高性能零售IT系统的建设02-对RabbitMQ乱用的治理
Posted TGITCIC
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高性能零售IT系统的建设02-对RabbitMQ乱用的治理相关的知识,希望对你有一定的参考价值。
开篇
上文我们讲述了HTTP乱用、不规范引起的血灾。本文继续讲的是“血光之灾”的内容。好像前两篇怎么都这么“重口味”?
这是因为我要用两篇同样的同内容,它们都属于:涉及到的技术问题相当的简单,但在百人开发团队中也是最容易失控的并结合着真实案例,让大家体会到:技术不能单纯从技术角度去解决问题。在企业级开发、架构和技术管理以及特别是你已经把“屎山”放到了生产环境后所带来的各种复杂情况下如何去有效聪明治理、调优并且要在根本上避免这一类问题时是怎么样的一种手法。此时技术管理之美和架构之美才能真正体现出来。并以此二篇引出后续“监控方法论”和APM使用方法论。
问题的发现
我们生产的MQ对于大厂来说算是mini me一类的了,但是对于除大厂以外的应用,我们的MQ算是很强大了。我告诉大家我们的MQ有多少生产集群呢?
一度达到过3个环境几十台128GB内存、16C CPU的集群。
这个对于千级并发来说简直算是“豪华套餐了”、绰绰有余了。而就在于这样的一个RabbitMQ集群环境下,我们竟然发生了这样的事。
问题的表象
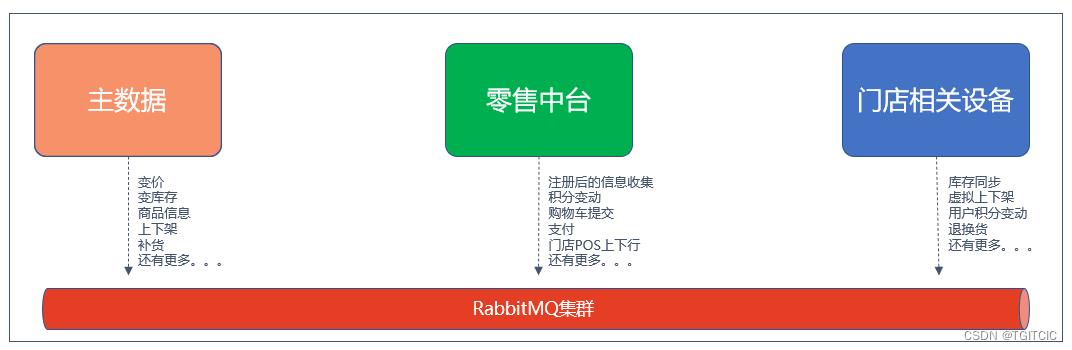
一个零售系统,它所要用到的MQ场景远不止上面几处,我只是列出了一些非常通用的场景,实际多达几百处。
特别是下面这个结构:
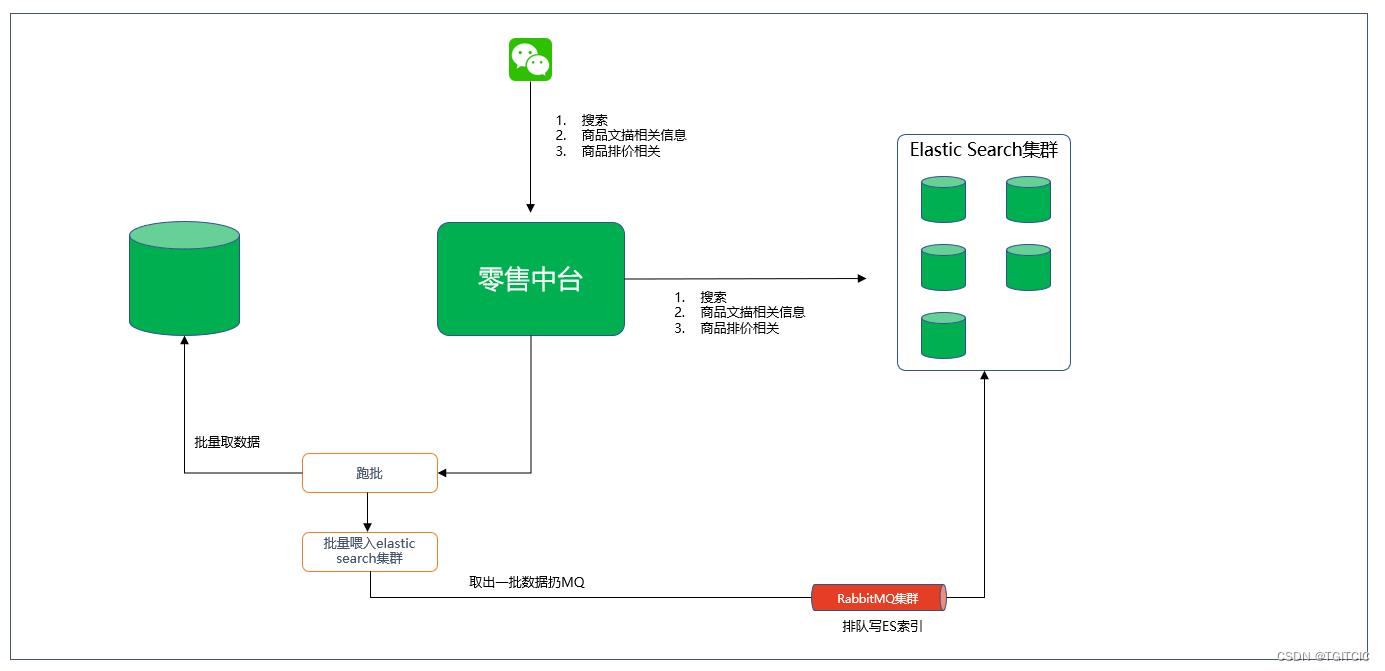
这是一个通用的零售电商上用于小程序上做商品相关信息搜索时的架构。
由于传统大型零售很少像互联网大厂作法,它的主数据变动不是经常变的。大厂电商几乎无主数据概念,主数据就是指有任何的数据元信息改变它是要走企业级审核流(都内带workflow甚至是bpm引擎)的。有时一个黑人牙膏的变价会被主数据里的审核流一直报到COO手里进行审批。这是经营理念上根本不同造成的系统结构的不同,必竟业务导向决定技术架构。而业务运营经营理念的正确性不在于我们的讨论范围,我只能用:百花齐放,各自争鸣来形容业务经营决策上的一些事。
因此传统零售都这么干建立索引供小程序或者是前端APP搜索这件事:
- 每天只会有一次全量变动,变动后就放到中台DB中,中台在凌晨做一次ES前端用于小程序搜索用ES内主数据索引变更。
- 主数据下行时,有一个多线程脚本去DB里取出数据来往MQ里扔。
- 中台有一个consumer,一旦收到了MQ消息就去把这些数据从队列里拿出来再往ES里去建索引。
我们啊,发觉这个建索引的过程越来越长、越来越长。动不动一个就10个G的数据,建索引要用近1小时。
建立索引耗时多也就算了,关键是这个过程有增长的趋势,每天这个过程比之前一次建立耗时会多个额外5分钟。
更夸张的是我们还有增量变动,增量变动指日常的商品的上架、下架。上架后商品要在小程序里被搜索得到、下架后这个商品要在ES里把相关商品去除那么小程序就搜索不到。
然后发觉一开始这种“业务增量”操作从点下“提交”按钮后,5分钟内数据会在小程序里生效,随着系统运行时间变长,这个增量过程每天虽然可能只有个7~8次,但每一次增量的数据生效时间也开始在变长了,这个数据从提交到生效的过程开始从5分钟数据生效变成了15分钟数据才生效到20分钟数据才生效,再后来干脆到了1小时这个增量数据才生效。
同时,DevOps给了我一个主动告警。就是我们的RabbitMQ在Grafna里的监控,每小时都会增长1,700多个consumer和连接。
短短2周,这个MQ里的Connection已经堆积了达7位数了啊?内存使用情况是所有的MQ每一个集群节点的内存使用量达到了惊人的17个G,按照这个势头,3周半左右就要进行一次MQ集群的重启以释放一部分内存。
另外就是有发觉在MQ的监控界面里显示出来有不少队列已经产生了“archive”或者是“unack”状态了。
虽然我们的业务上是有on error retry来做幂等,可是这恐怕就是有一些增量业务动作为什么变得数据生效时间越来越长的主要原因。因为unack的数量太多已经代表了MQ消费出现了严重的“堵塞”。
特别是有一次我们观察到了unack的内容达到了7位数,即有7位数消息没有被消费而被丢弃了。
这个问题引起了我高度重视。
排查问题
幸好,这次业务上还没有发生灾难,但是我预感到它离灾难性后果仅仅在2-3周之隔了。就算我们说每三周左右我选择一个凌晨时间进行全量重启,也能这样让系统一直挺着。可是由于unack消息的堆积,它会让一些业务增量动作的时间变得无法忍受的过长而最终被投诉。
比如说,我们一开始是商品目录的改变到生效从3分钟生效变成了15分钟。而我们还有一些叫“打折促销”商品或者是优惠券的发放,也是走的MQ,这个时间已经变成了22分钟一次数据才生效。这已经开始影响业务了。
这是不能接受的。于是我们立刻开始着手排查。
这个系统我接手时是一个70%以上闭源的产品,它的一些组件都是一个个的jar。在业务实现功能时都只是一个个的set/get动作。
因此我再一次怀疑到了底层组件,然后直接JAD反编译,打开MQ相关封装查代码。
这一查,哦。。。又是同类“重口味”问题。
如我上文所述,这个东西它是由比较早的技术架构逐步升级而成,但是底层相关的人员水平没有那么的高甚至做事三心二意或者干脆就没有达到知其然更要知其所以然的架构、研发级别。这导致了底层MQ这一块代码是这样设计的:
- 由于在设计这一块底层架构时还没有spring,因此使用了rabbitmq的纯编码手段。同时也正因为没有使用spring相关功能,底层开发者自以为为了解决MQ传输中的业务幂等和on error retry,他就干脆来了一个on error create a new MQ connection。而on error create a new MQ connection没有做好却变成了:each call create a new MQ connection;
- 这还不算完,在原有一部分产品级代码里即有用mq底层组件也有自己从mq声明语句从头到尾写一套mq建立连接、通信、传数据、消费的。而这一些代码都漏了一个finally块里close;
这个太搞笑了。
几十台MQ、每台MQ的服务器的性能这么高,我日行亿条消息都不该成问题的,怎么就这么快时间内存、队列都满了呢?原来是这个道理。
唉呀呀。。。这个太逗了。我当时看完底层后傻了半天。
这个和之前那个HTTP泛滥问题一样,好在它遍布不多,遍布在8个功能模块中,但这8个功能模块全部是主数据、流量端相应的功能啊,又是影响主流程的功能。
如果说上一次我们解决HTTP泛滥还有一点时间,现在对于我们来说就是三周左右要来一次MQ重启。这个莫明奇妙的重启肯定是要被老板骂的,因此其实我们只有3周时间去改这一块,因此从紧急程度上来说更严重。
于是我们又使用了HTTP泛滥治理时的老手法,只不过这次我们的手法更敏捷、更聪明了。
问题的解决和治理
说实话,3周时间要消灭掉这么多遗留的点还要外加测试走全回归,我们时间是不够的,最近一次回归的时间也要4周以后。
怎么办呢?
重写一个MQ组件甭!
不去动MQ底层封装的接口声明,连进出参都一模一样,别去管有些有没有用,全部保持原样,但是把内部代码整个给全部重写了。
在finally块中把close带上,别忘了也要包上try catch。
然后我们按照问题的严重情况发觉可以这么去做这个聪明、敏捷的实施:
- 主数据索引、增量索引处问题最严重,需要立刻改掉,这涉及到只有2个功能模块,而且影响到的功能就是全量索引、增量索引。这块优先第一直接1天内改掉,然后在白天采用蓝绿发布无感的热更;
- 然后发觉each call will create a new connection处最多的是用户积分变动。因为用户下一单或者退一单都会影响到:积分变更,并且要把积分变更信息同样用MQ要同步到另一个CRM一类的系统中去,每一次请求就会create一个新的mq connection然后就永远僵尸在了rabbit mq集群内了。不用说,这一块只有一个业务模块。但是由于代码中即有用到了底层MQ组件又有开发自己从头开始写了一套代码,都是复制粘贴,因此错的都是一样的地方。我们把它改成一周一发版,使用蓝绿发布、热更;
- 然后再把商品优惠打折信息的建索引和增量索引的代码做了梳理,发觉更好玩的地方在于为什么优惠打折信息建索引比增量索引的代码更耗时?是因为优惠打折信息的索引建立的代码是一些开发copy了商品增量索引的代码,而copy时把了个商品优惠打折信息建索引的队列和增量索引的队列给同名了。说白了就是不同业务的消息走了同一个MQ Topic。于是就出现了,增量索引还没有走完后面跟着优惠打折的消息就一直排不上队,这太搞笑了。改改又很快;
- 再依次把用户、把商铺、把其它的一些按照业务优先级一个个折开了改和上线;
在以上这样的折分过程中我们还伴随着有业务代码的开发呀?因此下了一道这样的规范:
新功能开发如果用到MQ必须使用spring boot的rabbitmqTemplate而不得用底层的封装的mq组件。有违反者直接就警告处分了。这是因为rabbitmqTemplate至少你可以不用去关心它在被调用完了万一忘记去finally块里关闭而引起僵尸道长。。。哦,不对,是僵尸进程。
用到mq组件的,在提交测试环境前做一次maven pom.xml的升级。因为我们改造过的mq底层组件已经在原有的版本上做了0.0.1+的一次升级。
问题解决后取得的效果
前前后后,我们使用了6周时间,把MQ这一堆问题给改了。
在最后一批MQ问题优化后、上线后,我们的生产MQ的情况从原来直接保持着7位数connection数量并且每小时还往上不断的涨1700个连接、1700个连接。。。这样的趋势得到了“止血”,现在恒定在了3,000个队列左右。内存消耗从17个G平均开销并且一直还不断的每小时往上涨个几兆恒定在了全天平均3GB。
整个MQ集群的硬件呢,缩了10倍。
而此时我们整体的业务量、流量已经翻了3倍了。
各位看看这个事,本来一个MQ集群要面临快爆了。现在呢?业务量翻三倍,连接数恒定在3,000个,因为全系统真的只有3,000个MQ连接是需要用到的,哪里来什么7位数连接还不断的上涨?以为这比新浪微博的流量还猛哈?可能吗?
内存使用上的saving呢?从本来的平均要用掉17个G每小时还在往上涨缩成了恒定在3G,上下变动不超过550K。
这么简单的一个问题,它引起了多大一块面积的“溃烂"?其实在第一期我们把主数据问题先行上线解决后就已经把MQ原来的用量下降了一半了。改改并不难。
有人一看,哇,这一块提升了不得了。我告诉你:哇,一点没有技术含量,只是一个1+1=2的问题而己。
关键的还是在于:
- 好在及时发现问题
- 排查手段到位
- 梳理分析到位
- 项目折分科学
只有综合了这些手段我们才能取得这个漂亮的“果”。
因此呢,我们结合之前HTTP泛滥和此次MQ治理这种手段归纳成两点,以后再有类似的事发生我们可以做到在业务结果被影响到前就自我发现自我优化掉。因为我已经有预感到,更夸张的事还会在后头呢!
- 完善监控
- 聪明的折分、敏捷的上线手段
因此我才说,我用这两个“重口味”事件引出了后面的连续两篇章节:监控方法论和APM的作用。
而我们把这种聪明的折分、敏捷的上线总结成了毛主席在布署抗美援朝战略时说过的一句话:零敲碎打牛皮糖。
零敲碎打牛皮糖历史来源:
因为当时美军的装备特别的好,1951年5月,毛泽东听取志愿军参谋长解方和第3兵团司令员兼政治委员陈赓关于朝鲜战场的情况汇报后,根据志愿军入朝后连续五次运动战的经验和美英军队的作战特点,对志愿军应采取的作战方法作了明确指示。他说:“志愿军总的政治任务是轮番作战,消灭美英军九个师(几个杂牌旅营全体在内),则可解决朝鲜问题。打法上同意彭总提出的不断轮番各个歼灭敌人的方针,即‘零敲牛皮糖’的办法。每军一次以彻底干脆歼灭敌一个营为目标。一次使用三四个军(也可多一点),其他部队整补待机,有机会就打。如此轮番作战,在夏秋冬三季内将敌人削弱,明春则可进行大规模的攻势。”
其实,我在HTTP泛滥问题时当发现它涉及处达2,000多处点,影响到了几乎所有的主流程时我的脑袋“翁”一下就炸了,就知道摊上了什么个事了。因此我相当的郁闷,心中暗自叫苦,当晚回到家后看电视正好看到抗美援朝相关纪录片,里面正好说到了这个“零敲碎打牛皮糖”战略,一下就把我的脑子给点亮了。
所以才想到了这么一种“折碎”了的手法。两次重大危机的结果也正说明了这种手法是相当有效的!
以上是关于高性能零售IT系统的建设02-对RabbitMQ乱用的治理的主要内容,如果未能解决你的问题,请参考以下文章