顺丰 基于 Hook 机制实现数据血缘系统
Posted @SmartSi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了顺丰 基于 Hook 机制实现数据血缘系统相关的知识,希望对你有一定的参考价值。

1. 背景
一个完整的数据生命周期,包含从数据源头的数据采集、计算、加工、转换和展示等多个核心步骤以及到最终的数据销毁、归档的全部流程。我们用一种类似人类社会的血缘关系来描述这种数据之间的流转关系——即数据血缘。数据血缘属于元数据的一部分,能够为数据的溯源、价值评估、质量评估、数据归档、数据标签以及数据热度分析等多个方面提供技术支持和基础数据支撑。通常,大数据任务面临多种异构数据源的接入,执行引擎多,任务种类繁多,数据链路过长以及数据依赖复杂等问题。因此,为了更好的保障每个步骤的数据质量,便于对数据溯源和降低问题排查难度,需要开发一种支持多种数据源和执行引擎的大数据血缘系统。以某业务平台例,在原始层我们有5张表,分别是订单相关、店铺相关以及店铺商圈信息等基础数据;在ods/dim层的2张表分别依赖原始层的某些表,另外2张表包含店铺、网格基础信息,它们是其他端通过hive/hive load /spark等方式生成的;下游dwd层的店铺网格归属结果又依赖ods/dim层的中间表,最终dws层的结果表依赖所有基础数据,这样就形成了大数据血缘关系,如下图所示:

2. 大数据平台架构
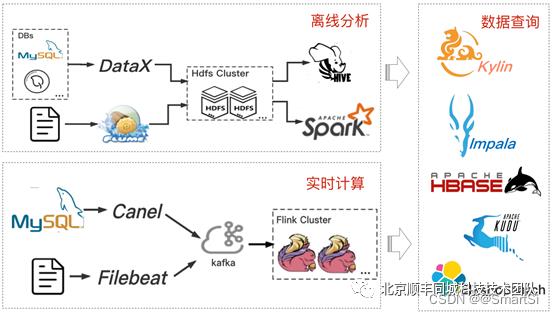
顺丰同城科技公司的大数据平台整体架构如图2所示。我们采用 DataX 作为离线异构数据源的接入工具,实现不同数据源到大数据集群的同步功能;以 Flume 作为日志接入工具,利用 Hive、Spark 进行后续离线分析。实时数据流采用 kafka 对接上游 Canel 和 Filebeat,并通过 Flink 进行实时计算。最终利用Impala、Kylin、Kudu、Hbase 等多种查询引擎进行 OLAP 分析。本文主要以 DataX、Hive、Flink 和 Impala 等执行引擎为例,探讨其血缘分析技术路线实现方案,涵盖数据同步、离线计算和实时计算等多个方向。
3. 架构选型
3.1 传统模式
大数据服务的传统架构模型是对外提供 Http 访问接口,被动接收上游服务发送的请求,从而实现具体逻辑。这种方式的缺点在于:
- 上游服务类型过多,入口统一困难;
- 代码侵入性强,必须对接上游所有服务;
- 扩展困难,任务链路过长,对线上任务有感知。
- 任务种类繁多,部分任务类型不方便对接http接口;
- 血缘采集容易造成消息丢失,数据完整性难以保障;
基于此,需要开发一种新型可扩展、易维护、低耦合、统一化管理的血缘分析方法。
3.2 Hook 模式
Hook 机制:在 Java 中表示在事件到达终点前进行拦截或监控的一种行为。大多数开源组件都提供了Hook 功能,支持自定义 Hook 函数。因此,可利用 Hook 机制,在大数据任务执行成功后,获取任务的相关信息,对其数据流向进行解析,获取其数据血缘信息。通过 Hook 机制实现血缘采集具有以下优点:
- 插件式开发,不同 Hook 之间完全解耦,便于扩展;
- 通过钩子模式,内嵌到执行引擎底层执行,可实时采集血缘信息,没有代码侵入,对上游服务没有任何依赖;
- Hook 逻辑执行状态对线上任务无感知。
4. 数据血缘系统 Data-Lineage
4.1 架构设计
整个架构设计如图 3 所示。整体分为4个模块:Hook 模块、Collector 模块、Lineage 模块以及 Common模块。
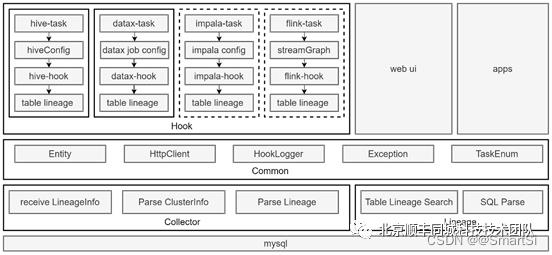
Hook 模块采取插件式开发模式,实现多种大数据执行引擎各自的 Hook 函数,对其任务配置参数进行解析,获取当前任务的集群信息、数据流向信息,操作规则等,并进行相应的血缘解析工作,生成TableLineageInfo 对象,最后通过 Http 请求的方式将结果发送到 Collector 端。
Collector 模块作为接收器,负责接收各个节点、各种执行引擎的 Hook 端发送过来的血缘对象,对其进行集群信息解析、表血缘关系转换,最终将结果持久化到数据库。
Lineage 模块与 web 页面以及第三方应用系统进行对接,主要负责对基础 SQL 进行资源解析和操作类型解析,同时,对数据库内的血缘关系进行查询、展示等功能。
Common 模块作为公共模块,为各个模块提供一些公共的方法、实例类、工具类以及 Hook 模块专用的自定义日志框架。
4.2 Hook 模块技术实现
目前已经实现了对 Hive 和 DataX 的 Hook 模块开发,能够满足对基于 Hive 的离线数据计算任务和基于DataX 的离线数据集成任务进行血缘采集,基本满足了大多数场景下的离线任务血缘采集的需求。同时,对 Flink 和 Impala 任务的血缘分析进行了技术可行性探究,并形成了具体的技术方案。
4.2.1 Hive-Hook模块
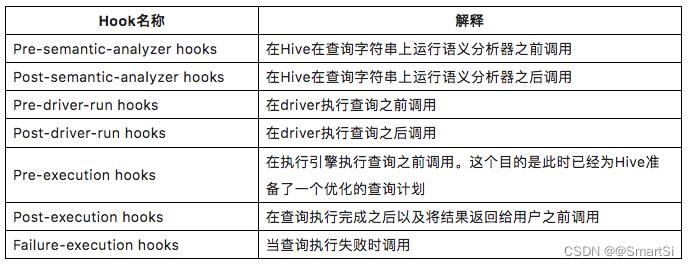
Hive 支持多种类型的 Hook 方法,并开放出了多个接口供外部实现,如表1所示。可根据调用点的位置选择相应的 Hook 接口进行实现。这里我们希望当 Hive 任务执行成功后进行血缘解析,因此,选择对Post-execution Hooks 接口做具体实现。
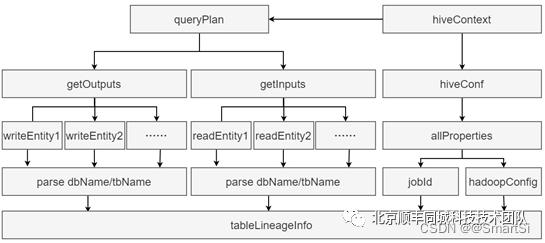
通过实现 ExecuteWithHookContext 接口,重写 run 方法,对 hookContext 对象进行解析,可以获取当前 Hive 集群信息和执行 SQL 的查询计划,如图4所示。首先,从 HiveContext 对象获取 QueryPlan(查询计划)和 HiveConf(hive配置信息),对 QueryPlan 对象进行解析,获取 WriteEntities(输入表集合)和 ReadEntities(输出表集合),进而解析库名、表名。同时,对 HiveConf 进行解析,获取allProperties 对象,进而获取当前任务的 JobId 和 HadoopConfig(当前集群信息)。最后将输入表、输出表、JobId 以及集群信息封装到 TableLineageInfo 对象中,通过 http 请求发送到 Collector端。
4.2.2 DataX-Hook模块
DataX 是由淘宝内部团队开发的异构数据源离线同步工具,支持丰富的数据源类型之间的数据同步功能。在公司内部,主要为离线数据集成平台提供底层架构支持,实现异构数据源之间的离线数据同步功能。DataX 整体任务执行流程如下所示:
- preHandle:job前置操作,获取插件类型;
- init:更新线程名,初始化reader和writer插件;
- prepare:执行插件前的准备工作,执行reader和writer插件job中的prepare函数;
- split:拆分任务,计算并行度;
- schedule:分配任务,启动线程池,执行任务;
- post:执行查询后的操作;
- invokeHooks:调用外置hook jar包,执行钩子函数。
DataX 自带 Hook 接口,可支持外部自定义扩展实现。因此,我们主要针对第7步进行外置 hook jar 包开发,从而实现血缘解析的钩子函数。通过实现 com.alibaba.datax.common.spi.Hook 接口,重写 invoke方法,获取 DataX job 的配置文件,从而进行源表和目标表的解析。
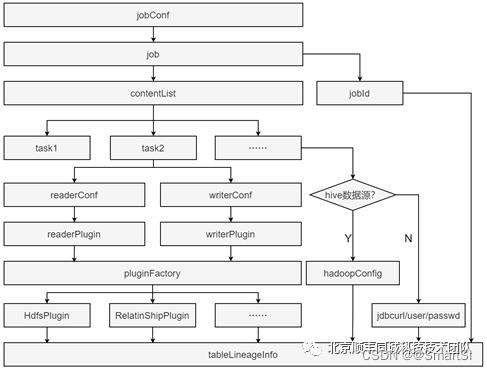
整个流程如图5所示。首先,jobConf 获取 job 信息,从 job 中获取任务参数列表(contentList)。我们遍历每个参数对象,对 task 信息进行解析,获取 reader 和 writer 配置,通过工厂模式进行具体的读写插件类型解析。我们支持基于hdfs的大数据分布式文件存储系统和传统关系型数据库类型的数据源的血缘解析,从而获取源数据源信息和目标数据源信息,再结合从 job 中获取的 jobId,最终封装成 tableLineageInfo 对象,通过http请求方式发送给Collector端。
4.2.3 Flink-Hook模块
Flink 本身不支持扩展外部 Hook 方式,需要修改源码,添加调用外部 hook 函数的功能,从而实现解析血缘 hook 逻辑。通过修改 flink-streaming-java 模块org.apache.flink.streaming.api.graph.StreamGraphGenerator 类的 generate() 方法。在该方法内部调用扫描hook jar 的步骤,并将 streamGraph 对象作为传参,仿照 DataX 加载 hook jar 包方法,实现 flink 自定义 hook jar 包类加载功能。核心代码如图6所示。
public StreamGraph generate()
streamGraph = new StreamGraph(executionConfig, checkpointConfig);
······
LOG.info("wb: 添加hook函数的位置...");
//指定hook包路径
HookInvoker in = new HookInvoker(streamGraph, new File("xxxx"));
in.invokeAll();
······
return builtStreamGraph;
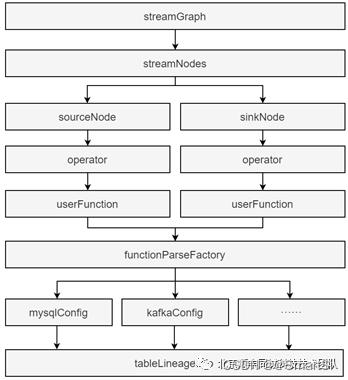
Flink-Hook 解析血缘的逻辑如图7所示。首先,获取 streamGraph 对象,从中获取 streamNodes 节点数组对象,获取数组内第0个和最后一个元素,分别对应flink流任务的 source 和 sink 相关信息。从source/sink 对象内获取 operator 对象,该对象内部记录了用户函数(userFunction)以及具体的数据源信息。这里通过工厂模式获取各个类型的userFunction中数据源配置信息,比如kafka、mysql等。最终我们解析这些数据源信息,获取整个任务的数据流向关系,并封装成 tableLineageInfo 对象,发送到Collector端。
4.2.4 Impala-Hook模块
Impala 内部已经进行了任务血缘分析,并且通过参数配置,可以将血缘结果(表级、字段级别)写入到指定的本地lineage_event_log_dir目录下的log文件内。通过开发hook函数,对lineage-log日志进行解析,封装成统一的 tableLineageInfo 对象,发送到 Collector 端,从而实现对 impala 任务的血缘采集功能。
4.3 Collector模块技术实现
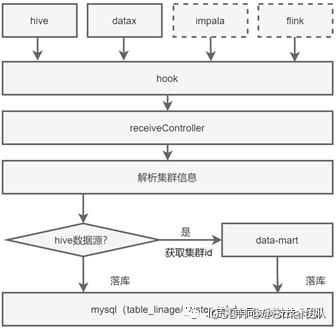
Collector模块作为血缘请求的接收器,负责对各个Hook端的血缘请求进行统一处理。首先,对接收的请求参数进行集群信息解析,判断集群类型,获取集群id。同时对表级血缘关系进行转换,获取任务id,封装成TableLineage对象,最终落库。整体流程如图8所示。
4.4 Lineage模块技术实现
Lineage 模块主要与 web 页面以及第三方外部系统交互,提供多种血缘查询接口。同时也实现了基础的sql解析功能,为权限系统验权提供基础技术支持。
4.4.1 SQL 解析
SQL 解析是权限验证的必要环节,也为刷新 Imapla 元数据提供技术支持。

我们希望从一条可执行sql中获取各个库表信息以及对每个库表进行的操作类型,以便进行权限验证,或者对表进行数据标签、热度分析等。主要思路如表2所示。首先,通过org.apache.hadoop.hive.ql.parse.ParseDriver 类获取 hiveSql 的抽象语法树,然后对抽象语法树进行深度优先遍历,每次更新当前节点操作符和操作库表对象。自上而下,依次获取操作类型和相应的库表名(没有库表名则跳过),最终结果如表2右侧所示。
4.5 Common模块技术实现
Common模块为其他模块提供了一些公共的类和方法,主要包括以下几个部分:
- 实体类:集群信息、表血缘信息,表血缘对象等;
- 异常类:统一的自定义异常类;
- 枚举类:集群类型枚举、任务类型枚举;
- 工具类:字符串校验工具、http工具、shell脚本工具等;
- 日志类:为hook模块单独提供的一套自定义的日志框架。
为了避免hook函数对线上任务的影响,hook日志需要单独收集。同时,由于不同的底层执行引擎(如hive、datax、flink等)采用不同的日志框架,导致hook函数开发过程中日志框架不统一,日志收集困难。因此,在 common 模块自定义实现了一套简易的日志收集框架,底层采用 java.io.FileOutputStream 类进行日志写入,支持通过配置文件方式指定日志打印规则和日志文件滚动策略。
5. 展望
目前已经实现了对 Hive 和 DataX 的表级血缘管理功能,同时,对 Impala/Flink 的血缘分析也有了可行的技术方案。未来考虑增加对 MySQL/Oracle 等传统关系型数据源以及 Kafka 等流式数据源进行血缘分析以及基于血缘数据实现数据标签和数据热度分析等功能。
以上是关于顺丰 基于 Hook 机制实现数据血缘系统的主要内容,如果未能解决你的问题,请参考以下文章
基于Python-sqlparse的SQL表血缘追踪解析实现
基于Python-sqlparse的SQL字段血缘追踪解析实现