Python数据处理:处理 JSONXMLCSV 三种格式数据
Posted 呆呆敲代码的阿狸
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python数据处理:处理 JSONXMLCSV 三种格式数据相关的知识,希望对你有一定的参考价值。
前言
以易于机器理解的方式来存储数据的文件格式,通常被称作机器可读的 (machine readable)。常见的机器可读格式包括:
逗号分隔值(Comma-Separated Values,CSV)
javascript 对象符号(JavaScript Object Notation,JSON)
可扩展标记语言(eXtensible Markup Language,XML)
在口语和书面语中,提到这些数据格式时通常使用它们的短名字(如 CSV)。 我们将使用这些缩写 。

一、CSV数据
CSV 文件(简称为 CSV)是指将数据列用逗号分隔的文件。文件的扩展名是 .csv。
另一种数据类型,叫作制表符分隔值(tab-separated values,TSV)数据,有时也与 CSV归为一类。TSV 与 CSV 唯一的不同之处在于,数据列之间的分隔符是制表符(tab),而不是逗号。文件的扩展名通常是 .tsv,但有时也用 .csv 作为扩展名。从本质上来看,.tsv 文件与 .csv 文件在Python 中的作用是相同的。
我们采用的数据源是从世界卫生组织(www.who.int/zh/home)中下载…
打开世卫组织官网后,点击“健康主题”,“数据和统计” 就能找到很多数据。
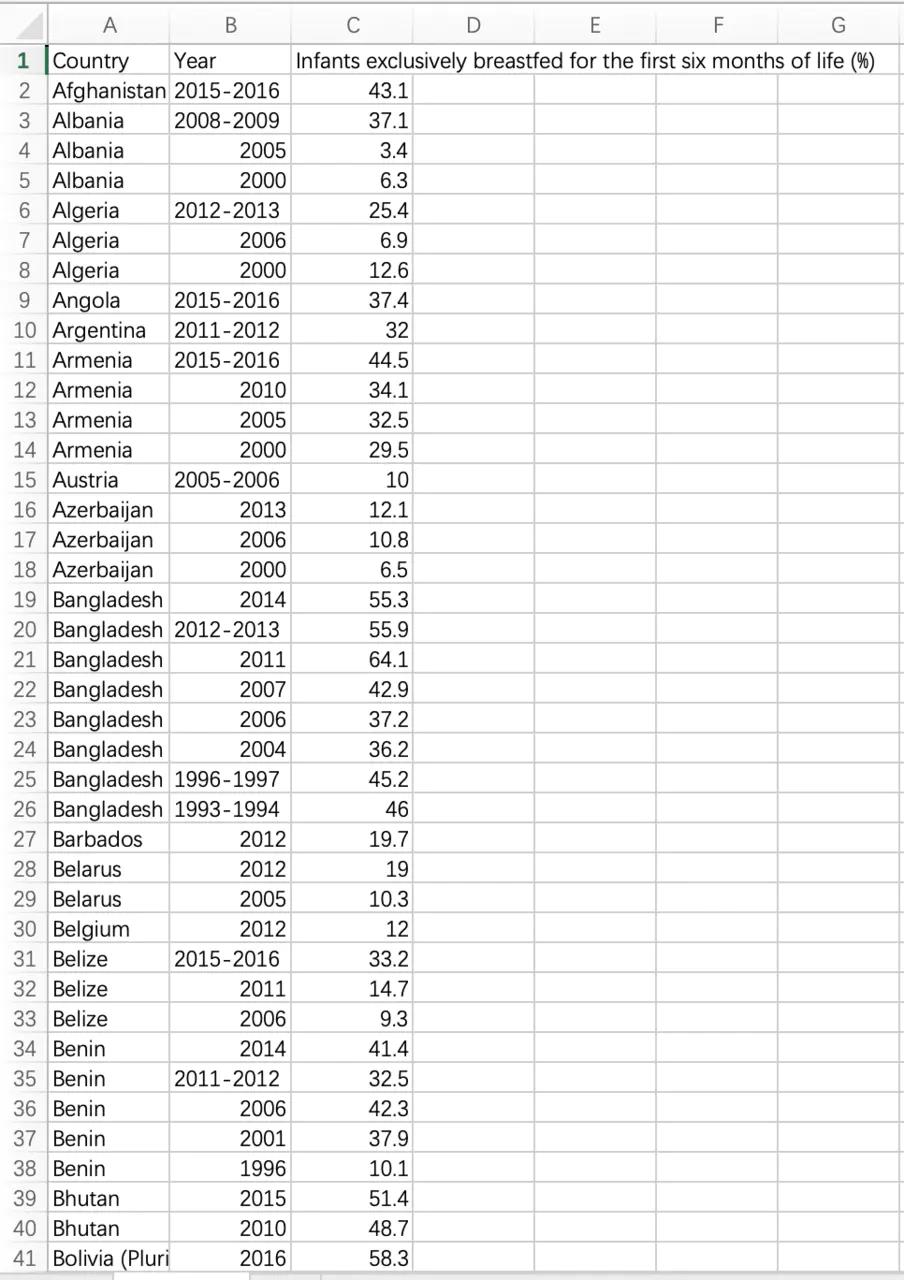
这里下载了关于婴幼儿护理的统计数据,并重命名为 data.csv。
csv 文件可以直接用 Excel 打开直观看到,我们用 Excel 打开如下图:
接下来就要用 Python 来简单的处理这些数据。
以列表的形式读取csv数据
编写一个读取 csv 文件的程序:
import csv
csvfile = open('./data.csv', 'r')
reader = csv.reader(csvfile)
for row in reader:
print(row)
import csv 将导入 Python 自带的 csv 模块。csvfile = open(’./data.csv’, ‘r’) 以只读的形式打开数据文件并存储到变量 csvfile 中。然后调用 csv 的 reader() 方法将输出保存在 reader 变量中,再用 for 循环将数据输出。
运行程序,控制台输出:

可以看到跟 Excel 打开的内容一致。
以字典的形式读取csv数据
改一下代码,以字典的形式读取 csv
import csv
csvfile = open('./data.csv', 'r')
reader = csv.DictReader(csvfile)
for row in reader:
print(row)
控制台输出:

二、JSON数据
同样在世卫组织官网下载数据源,重命名为 data.json。用格式化工具打开 json 文件如下:
编写程序对 json 进行解析
import json
# 将 json 文件读取成字符串
json_data = open('./data.json').read()
# 对json数据解码
data = json.loads(json_data)
# data 的类型是 字典dict
print(type(data))
# 直接打印 data
print(data)
# 遍历字典
for k, v in data.items():
print(k + ':' + str(v))
控制台输出:

Python3 中可以使用 json 模块来对 JSON 数据进行编解码,它包含了两个函数:
json.dumps(): 对数据进行编码。
json.loads(): 对数据进行解码。
在json的编解码过程中,python 的原始类型与json类型会相互转换,具体的转化对照如下:
Python 编码为 JSON 类型转换对应表:
| Python | JSON |
|---|---|
| dict | object |
| list, tuple | array |
| str | string |
| int, float, int- & float-derived Enums | number |
| true | true |
| true | true |
| False | False |
| None | null |
三、XML 数据
XML 格式的数据既便于机器读取,也便于人工读取。但是对于本章的数据集来说,预览并理解 CSV 文件和 JSON 文件要比 XML 文件容易得多。
xml 格式说明:
Tag: 使用<和>包围的部分;
Element:被Tag包围的部分,如 2003,可以认为是一个节点,它可以有子节点;
Attribute:在Tag中可能存在的 name/value 对,如示例中的 title=“Enemy Behind”,一般表示属性。
世卫组织的数据不好理解,咱们用个简单的能看得懂的电影数据来做演示:
<?xml version="1.0" encoding="UTF-8"?>
<collection shelf="New Arrivals">
<movie title="Enemy Behind">
<type>War, Thriller</type>
<format>DVD</format>
<year>2003</year>
<rating>PG</rating>
<stars>10</stars>
<description>Talk about a US-Japan war</description>
</movie>
<movie title="Transformers">
<type>Anime, Science Fiction</type>
<format>DVD</format>
<year>1989</year>
<rating>R</rating>
<stars>8</stars>
<description>A schientific fiction</description>
</movie>
<movie title="Trigun">
<type>Anime, Action</type>
<format>DVD</format>
<episodes>4</episodes>
<rating>PG</rating>
<stars>10</stars>
<description>Vash the Stampede!</description>
</movie>
<movie title="Ishtar">
<type>Comedy</type>
<format>VHS</format>
<rating>PG</rating>
<stars>2</stars>
<description>Viewable boredom</description>
</movie>
</collection>
这个数据相对来说比较简单,只有三层。但原理掌握了,几层数据都能搞定。
下面编写代码对上面的 xml 进行解析,解析之后再分别格式化成字典和 json 格式的数据输出:
from xml.etree import ElementTree as ET
import json
tree = ET.parse('./resource/movie.xml')
root = tree.getroot()
all_data = []
for movie in root:
# 存储电影数据的字典
movie_data =
# 存储属性的字典
attr_data =
# 取出 type 标签的值
movie_type = movie.find('type')
attr_data['type'] = movie_type.text
# 取出 format 标签的值
movie_format = movie.find('format')
attr_data['format'] = movie_format.text
# 取出 year 标签的值
movie_year = movie.find('year')
if movie_year:
attr_data['year'] = movie_year.text
# 取出 rating 标签的值
movie_rating = movie.find('rating')
attr_data['rating'] = movie_rating.text
# 取出 stars 标签的值
movie_stars = movie.find('stars')
attr_data['stars'] = movie_stars.text
# 取出 description 标签的值
movie_description = movie.find('description')
attr_data['description'] = movie_description.text
# 获取电影名字,以电影名为字典的键,属性信息为字典的值
movie_title = movie.attrib.get('title')
movie_data[movie_title] = attr_data
# 存入列表中
all_data.append(movie_data)
print(all_data)
# all_data 此时是一个列表对象,用 json.dumps() 将python对象转换为 json 字符串
json_str = json.dumps(all_data)
print(json_str)
注释写的比较详细,下面介绍下 ElementTree 提供的方法。
3.1 解析的三种方法
ElementTree 解析 xml 有三种方法:
调用parse()方法,返回解析树
tree = ET.parse('./resource/movie.xml') root = tree.getroot()
调用from_string(),返回解析树的根元素
data = open('./resource/movie.xml').read() root = ET.fromstring(data)
调用 ElementTree 类的 ElementTree(self, element=None, file=None) 方法
tree = ET.ElementTree(file="./resource/movie.xml") root = tree.getroot()
3.2 Element 对象
class xml.etree.ElementTree.Element(tag, attrib=, **extra)
Element 对象的属性
tag: 标签
text: 去除标签,获得标签中的内容。
attrib: 获取标签中的属性和属性值。
tail: 这个属性可以用来保存与元素相关联的附加数据。它的值通常是字符串,但可能是特定于应用程序的对象。
Element 对象的方法
clear():清除所有子元素和所有属性,并将文本和尾部属性设置为None。
get(attribute_name, default=None):通过指定属性名获取属性值。
items():以键值对的形式返回元素属性。
keys():以列表的方式返回元素名。
set(attribute_name,attribute_value):在某标签中设置属性和属性值。
append(subelement):将元素子元素添加到元素的子元素内部列表的末尾。
extend(subelements):追加子元素。
find(match, namespaces=None):找到第一个匹配的子元素,match可以是标签名或者path。返回Elememt实例或None。
findall(match, namespaces=None):找到所有匹配的子元素,返回的是一个元素列表。
findtext(match, default=None, namespaces=None):找到匹配第一个子元素的文本。返回的是匹配元素中的文本内容。
getchildren():Python3.2后使用 list(elem) 或 iteration.
getiterator(tag=None):Python3.2后使用 Element.iter()
iter(tag=None)):以当前元素为根创建树迭代器。迭代器遍历这个元素和它下面的所有元素(深度优先级)。如果标签不是None或’*’,那么只有标签等于标签的元素才会从迭代器返回。如果在迭代过程中修改树结构,则结果是未定义的。
iterfind(match, namespaces=None): 匹配满足条件的子元素,返回元素。
3.3 ElementTree 对象
class xml.etree.ElementTree.ElementTree(element=None, file=None)
ElementTree是一个包装器类,这个类表示一个完整的元素层次结构,并为标准XML的序列化添加了一些额外的支持。
setroot(element):替换根元素,原来的根元素中的内容会消失。
find(match, namespaces=None):从根元素开始匹配和 Element.find()作用一样。
findall(match, namespaces=None):从根元素开始匹配和 Element.findall()作用一样。
findtext(match, default=None, namespaces=None):从根元素开始匹配和 Element.findtext()作用一样。
getiterator(tag=None):Python3.2后使用 ElementTree.iter() 代替。
iter(tag=None):迭代所有元素
iterfind(match, namespaces=None):从根元素开始匹配和 Element.iterfind()作用一样。
parse(source, parser=None):解析xml文本,返回根元素。
write(file, encoding=”us-ascii”, xml_declaration=None, default_namespace=None, method=”xml”, *, short_empty_elements=True):写出XML文本。
对 JSON、XML、CSV三种格式数据的处理就讲完啦,
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!
QQ群:249029188
以上是关于Python数据处理:处理 JSONXMLCSV 三种格式数据的主要内容,如果未能解决你的问题,请参考以下文章
Python 图像处理 OpenCV :图像平滑(滤波)处理
Python 图像处理 OpenCV :图像平滑(滤波)处理