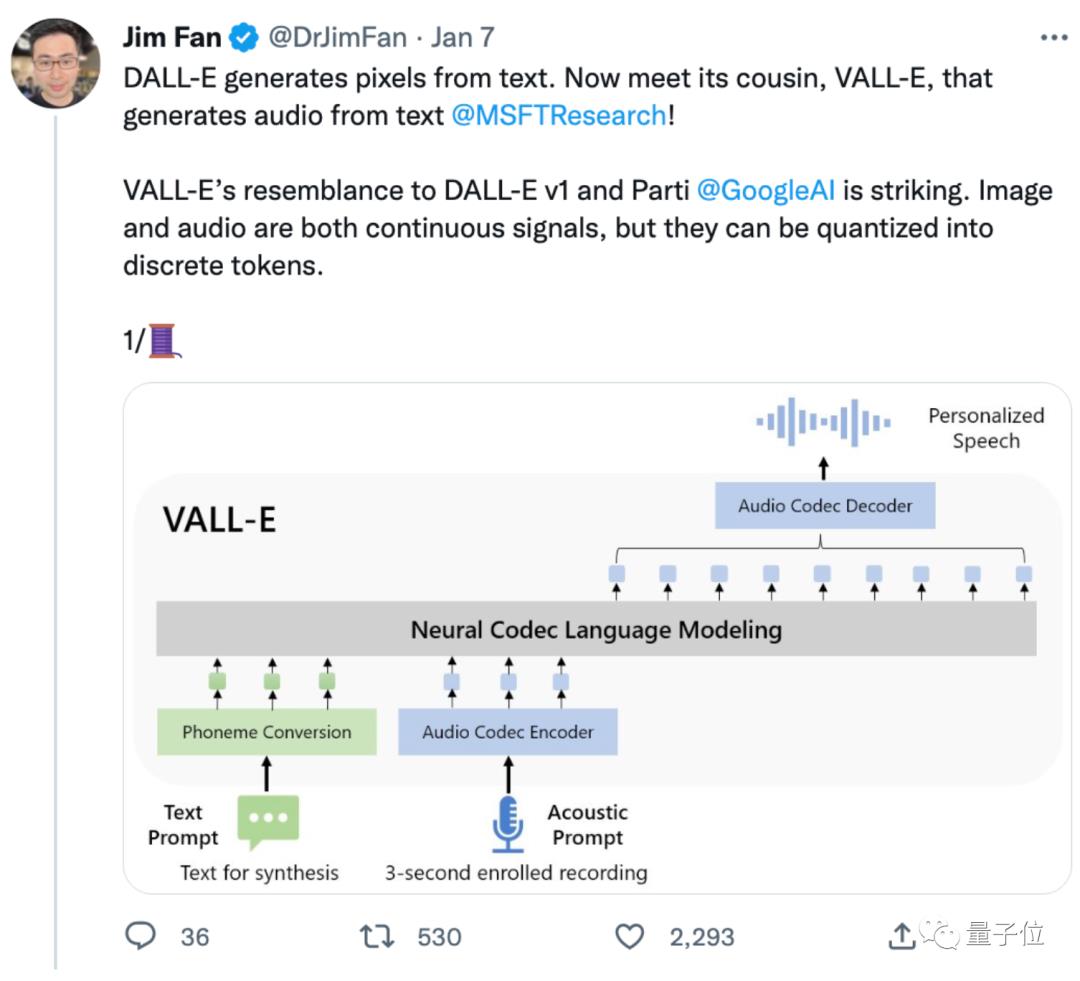
有网友表示,要是将VALL·E和ChatGPT结合起来,效果简直爆炸:
看来与GPT-4在Zoom里聊天的日子不远了。

还有网友调侃,(继AI搞定作家、画家之后)下一个就是配音演员了。

所以VALL·E究竟怎么做到3秒钟模仿“没听过”的声音?
用语言模型来分析音频
基于AI“没听过”的声音合成语音,即零样本学习。
语音合成趋于成熟,但之前零样本语音合成效果并不好。
主流语音合成方案基本是预训练+微调模式,如果用到零样本场景下,会导致生成语音相似度和自然度很差。
基于此,VALL·E横空出世,相比主流语音模型提出了不太一样的思路。

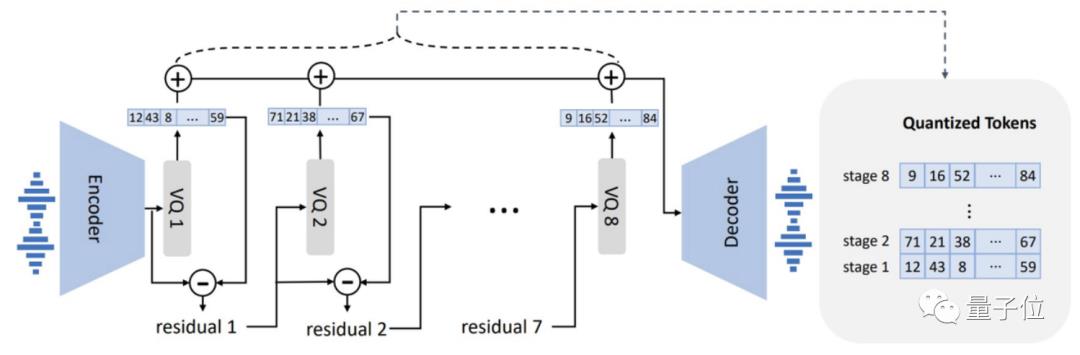
相比传统模型采用梅尔频谱提取特征,VALL·E直接将语音合成当成了语言模型的任务,前者是连续的,后者是离散化的。
具体来说,传统语音合成流程往往是“音素→梅尔频谱(mel-spectrogram)→波形”这样的路子。
但VALL·E将这一流程变成了“音素→离散音频编码→波形”:

具体到模型设计上,VALL·E也和VQVAE类似,将音频量化成一系列离散tokens,其中第一个量化器负责捕捉音频内容和说话者身份特征,后几个量化器则负责细化信号,使之听起来更自然:
随后以文本和3秒钟的声音提示作为条件,自回归地输出离散音频编码:
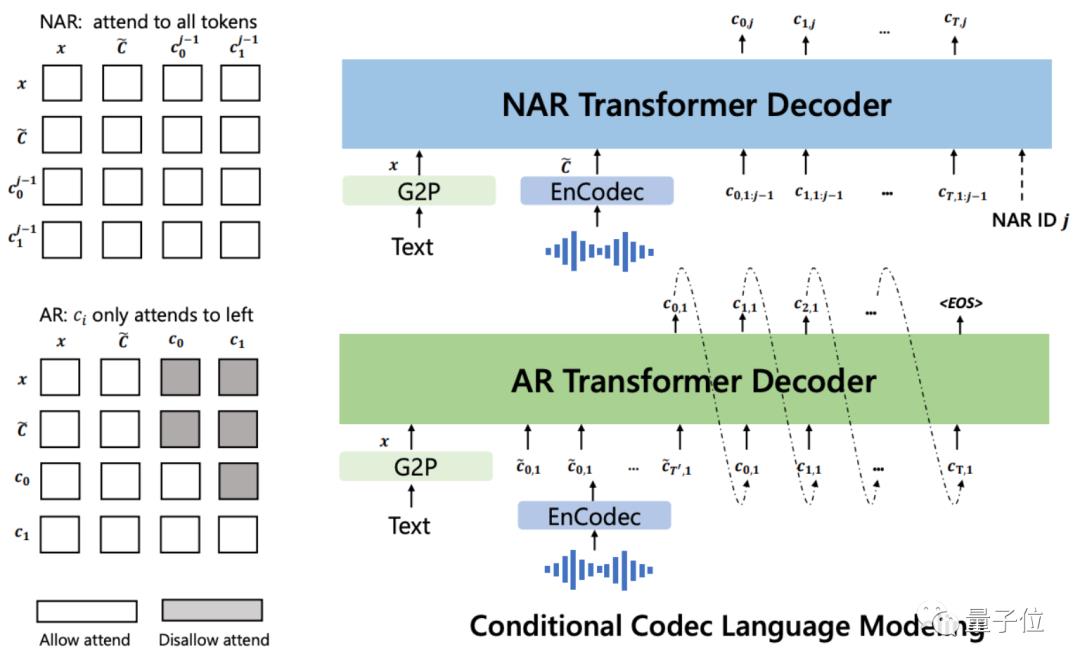
VALL·E还是个全能选手,除了零样本语音合成,同时还支持语音编辑、与GPT-3结合的语音内容创建。
那么在实际测试中,VALL·E的效果如何呢?
连环境背景音都能还原
根据已合成的语音效果来看,VALL·E能还原的绝不仅仅是说话人的音色。
不仅语气模仿到位,而且还支持多种不同语速的选择,例如这是在两次说同一句话时,VALL·E给出的两种不同语速,但音色相似度仍然较高:
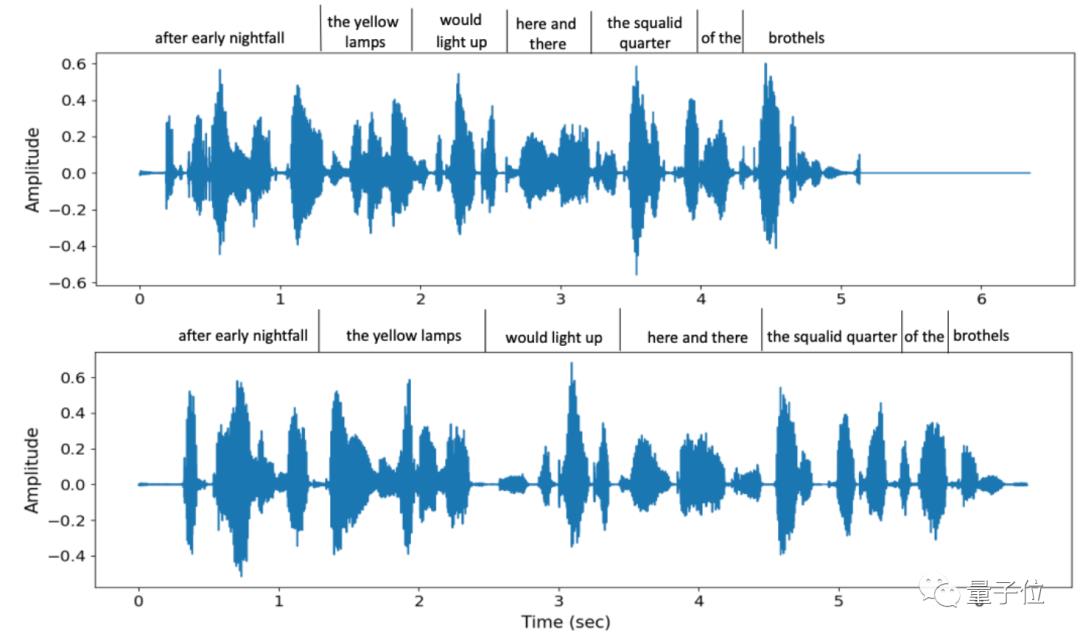
同时,连说话者的环境背景音也能准确还原。
除此之外,VALL·E还能模仿说话者的多种情绪,包括愤怒、困倦、中立、愉悦和恶心等好几种类型。
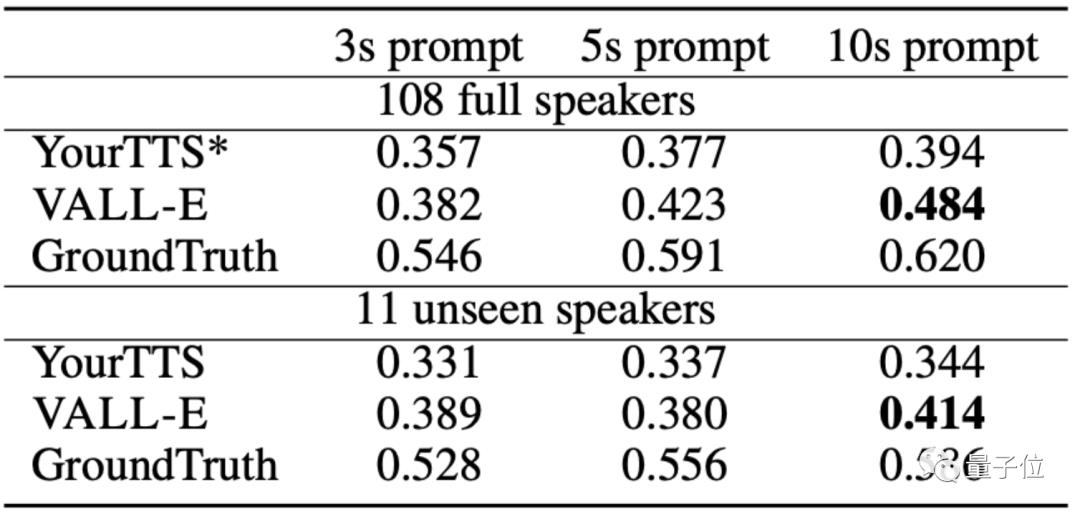
值得一提的是,VALL·E训练用的数据集不算特别大。
相比OpenAI的Whisper用了68万小时的音频训练,在只用了7000多名演讲者、6万小时训练的情况下,VALL·E就在语音合成相似度上超过了经过预训练的语音合成模型YourTTS。
而且,YourTTS在训练时,事先已经听过108个演讲者中的97人声音,但在实际测试中还是比不过VALL·E。
有网友已经在畅想它可以应用的地方了:
不仅可以用在模仿自己的声音上,例如帮助残障人士和别人完成对话,也可以在自己不想说话时用它代替自己发语音。
当然,还可以用在有声书的录制上。
不过,VALL·E目前还没开源,要想试用可能还得再等等。
作者介绍
这篇论文所有作者均来自微软,其中有三位共同一作。

一作Chengyi Wang,南开大学和微软亚研院联合培养博士生,研究兴趣是语音识别、语音翻译和语音预训练模型等。

共同一作Sanyuan Chen,哈工大和微软亚研院联合培养博士生,研究方向包括自监督学习、NLP和语音处理等。

共同一作Yu Wu,微软亚研院NLP小组研究员,在北航获得博士学位,研究方向是语音处理、聊天机器人系统和机器翻译等。

感兴趣的小伙伴可以戳下方论文地址查看~
论文地址:
https://arxiv.org/abs/2301.02111
音频试听地址:
https://valle-demo.github.io/
参考链接:
https://twitter.com/DrJimFan/status/1611397525541617665
— 完 —
「人工智能」、「智能汽车」微信社群邀你加入!
欢迎关注人工智能、智能汽车的小伙伴们加入交流群,与AI从业者交流、切磋,不错过最新行业发展&技术进展。
PS. 加好友请务必备注您的姓名-公司-职位噢 ~

点这里👇关注我,记得标星哦~
以上是关于3秒复制任何人的嗓音!微软音频版DALL·E细思极恐,连环境背景音也能模仿的主要内容,如果未能解决你的问题,请参考以下文章