k8s 污点和容忍
Posted 看,未来
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了k8s 污点和容忍相关的知识,希望对你有一定的参考价值。
文章目录
污点和容忍
在 Kubernetes 中,节点亲和性 NodeAffinity 是 Pod 上定义的一种属性,能够使 Pod 按我们的要求调度到某个节点上,而 Taints(污点) 则恰恰相反,它是 Node 上的一个属性,可以让 Pod 不能调度到带污点的节点上,甚至会对带污点节点上已有的 Pod 进行驱逐。当然,对应的 Kubernetes 可以给 Pod 设置 Tolerations(容忍) 属性来让 Pod 能够容忍节点上设置的污点,这样在调度时就会忽略节点上设置的污点,将 Pod 调度到该节点。一般时候 Taints 通常与 Tolerations 配合使用。
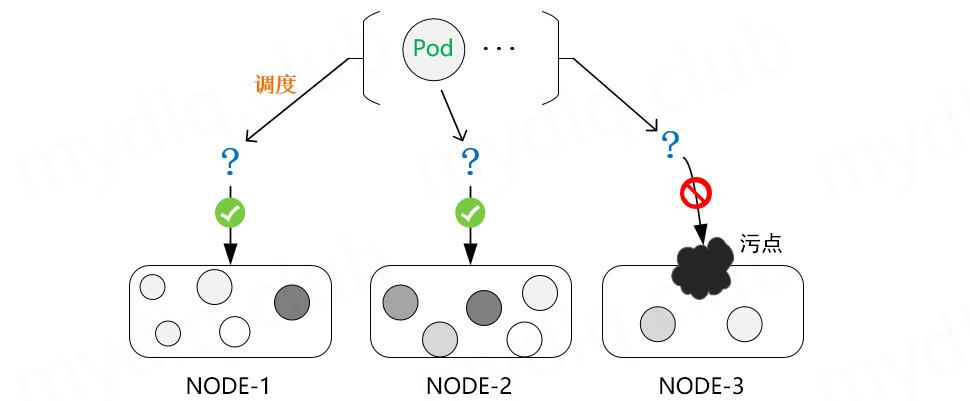
- 一个 node 可以有多个污点;
- 一个 pod 可以有多个容忍;
- kubernetes 执行多个污点和容忍方法类似于过滤器
如果一个 node 有多个污点,且 pod 上也有多个容忍,只要 pod 中容忍能包含 node 上设置的全部污点,就可以将 pod 调度到该 node 上。如果 pod 上设置的容忍不能够包含 node 上设置的全部污点,且 node 上剩下不能被包含的污点 effect 为 PreferNoSchedule,那么也可能会被调度到该节点。
注意:
当 pod 存在容忍,首先 pod 会选择没有污点的节点,然后再次选择容忍污点的节点。
- 如果 node 上带有污点 effect 为 NoSchedule,而 pod 上不带响应的容忍,kubernetes 就不会调度 pod 到这台 node 上。
- 如果 Node 上带有污点 effect 为 PreferNoShedule,这时候 Kubernetes 会努力不要调度这个 Pod 到这个 Node 上。
- 如果 Node 上带有污点 effect 为 NoExecute,这个已经在 Node 上运行的 Pod 会从 Node 上驱逐掉。没有运行在 Node 的 Pod 不能被调度到这个 Node 上。一般使用与当某个节点处于 NotReady 状态下,pod 迅速在其他正常节点启动。
污点(Taints)
查看污点:
$ kubectl get nodes k8s-master -o go-template=.spec.taints
[map[effect:NoSchedule key:node-role.kubernetes.io/master]]
污点内容一般组成为 key、value 及一个 effect 三个元素,表现为:
```go
<key>=<value>:<effect>
这里的 value 可以为空,表现形式为:
node-role.kubernetes.io/master:NoSchedule
- key: node-role.kubernetes.io/master
- value: 空
- effect: NoSchedule
设置污点
一般我们需要想要设置某个节点只允许特定的 Pod 进行调度,这时候就得对节点设置污点,可以按 kubectl taint node nodename key=value:effect 格式进行设置,其中 effect 可取值如下:
- PreferNoSchedule: 尽量不要调度。
- NoSchedule: 一定不能被调度。
- NoExecute: 不仅不会调度, 还会驱逐 Node 上已有的 Pod。
一般时候我们设置污点,就像下面例子一样对其进行设置:
# 设置污点并不允许 Pod 调度到该节点
$ kubectl taint node k8s-master key1=value1:NoSchedule
# 设置污点尽量阻止污点调度到该节点
$ kubectl taint node k8s-master key2=value2:PreferNoSchedule
# 设置污点,不允许普通 Pod 调度到该节点,且将该节点上已经存在的 Pod 进行驱逐
$ kubectl taint node k8s-master key3=value3:NoExecute
删除污点
上面说明了如何对 Node 添加污点阻止 Pod 进行调度,下面再说一下如何删除节点上的污点,可以使用下面命令:
kubectl taint node [node] [key]-
上面语法和创建污点类似,不过需要注意的是删除污点需要知道 key 和最后面设置一个 “-” 两项将污点删除,示例如下:
为了方便演示,先给节点设置污点:
# 设置污点1
$ kubectl taint node k8s-master key1=value1:PreferNoSchedule
node/k8s-master tainted
# 设置污点2
$ kubectl taint node k8s-master key2=value2:NoSchedule
node/k8s-master tainted
# 设置污点3,并且不设置 value
$ kubectl taint node k8s-master key2=:PreferNoSchedule
node/k8s-master tainted
查看污点,可以看到上面设置的三个值:
$ kubectl describe nodes k8s-master
...
Taints: key2=value2:NoSchedule
node-role.kubernetes.io/master:NoSchedule
key1=value1:PreferNoSchedule
key2:PreferNoSchedule
...
然后删除污点
删除污点,可以不指定 value,指定 [effect] 值就可删除该 key[effect] 的污点
$ kubectl taint node k8s-master key1:PreferNoSchedule-
也可以根据 key 直接将该 key2 的所有 [effect] 都删除:
$ kubectl taint node k8s-master key2-
再次查看污点,可以看到以上污点都被删除:
$ kubectl describe nodes k8s-master
...
Taints: node-role.kubernetes.io/master:NoSchedule
...
容忍 (toleratints)
Pod 设置容忍
为了使某些 Pod 禁止调度到某些特定节点上,就可以对节点设置污点 taints。当然,如果希望有些 Pod 能够忽略节点的污点,继续能够调度到该节点,就可以对 Pod 设置容忍,让 Pod 能够容忍节点上设置的污点,例如:
对一个节点设置污点:
kubectl taint node k8s-node01 key=value:NoSchedule
对于 Pod 设置容忍, 以下两种方式都可以:
# 容忍的 key、value 和对应 effect 也必须和污点 taints 保持一致
......
tolerations:
- key: "key"
operator: "Equal"
value: "value"
effect: "NoSchedule"
# 容忍 tolerations 的 key 和要污点 taints 的 key 一致,且设置的 effect 也相同,不需要设置 value
......
tolerations:
- key: "key"
operator: "Exists"
effect: "NoSchedule"
如果不指定 operator,则 operator 默认为 equal。
此外,有如下两个特例:
- 空的 key 配合 Exist 操作符可以匹配所有的键值对
- 空的 effect 匹配所有的 effect
那么,问题来了:
如果我的集群中有三个 node,我有两组 pod 要部署,每组 pod 要部署到同一个节点上,且两组 pod 不能部署到同一节点上,怎么操作最简单?
(好吧,nodeSelector 最简单…)
apiVersion: apps/vl
kind: Deployment
metadata:
name: example
spec:
replicas: 5
template:
spec:
......
tolerations:
- key: "key"
operator: "Equal"
value: "value"
effect: "NoSchedule"
设置容忍时间
正常情况下, 如果一个污点带有 effect=NoExecute 被添加到了这个 Node。那么不能容忍这个污点的所有 Pod 就会立即被踢掉。而带有容忍标签的 Pod 就不会踢掉。然而,一个带有 effect=Noexecute 的容忍可以指定一个 tolerationSeconds 来指定当这个污点被添加的时候在多长时间内不被踢掉(其实讲驱逐有点,不太对。我明显感觉这个容忍时间就是 pod 用来跑路的嘛)。例如:
tolerations:
- key: "key"
operator: "Equal"
value: "value"
effect: "Noexecute"
tolerationSeconds: 3600
如果这个 Pod 已经在这个带污点且 effect 为 NoExecute 的 node 上。这个 pod 可以一直运行到 3600s 后再被踢掉。如果这时候 Node 的污点被移除了,这个 Pod 就不会被踢掉。
容忍示例
Operator 默认是 Equal,可设置为 Equal 与 Exists 两种,按这两种进行示例:
Operator 是 Exists
容忍任何污点
例如一个空的 key,将匹配所有的 key、value、effect。即容忍任何污点。
tolerations:
- operator: "Exists"
容忍某 key 值的污点
例如一个空的 effect,并且 key 不为空,那么将匹配所有与 key 相同的 effect:
tolerations:
- key: "key"
operator: "Exists"
Operator 是 Equal
node 上有一个污点
Node 和 Pod 的 key 为 key1、value1 与 effect 相同则能调度:
#污点
key1=value1:NoSchedule
#Pod设置
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
node 上有多个污点
Node 的污点的 key、value、effect 和 Pod 容忍都相同则能调度:
## 设置污点
key1=value1:NoSchedule
key2=value2:NoExecute
## Pod设置容忍
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
- key: "key2"
operator: "Equal"
value: "value2"
effect: "NoExecute"
Node 的污点和 Pod 的大部分都相同,不同的是 Node 污点 effect 为 PreferNoSchedule 的,可能会调度:
## 污点
key1=value1:NoSchedule
key2=value2:NoExecute
key3=value3:PreferNoSchedule
## Pod设置容忍
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
- key: "key2"
operator: "Equal"
value: "value2"
effect: "NoExecute"
Node 的污点和 Pod 的大部分都相同,不同的是 Node 污点 effect 为 NoSchedule 和 NoExecute 的,不会被调度:
## 污点
key1=value1:NoSchedule
key2=value2:NoExecute
key3=value3:PreferNoSchedule
## Pod设置容忍
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
- key: "key3"
operator: "Equal"
value: "value3"
effect: "PreferNoSchedule"
对比理解 Exists 和 Equal 之间的区别:
- Exists 是包含,Equal 是等于,Exists 使用范围更广,而 Equal 则是精准匹配。
- 当污点中存在 NoExecute 时,而容忍中不存在 NoExecute 时,不会被调度到该节点。
- Exists 可以不写 value , 而 Equal 则一定要指定对应的 value
节点自污染,pod 应对节点故障
此外,当某些条件为 true 时,节点控制器会自动污染节点。内置以下污点:
| key | 注释 |
|---|---|
| node.kubernetes.io/not-ready | 节点尚未准备好。这对应于 NodeCondition Ready 为 false。 |
| node.kubernetes.io/unreachable | 无法从节点控制器访问节点。这对应于 NodeCondition Ready 为 Unknown。 |
| node.kubernetes.io/out-of-disk | 节点磁盘不足。 |
| node.kubernetes.io/memory-pressure | 节点有内存压力。 |
| node.kubernetes.io/disk-pressure | 节点有磁盘压力。 |
| node.kubernetes.io/network-unavailable | 节点的网络不可用。 |
| node.kubernetes.io/unschedulable | 节点不可调度。 |
| node.cloudprovider.kubernetes.io/uninitialized | 当 kubelet 从 “外部” 云提供程序开始时,此污点在节点上设置为将其标记为不可用。来自 cloud-controller-manager 的控制器初始化此节点后,kubelet 删除此污点。 |
通过上面知识的铺垫,当一个节点宕机时,kubernetes 集群会给它打上什么样的污点呢?
一个 Ready 状态的节点
$ kubectl get node k8s-node02 -o go-template=.spec.taints
<no value>
一个 NotReady 状态的节点
$ kubectl get node k8s-node02 -o go-template=.spec.taints
[map[effect:NoSchedule key:node.kubernetes.io/unreachable timeAdded:2022-07-0423T13:49:58Z]
map[effect:NoExecute key:node.kubernetes.io/unreachable timeAdded:2021-07-04T13:50:03Z]]
处于 NotReady 状态的节点被打上了下面两个污点:
Taints: node.kubernetes.io/unreachable:NoExecute
node.kubernetes.io/unreachable:NoSchedule
接下来测试 kubernetes 集群会给 Pod 分配什么样的容忍。
注:这两个是 kubernetes 自动给 pod 添加的容忍。
$ kubectl get po nginx-745b4df97d-mgdmp -o yaml
...
tolerations:
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
tolerationSeconds: 300 ## 300/60=5min
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
tolerationSeconds: 300 ## 300/60=5min
...
看到这里,Pod 的失效机制已经很明白了, 当 node 节点处于 NotReady 状态或者 unreachable 状态时,Pod 会容忍它 5 分钟,然后被驱逐。而这 5 分钟内就算 Pod 处于 running 状态,也是无法正常提供服务的。因此,可以在 yaml 清单中 手动指明 0 容忍,清单文件如下:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx
spec:
replicas: 4
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
tolerations:
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
tolerationSeconds: 0
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
tolerationSeconds: 0
containers:
- image: nginx:alpine
name: nginx
生成 Pod
$ kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-84f6f75c6-c76fm 1/1 Running 0 6s 10.244.3.16 k8s-node02 <none> <none>
nginx-84f6f75c6-hsxq5 1/1 Running 0 6s 10.244.3.15 k8s-node02 <none> <none>
nginx-84f6f75c6-wkt52 1/1 Running 0 6s 10.244.1.63 k8s-node01 <none> <none>
nginx-84f6f75c6-xmkjs 1/1 Running 0 6s 10.244.3.17 k8s-node02 <none> <none>
接下来强制关闭 k8s-node02 节点,查看 Pod 是否转移。
$ kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-84f6f75c6-c76fm 1/1 Terminating 0 116s 10.244.3.16 k8s-node02 <none> <none>
nginx-84f6f75c6-csqf4 1/1 Running 0 13s 10.244.1.66 k8s-node01 <none> <none>
nginx-84f6f75c6-hsxq5 1/1 Terminating 0 116s 10.244.3.15 k8s-node02 <none> <none>
nginx-84f6f75c6-r2v4p 1/1 Running 0 13s 10.244.1.64 k8s-node01 <none> <none>
nginx-84f6f75c6-v4knq 1/1 Running 0 13s 10.244.1.65 k8s-node01 <none> <none>
nginx-84f6f75c6-wkt52 1/1 Running 0 116s 10.244.1.63 k8s-node01 <none> <none>
nginx-84f6f75c6-xmkjs 1/1 Terminating 0 116s 10.244.3.17 k8s-node02 <none> <none>
在 node 节点转为 NotReady 状态后,Pod 立刻进行了转移。这是通过 在 yaml 清单文件中明确指定 容忍时间。还可以直接修改 apiserver 配置来修改默认容忍时间。
vim /etc/kubernetes/manifests/kube-apiserver.yaml
...
spec:
containers:
- command:
- kube-apiserver
- --advertise-address=192.168.1.11
- --default-not-ready-toleration-seconds=1 ## 新增行
- --default-unreachable-toleration-seconds=1 ## 新增行
...
修改保存后, kube-apiserver-k8s-masterpod 会自动重载最新配置。
$ kubectl get po nginx-84f6f75c6-wkt52 -o yaml
...
tolerations:
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
tolerationSeconds: 0
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
tolerationSeconds: 0
...
对于小型集群,可以直接设置全局变量。
注意:当 kubernetes 集群只有一个 node 节点时,无法做到 Pod 转移,因为 Pod 已经无路可退了。
以上是关于k8s 污点和容忍的主要内容,如果未能解决你的问题,请参考以下文章