高性能零售IT系统的建设06-当应对大量HTTP请求时兼顾性能处理速度的架构设计
Posted TGITCIC
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高性能零售IT系统的建设06-当应对大量HTTP请求时兼顾性能处理速度的架构设计相关的知识,希望对你有一定的参考价值。
前言
这个系列不像我的那些个“保姆式”教程,那些保姆式教程我一周最多可以写8篇,因为太简单了。充其量花的时间就是用“看漫画”的方式去组织我的截图和尽量少文字多Sample。
而高性能系统建设系列这一块不仅仅只有代码,相反它甚至不会多写代码更多的是实战、科学依据、方法论、博弈学、技术管理学甚至到“哲学”。
因此每一篇都力求:精确还原现象、准确描述手法以及结果不能再让我趟过的血坑再让读者去趟一遍了。
各位要知道,我正在负责的系统有600多万行代码(我没有包括前端代码-小程序、APP),只是中台业务模块。我们的设计目标是百家店、>400万用户、日活30W、可随时应对1万个TPS、5万个QPS这么一个业务目标。
因为没有这个业务目标企业很难存活。到了这个业务目标,那么至少我们说:每天粗茶淡饭,偶尔每半年我吃个涮羊肉还是够了的。
因此,在这种规模的系统中,开发人员几十号,一切代码都不属于什么高科技,难就难在技术管理、技术架构。
这边多说一句在这种规模的项目中,你可以感受到什么叫真正的架构。
很多人认为架构师不就是比高级开发还要高级点的开发吗?
你错了。架构考虑的问题不仅仅是代码,而是结合着本企业的实际业务同时他自己手上对于同样的一个问题已经具备了不下3种、5种甚至10种到达目标的手段。而他需要在“成本、进度、风险、是否有利于企业可长期生存发展”中选择出最佳的一条“道路”的取舍。
这是企业级IT架构师需要考虑的,因此优秀的架构师从不考虑什么个人利益,他只考虑团队、企业的利益。
因此这样的文章非常难写,因此这样的文章也不可能高产。所以笔者也请各位见谅,这个系列势必出的比较慢,因为每一篇都是实战且成功、行之有效的技术架构、管理手法的叙述。
简介
各位还记得这个架构图不?

它分为六层削峰、四道防线。
特别是最最底层的深蓝色区域,我们又做了:五纵三横的互联网式的应用架构设计。
我们从这篇开始会展开这些点。
今天要叙述的还是在于HTTP请求。我们在之前的每秒万级并发的互联网交易系统的技术全架构中讲到过一个HTTP请求引发的“血案”。
在那个“故事”里,由于最早的一批开发失控,多处HTTP请求没有及时释放资源导致了Http请求泄漏达2,000多处最终导致整个系统的响应、吞吐率上不去。
其实Http请求这一块来说防止资源泄漏只是基本的必要的手段,它一点没有技术含量。碰到问题时就要去做整改,哪怕2,000处、哪怕1万处都需要一个个把它们纠正过来。
唯一难在如何在现有生产上、又不能把全资源投入到整改中、又要完成即定日常业务叠代目标这么一种“取巧”的技术管理手段而己。
而实际Http请求的使用场景还有另外几个点,我在上一篇中虽然提到,但未作深入展开,但也是值得时刻把它们形成明文规范和团队日常作息中去要贯彻的。
而一旦这些点养成了团队良好习惯并融入到了团队基因后,你的系统将会杜绝这一层情况的出现。因此它是属于5纵3横中的其中“一纵”TO B端当成TO C端来设计“的内容。而好玩的是-请允许我在此用“恐怖”两个字来说,这5纵3横中的每一个内容又都是一个“自循环”,即每一个点都又贯彻着5纵3纵。接下来我们就来看5纵3横中拿TO B端当成TO C端来设计这一纵来说事。
大型互联网系统中HTTP请求设计上容易疏忽的点
例一、把To B端当成To C端的性能要求来设计和开发
问题描述
微服务模块架构中,业务原子折分越细越好,肯定是有其好处。网上一些反微服务文章的作者要么就是没有经历过实战、要么就是接手“屎山”但没有勇气、毅力坚持到把“屎山”变成金山最后整天怨天尤人的抱怨。
微服务没有错、业务原子粒度折分必须细。
这也就随之带来一些问题,特别典型的例子我举几个各位就知道了。
面临互联网的系统来说最可怕的就是流量。这个流量分解成具体的内容其实就是HTTP请求。
我们都知道,nginx可以单机处理上万个并发。这点没错。
可是太多架构师只知其一不知其二。
那就是他们都把Nginx的本身性能当成了单纯流量、并发来看待问题而忽视了另一个重要的事务即:业务的事务处理过程。
这边所谓的业务就是指:首页打开->从DB或者从NoSQL或者从缓存加载10几个业务接口(甚至几十个业务接口)->每个业务接口都有取数据、运算、转换格式的系统资源开销->每个开销需要的耗时的累计这么一个“业务事务”。
这一个事务比如说“首页打开”就可能包括了几十个这样的事务,而每一个事务都在耗时。当它们加在一起耗费的时间就是一次首页打开的“速度”。
这个速度的快慢决定了你这一个业务的“响应速度”。
如果你的速度越慢,那么没有“事务”的nginx可以一秒处理完上万个Http请求。而有“事务”的http请求一旦进来可能你的nginx每一台只能最多处理几百个请求。
这就是为什么“纯技术架构无用论”而同时“技术架构又是决定论”并存的矛盾点所在。
没有事务时单台NG可以处理上万个请求,这是不懂技术的技术管理高管说出来的内容,他说了对,也说了不对。
那么实际你们的系统只能做出一个NG处理100个并发Http请求,此时就要反思你的这一根事务到底是在怎么请求了。
各位想一下,一个NG,它的超时是在多少?一般我们会设1秒超时,5秒左右的keep alive。稍微弱一些呢你设个2秒超时、10秒keep alive已经不得了了。
现在你告诉我,你的NG一秒只能处理100个并发,超过了100个并发,大量产生了HTTP ERROR、FAIL RATE>10%?为什么呢?
我们来看一个实际例子。
在后台运营管理平台时不时我们要导出所有持有“传说级名枪”系列的会员导致了前台APP在那一刻卡死个5-10分钟。
我们看了一下导出的数据,在500万会员里不超过5%拥有“传说级名枪”的人数,这才多少人呢?这才25万会员啊。
25万数据导出一下会卡死个5-10分钟?我曾经在2012年博客就介绍过用:多线程、多Worker非阻塞线程队列,导100万数据进系统或者出系统不过20分钟,内存使用恒定在250兆、CPU耗时不会超过10%使用率啊?怎么会做成这样呢?
我们来看设计:

不要笑!
团队一大,有极个别程序员在做这种看似简单的不能再简单的业务功能时都能做出这种“德性”出来。
这个问题其实它的表现过程如下逻辑推断发生:
- 每个微服务的tomcat、tower、netty都撑不住面临至少25万次瞬间到来的Http请求,而在微服务里每个业务集群中的一个embedded java web server能开出1,000条微服务(就是Http请求)已经算比较利害的系统了(我是按照4C,8GB内存一个embedded java web server来计算的);
- 单条的这么一个Http请求的完整事务很快,在100毫秒内即完成,但是瞬间到达的25万条Http请求,我算它处理了再快,由于是循环调用的因此还是会有一瞬间堵住其中一个或者两个微服务模块(一个模块是一个集群,有4-10个K8S副本组成);
- 一旦堵住了,每个幅本的embedded web server的http connection timeout默认为20,000毫秒(20秒),这20秒里一直不释放;
- 然后此时雪崩产生,雪崩是从下往上或者说从后往前崩的一个过程,我们假设卡住点在“武器主数据库”这一个服务,它雪崩时就会这样崩。武器主数据服务卡20秒往前崩到会员拥有武器的mapping这个服务再卡20秒再往前崩到会员模块。。。崩!崩!崩!
- 此时前端APP用户打开APP首页,上手先调用会员模块,发觉:这个微服务的Http请求数已经用完。我不管你是vm布署还是K8S布署,它都有一个OS系统,OS系统内max file open limitation也就65,535,以25万为外层循环基底的Http请求数啊,各位想想,这65,535哪够哈?于是前端APP白屏、卡死时要么因为Http请求数被耗尽导致、要么就是微服务模块不响应导致。最诡异的是打开卡一会,突然看到了首页,在首页里摆弄一下又卡死,而且是随机发生。这就是因为一开始微服务模块在卡住后它至少也会去试图释放几个严重超时的连接,释放一点死链那么就可以允许一点新的用户请求继续进来,随着卡顿的时间的延长。释放的速度越来越慢、释放的连接越来越少,因此逐步的在5-10分钟内越来越多的用户在打开APP时白屏了、卡了;
这就是整件事发生的过程。
治理手段
贯穿着:现有生产业务不能影响、日常叠代不能只一味为技术债让步。熊掌和鱼兼得法,然后我们把问题的治理分成三个阶段:
临时阶段-3天内上线
使用线程,固定住后端导出只有10个线程,每个线程内一个HTTP请求,这一个线程池一轮后sleep(80-100ms)-根据实际监控值。然后再来一轮,这样做根本上先“止血”,改动很小。付出的代价就是TO B端业务在操作导出时要多等一会时间。
短期治理-7天内上线
TO B端业务觉得导出一下要等40多分钟,1小时,有点慢,向CIO提出了投诉。IT技术出场。此时我们又想起了我之前我在《高性能零售IT系统的建设05-从0打造一个每秒万级并发的互联网交易系统的技术全架构》中讲到过的:你把一个含有几万个小文件每一个10几K的文件夹往百度网盘去上传耗时1个多小时。而你把这个目录打成一个百来兆的ZIP文件,此时再往百度网盘一扔也就两秒内完成上传的这么一个比喻。我们把getMemberById(int id)扩成了一个getMemberByIDS(List ids),一批传过去300个id,相应的会员和武器的匹配处的服务、武器主数据服务都新做一个批量接口。这个改动非致命的,又是新代码,实施很快。然后重构这个后台点击:导出按钮。
导出时此时我就启5个线程,线程少了,每个线程300个一批查出来,5个线程并发的就是一秒5次HTTP请求,每一次可以取出1,500条记录。
结果改造后我们发觉,哎呀,这个太爽了,整体硬件耗费减少了百倍,导出速度从原来的一次40分钟成了1分钟内完成导出。同时这个改动它产生的对现有生产、手头正在叠代任务的冲突微乎其微。
中长期治理-14天内上线
- 治理一、我们知道,我们的生产是多幅本的。而用户的请求通过K8S的service name是会任意飘移的,飘到这个幅本或者那个幅本。而我们的导出任务也可能同时在多个幅本内被一堆业务所访问,到时点了多了,飘了多了,依然会造成集群内Http泛滥。这个简单,加一个Redis全局锁,让已经有导出任务时后台提示业务等前面的导完了你再导下一个吧。因为这个导出动作一个是只有1分钟内的事,同时业务要导出时往往是某个部门要去做BLA BLA的分析,因此把它用分布式锁做成了单个任务执行就完事了。
- 治理二、随着导出的数据条件不再只是传说级枪这个等级,可能神级、黄金级会涉及50万会员,那么此时这个导出数据产生的微服务间的请求依然还是慢。依然还是影响到了我们的前端真实的TO C端用户,进一步怎么改呢?把这块直接改存到MongoDB去了。然后把用户常用不变信息存在Redis里,这种万年不变的常量,就一直放在Redis里。这样一改造,单个请求走一下成了7个毫秒内。好,这直接不用动外层又进一步提高了10几倍导出性能同时把对硬件的消耗给进一步减少了;
以上,一个例子,它只是5纵中的1纵,本身这个调整就贯穿了:5纵3横。
例子二、API层必须要有限流、模块间必须要有熔断、降级设计
这又是5纵里的一个纵,对不对?来看问题。
问题
商城的购物车页有一个:最快配送时间。这个是根据用户进入购物车时当前门店的经纬度、选购商品的重量、选择的配送方式送到相关的物流方我们假设说:美团,即调用美团这根配送时间预测HTTP接口后返回的一个值,这个值反应到APP上就是:你的订单预计在X分钟内送达。
而美团对于这个接口其实是有自己的限流,或者美团有时在更改时也会产生BUG,或者网络抖动,那么它也会调用出错。不要以为大厂就不会出错。
好,此时这个接口一旦出错,整个购物车卡死,然后购物车卡死还不算它还要卡会员、卡首页、卡订单。
我们来看设计
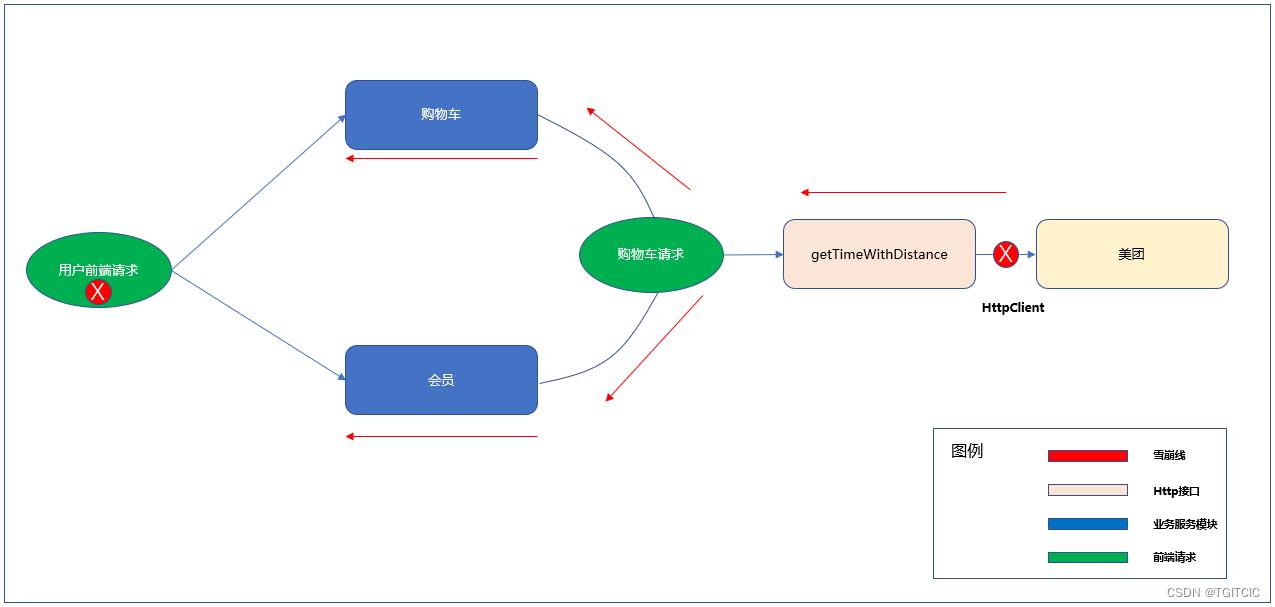
因为这边的getTimeWithDistance接口是在后台用HttpClient发起的。而这个HttpClient没有设超时。各位去看看HttpClient的源码,如果你不设超时,它默认是多少秒?
我告诉你们,我们拿APM看到当这个雪崩产生时,getTimeWithDistance一个个请求都是红色的60秒。
然后系统就开始来了:
- 不管美团或者是说外部发生了什么,如果此时你的HttpClient没有及时断开或者自主断开。它就会反卡本身的企业内部的业务服务模块;
- 业务模块一旦卡住开始雪崩;
- 系统会逐步在5分钟不到内从下向上开始崩;
- 一个购物车至少有会员和购物车这两个模块涉及吧?于是有一些手机用户登录后发觉你家的购物车怎么卡了?再有一些会员发觉连首页都打不开了;
- 最后,崩崩崩,全崩了;
治理手段
甭和我提什么用restTemplate、用什么FeignClient。这和用什么客户端有毛线关系。它归于底层就是HttpClient。而HttpClient有两个基本的参数:
- connection timeout-连接超时
- socket read timeout-处理超时
于是我们的方案诞生了,和例子一一样,分为临时、短期、中长期几个递进的方案。
- 临时方案:直接在代码里把connectin timeout设成1秒(不能再多了,我们平均是千级并发每秒,一秒连接。。。如果在一秒里都建立不了Http连接,这个服务你觉得有用吗?不要看只有1秒,实际这个时间已经给了很多了,我告诉大家我们的系统在千位数每秒并发时每一个API最最多不超过50毫秒,我们单表都是千万级数据的,有800多个表);socket read timeout设成-300毫秒,大家想一下,这连接都已经建立了,返回一个:您的订单预计在45分钟内送达的字样需要1秒吗?全部设完后上线,搞定。然后当HttpClient超时时我们都一个个把它们Log记录下来,事后一次性找第三方配送平台“算帐”;
- 短期方案:因为一旦当HttpClient端当遇到不可测的情况断开后这一块的数据就显示不了,或者显示空白,这对用户体不太好。因此,我们此时用到了微服务设计中的:服务降级。服务都断了,得要有一个“业务兜底”,因此我们在系统的Redis里有一个预设值,if 此处的HttpClient断了 then 取系统预设的一个值:90。即:你的订单预计1个半小时内送达直接返回给前台显示;
- 中长期方案:形成一套规范,万级互联网零售系统本着对一切服务不相信的手法需要做熔断,甚至本系统内服务彼此间都不信任要做熔断。因此最终这边的HttpClient最终被改成了FeignClient,不光可以及时断开,如果在一段时间内它的出错到达了Spring Cloud的一个阀值,那么我们会有一个滑动窗口,在这个滑动窗口内直接由FeighClient的Fault处理机制把Http请求统统挡在web这一层,不放到后台业务模块中去以最大化保护业务模块不被“无意义的请求”所冲击到,同时做好这块业务的:兜底。
这是微服务的考虑,因此我在面试时经常会问一些简历上或者嘴上说了满嘴泡沫的侯选人:你写熟练使用spring cloud,请问你在什么场景下使用spring cloud微服务?是什么事促使你使用微服务?微服务的本质是什么?喏,以上就是例子。
例子三、主数据下发导致海量Http请求同时单根Http请求时间太长,阻塞了整个主数据相关的业务模块
再来一个例子。
这个例子也挺有意思,我们经历了上述两个业务场景后我们都知道了,http请求要控制住,http请求单根不可以无限等、“不行了”就得断开。
于是我们碰到了一个这样的问题。
零售IT系统大都都是从传统ERP开始转过来的,少不了MDM和SAP这种Legacy System的存在。而传统型零售系统的变化是由MDM主数据系统发起的,它每天都会有库存、变价、调价的“跑批处理”发生。
有时一个变动可能会发生在中午或者是下午。此时往往会发生:主数据一下行直接卡死整个前端APP和小程序。
各位如果一直在大厂里或者是来自于ALI和盒马,你们可能没有过这种经历因为它们的系统天生no legacy,但如果你是来自于一些特别又是一些国内巨头型传统企业,我告诉你,这种事真的没有人少碰到。
而我在若干年前问了一圈,竟然高达90%的这个圈子的CTO碰到这种事就是:忍!或者告诉业务:你这种行为最好发生在mid night吧,别发生在早上。
我们知道711超市,它在2016年就已经完成了“第6代门店系统”,还有ALI系的一些先进的新零售门店,它们是一种“走商”,走商即:物品找人而不是:坐等客户自己来找你。因此它们的系统变价格做活动促销经常会伴随着周边的舆情、天气变化而变化。
譬如说:我周边有一个虹口足球场,30分钟后它会举办一场中国女子足球对巴西的赛事。此时系统马上会告诉周边我的那20家店的店内管理系统:给我囤红牛、囤可乐、囤咖啡、囤热狗,50倍于平常日进货的量给我囤。价格采取A+B<C这样的组合促销。以便于多卖、大卖。
看过711-零售的本质一书的读者或许读到过书中:一条街有两边,两边相距不过20米,一边卖的是黄金吐司而另一边就卖的是芥末吐司。
为什么?因为就算是同一条街,街的两边的客流情况也是不一样的,如果同一样的价格、同一样的货品那企不是自己本企业内在搞同质化竞争吗?新零售为了消除这种同质化竞争就势必要搞差异化竞争。而差异化竞争中有一种打法叫:实时变价。
好家伙,现在实时变价好不容易这个能力我有了,然后我发觉我们的系统是以下这样的设计,来看,这不死菜了。

- 传统的零售都有这么一块Legacy。我碰到过的是全国排名第一第二第三的巨型超市在数字化转型一开始时都是这种架构,这是没办法的。因为这些超市都是世界历史著名、历史悠久的,它们必须要有SAP,否则都不能上市;
- 而SAP因为不是互联网系统,它的TPS根本不是为中国式的TO C端设计的,因此它只能跑批;
- 因此传统巨型超市的这种我们叫:主数据价格库存变动都是发生在凌晨的,这是因为其一,它的业务模式没有711或者是我们一些新零售超市从一开始根本上就是以:走商的目标来设计的,因此我们许多新零售一开始就可以做到“实时、随时”变价。而传统超市一天有一次、两次变价已经不得了了,而且这个变还是高层决策层一帮“坐商”们拍脑袋决定的。现在因为业务需求要做成实时变价,那么对于这些老超市来说就等于加大跑批的频次而己(他们自以为这样可以解决);
- 频次加大吧,没事。每个门店我算他10万SKU(我已经算少了)、全国1,000家店、每个店6个渠道。轰一下,10万*1,000*6的随时随地对着你的业务系统来这么一下。当然,这一次设计者们因为经历了上面两个例子了,所以减少了HTTP请求、他们还固定住了HTTP请求的数量。结果发觉,HTTP请求的数量一旦固定住了,这个主数据下行后零售的线上或者说是全渠道交易系统是要给到SAP一个回执的,这个回执是一种古老的XMLHTTP即基于?wsdl的WebService的SOAP请求的Response。是业务交易系统处理完一条请求通过SOAP请求回CALL Legacy System的。我们知道Http请求一来一回都是连接。现在零售交易端的并发、性能被我们搞了很高,但是Legacy的频次不可能达到这么高的频次的,因此一样,也设超时。如果Legacy没有响应多少秒内(4秒内),我们就主动断开这个Http连接;
- 这样似乎图上的这些雪崩点就不会发生。但是熔断后我们又发觉陷入到了一个更巨大的坑,那就是很多Legacy特别是SAP,它是一个强业务幂等的系统,我传给你东西后你回执因为你业务系统要讲究高性能熔断了,我就认为这一条数据没有给你,这造成了财务、库存的不平帐。哎油,于是乎业务系统是快了,天天日结财务、物流、仓储部门拉着你IT天天下了班对帐,因为熔断后帐不平呀。而且一些Legacy System又是强交易业务幂等,它不允许你有Retry。这把一群IT做的天天苦哈哈,又不得个好;
此时,IT就陷入了一个:如果我不断开或者我不把这么大的一个数据去做限流排队固定HTTP线程处理,我的业务模块就会因为每小时或者随时的一个主数据到SAP到业务系统的变价行为被打爆系统HTTP请求并造成HTTP请求泛滥的梗。如果断开,我又面临着库存、财务帐不平天天要007,累死累活,这还做什么IT呢!
面对这样的场景,我们怎么办?
来看治理
其实这个问题在于以下这么几点:
- Legacy System那确实会产生这么大的请求,人家没用socket给你送过来已经不错了,笔者亲眼见证过排名前5的巨型零售企业在2019年线下和线上交互用的是socket,对他们来说就是一个大for循环给你把数据“推”过来,管你吃不吃得下。
- 限流就不该对Legacy System去限,它推过来后当时系统立刻就可以知道多少条或者说批次号,马上系统当时不做任何处理就给回一个“己成功处理”的标志。因为人家保证无误的推过来了,你说你要等我这的系统处理完再给你回执这是矛盾的。人家推给你一条不漏已经尽了义务,至于处理不处理的完是你系统自己的事,对你来说就是“铁定”且“必须”处理完的,好比用户把钱存进ATM机了就完事了,至于ATM是不是可以许诺在2小时内到帐那是银行需要解决的问题,不要把这个问题“甩到”或者说:转嫁给别人;
- 限流不能限,但又要限。同时我们要加大数据处理的速度,因为之前的例子里我们有限流、有熔断,而到了这个例子我们是即要聪明的限、又要熔断、同时还要加快系统处理速度和处理容量;
- 基于这么个熊掌和鱼兼得法,我们就和Legacy说:这样吧,你下发主数据的接口换一个,这个总不难。于是我们新做一个用来接收主数据下发的接口给到了Legacy,这个接口好玩了,直接接到一个Http请求当即什么都不做就给主数据来一个:已确认收到的回复。然后异步把数据先往Redis里整,然后我们用message机制,去启动一个xxljob,这个XXLJOB是走数据sharding的,我们使用了hash一致环,这样xxljob可以并行的使用6-8甚至12个幅本的xxljob进程,每一个开启5个线程,去处理redis里的数据把这些数据进行处理和DB落盘到我们自己的零售业务交易系统内。同时因为这个数据我们已经落下来了,因此熔断、限流发生时,由于这个业务动作已经“转移”到了我们自己的系统内了,因此要on error retry就来得简单了;
- 最后一步,就是把线下门店的POS机直接拿API长到我们的Redis里。这样也可以少一步在业务交易系统把legacy的变价、库存再来一轮Http推到线下的POS系统(没错,绝大部分零售企业除去Legacy System还有单独的POS System,它也是一个Legacy)。
经过上述这么一个改造,我们让Legacy的改动减少到最小的量,同时因为有了sharding机制它扩宽了我们并行处理数据的处理能力,同时又使用了微服务熔断、限流防止我们的业务模块被来自于TO B的流量打爆,又可以做到on error retry。
瞧,以上的三个例子,就是我说的:虽然它只是属于五纵中的一纵,但是每一纵依然会把五纵三横全部给“滚”一遍的典型场景。
HTTP治理需要形成规范而不能每次来一个案例处理一个
因此这一纵衍生出来了一个“横”。
即:横三、代码设计规范包括:
- Java编码规范;
- 多线程开发规范;
- Redis使用规范;
- Http使用规范;
- MQ使用规范;
- 异步跑批设计编码规范;
- 封装规范;
- 系统日志输出规范;
- 代码安全规范;
- MVC规范;
- 长事务处理设计规范
- 所有规范的日常、定期及抽查Review机制
其中我摘选几条HTTP使用规范给各位作参考:
- 对于老的功能模块已经用了http client的,需要全局共用一处Http Util,这个Http Util必须在finally块中套一个trycatch块再去close;
- 对于使用的是CloseableHttpConnection的,必须把这个CloseablehttpConnection做成一个全局带双重校验机制的单例,所有业务代码里永远只getConnection而不可以去new;
- 超过50次同业务http接口如: getUserById调用,不得使用for循环去调用http接口,而是要用for循环把50条内容组成一个json array,一次通过新增的http接口送过去;
- 线程数必须恒定、固定,不得出现什么线程数integer.MAX_VALUE;
- 对于兼顾海量HTTP请求必须使用sharding机制;
- 任何跨模块间的Http请求必须熔断,最低要求是必须每一个http请求要设connectin_timeout和socket_read_timeout,且熔断后一定要考虑业务兜底或者是on error retry;
这只是20多条里的重要6条,然后把规范像PUA、洗脑一下没事拎出来和全体开发定期的Review、宣导,以把这些“血得来的教训”深入到每一个程序员的基因中。
要改变码农必须从“基因”下手改造。这就是我们的技术管理手段。
结束本此篇章!
以上是关于高性能零售IT系统的建设06-当应对大量HTTP请求时兼顾性能处理速度的架构设计的主要内容,如果未能解决你的问题,请参考以下文章