基于Python-sqlparse的SQL字段血缘追踪解析实现
Posted fanstuck
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于Python-sqlparse的SQL字段血缘追踪解析实现相关的知识,希望对你有一定的参考价值。
目录
前言
SQL解析和血缘追踪的研究现在差不多可以告一段落了,从8月22日写HiveSQL源码之语法词法编译文件解析一文详解这篇文章以来便断断续续的对SQL语法解析研究,到了今天终于是有了一番成果。一般做此类研究的项目都是在数据治理和数据中台方面的服务作支撑,对于数据安全作用挺大的,多的内容我在上篇文章里面已经讲述了很多了,这里不再多提:
基于Python-sqlparse的SQL表血缘追踪解析实现,大家可以看这篇文章,接下来是接着上篇内容补充一下该功能的完善,也就是实现SQL字段血缘的解析,这是做Hive血缘或者mysql必须完成的功能,当然实现起来也是比较麻烦的。这里主要讲一下思路和实现的步骤。
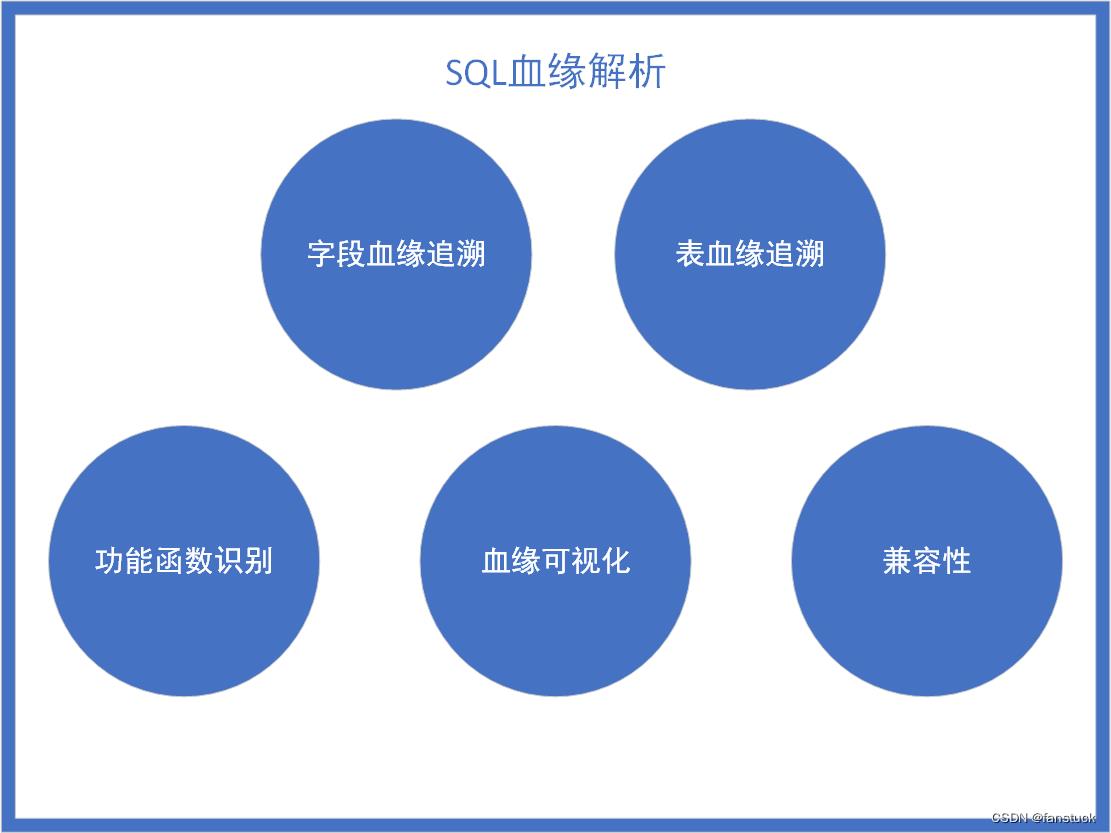
一、字段血缘
1.区别字段
字段血缘在于解析树的叶子节点的遍历,这里仍然还是使用递归就行了但是这里需要注意的一点,Function函数也会被遍历到以及表的别名和字段的别名,这两个是需要处理,如果可以的话最好将其提取出来,也有一定的解析必要。我们来看看sqlparse的解析树是如何判定这两个关键字段的:


功能函数还是很好解析的,根据token的parent就可以获取Function字段,但是别名的话就不好处理,和其他字段的解析是一样的。
2.区别标识符序列
这里有两个可以递归的序列,和上次遍历表是不一样的,重点需要考虑的点在于Function和Parenthesis这两个节点都是可以递归的,上次表的遍历需要调整遍历节点,需要将这两个递归节点都要考虑进去。

3.功能函数设定
同样对于字段来说也存在着很多小问题需要处理,如重复字段,以及字段对应表如何关联,去除别名等关键函数需要处理。对于字段的层级和对应表名需要设定一个变量来记录其深度,对于SQL语句来说,如果主题功能是实现建表和插入的话1,肯定第一层语句是存在select选择字段的,那么这一层就可以解析出表的别名,再做去重剔除就好了。
二、字段血缘可视化
实现了字段以及与对应表的关联,作数据可视化也就不难了,拥有pyecharts可以帮我们快速出图。挑选例图需要考虑,对于SQLflow的这种效果还是实现需要开发一定的前端代码:
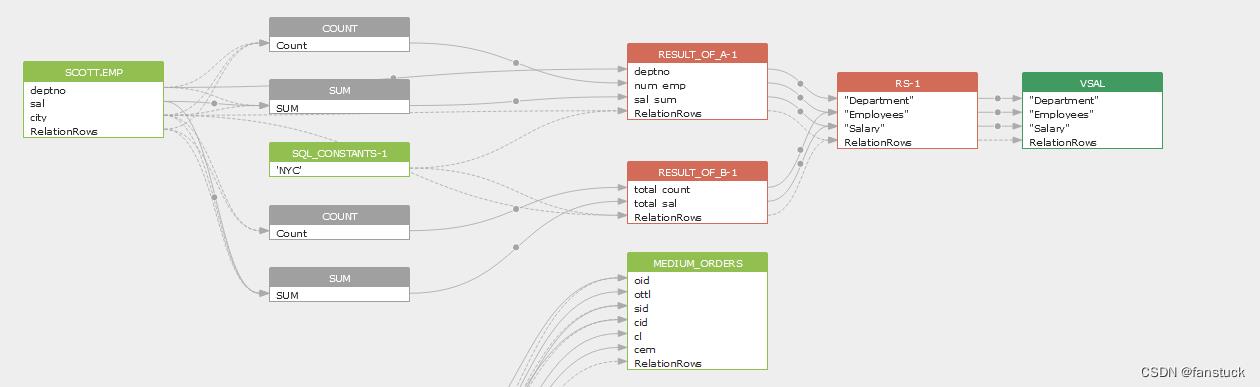
在看echart的例图中我看到了一个可以适合表达字段血缘的图表,那就是桑葚图。

做成create或者是insert as的话关系为表->表->字段的话正好合适。但是这个有个比较坑的点,就是echart的桑葚图如果字段存在重复的话将不能显示正常的图表。
大体的实现效果如下:
insert into temp.road_check_20220902
select
m.id as mid,
m.order_id as morder_id,
m.finish_time as mfinish_time,
m.link_id as mlink_id,
m.sid as msid,
m.ctime as mctime,
n.linkid as nlinkid,
n.level as nlevel,
n.ctime as nctime,
n.sids as nsids
from
(
select
id,
order_id,
finish_time,
link_id,
sid,
from_unixtime(
cast(
cast(
get_json_object(
split(regexp_replace(regexp_replace(frames , '\\\\[|\\\\]', ''), '\\\\\\\\,\\\\', '\\\\\\\\;\\\\'), '\\\\;')[0]
, '$.timestamp'
) as bigint
)/ 1000
as bigint)
,
'yyyyMMddHHmm')
as ctime
from
(
select
id,
order_id,
finish_time,
link_id,
sid,
like,
frames,
dt
from
dws_crowdsourcing.cs_order_link_mysql
)
where
dt = 202208
)m
INNER JOIN
(
select
linkid ,
level,
from_unixtime(
cast(
cast(
gpstime as bigint
)/ 1000
as bigint)
,
'yyyyMMddHHmm')
as ctime
,sids
from track_point_traffic_dev.tk_track_traffic_info_offline where
dt > '2022-08-01' and level > 3
)n on m.link_id = n.linkid and m.ctime = n.ctimeif __name__ == '__main__':
table_names=[]
column_names=[]
function_names=[]
alias_names=[]
columns_rank=0
sql=get_sqlstr('read_sql.txt')
stmt_tuple=analysis_statements(sql)
for each_stmt in stmt_tuple:
type_name=get_main_functionsql(each_stmt)
#get_ASTTree(each_stmt)
blood_table(each_stmt)
blood_column(each_stmt)
column_visus() 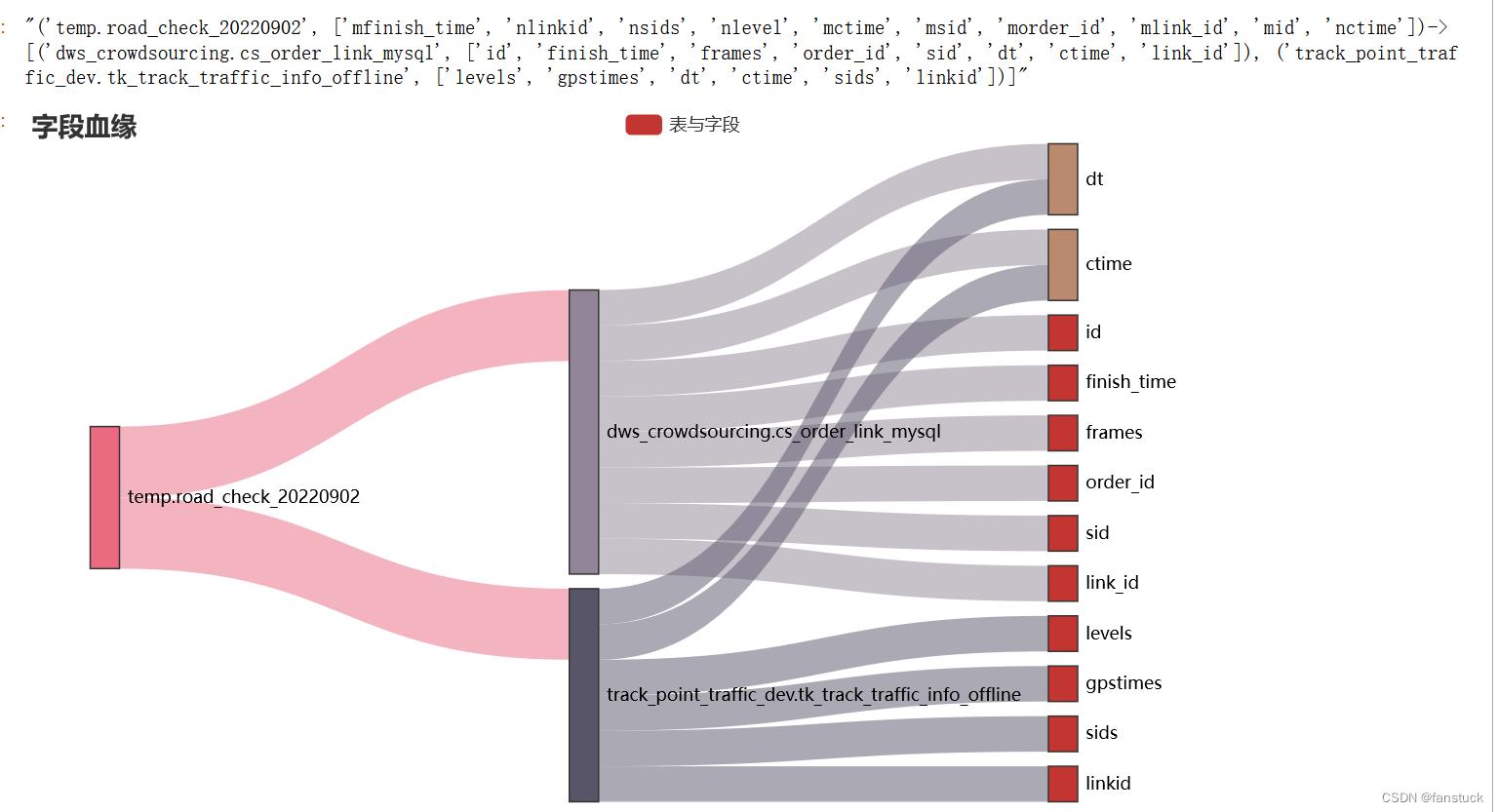
当然这里还存在三重嵌套,四重嵌套。
但是表的遍历不会存在问题,那么字段的提取通过select提取出的列表也存在多个列表,这里仍然需要考虑。
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见
以上是关于基于Python-sqlparse的SQL字段血缘追踪解析实现的主要内容,如果未能解决你的问题,请参考以下文章