浅谈SQL执行计划优化(GBase8s篇)
Posted 麒思妙想
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅谈SQL执行计划优化(GBase8s篇)相关的知识,希望对你有一定的参考价值。

在日常开发的过程中,对于 SQL 的优化,一直是一个比较有挑战的事情,所谓工欲善其事必先利其器,那么今天我们就来看看 如何查看GBase8s 的执行计划,并有哪些调优手段。
执行计划优化
RBO
RBO(Rule-based optimization)所谓基于规则优化,就是指通过一系列预先定义好的规则(Rule)对逻辑计划进行等价转换,以提高查询效率。减少参与计算的数据量,降低重复计算的代价。
优点:RBO相对于CBO而言要成熟得多,常用的规则都基于经验制定,可以覆盖大部分查询场景,并且方便扩展。
缺点:不够灵活,毕竟这个阶段对物理上的特征(如表的底层存储形式和真正的数据量)还没有感知。
常见手段
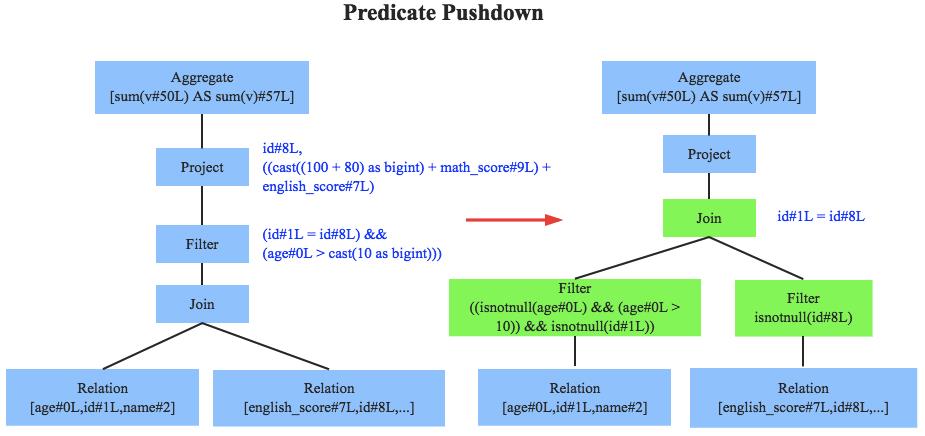
- 谓词下推 Predicate Pushdown
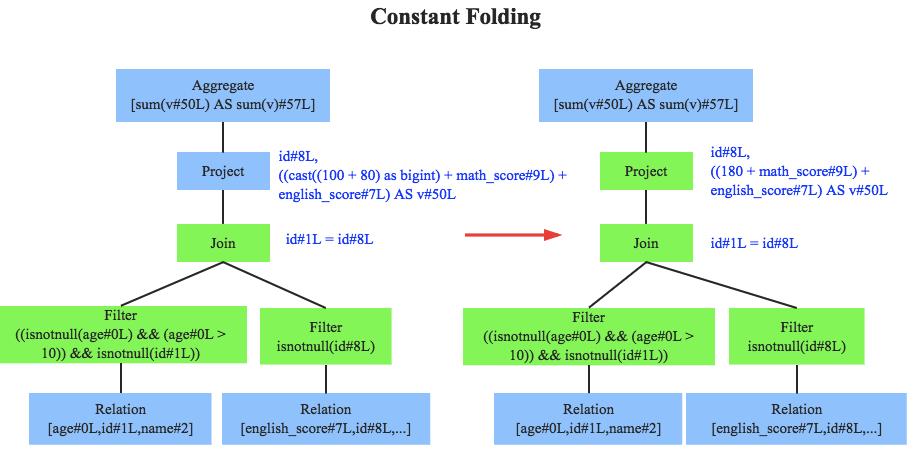
- 常量折叠 Constant Folding
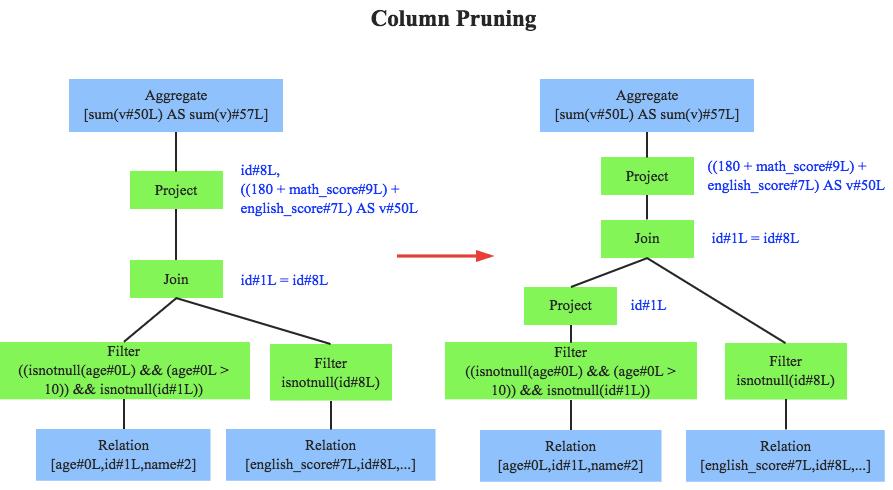
- 列裁剪 Column Prunin
CBO
CBO(Cost-based optimization) 原理是计算所有可能的物理计划的代价,并挑选出代价最小的物理执行计划。其核心在于评估一个给定的物理执行计划的代价。
物理执行计划是一个树状结构,其代价等于每个执行节点的代价总合
而每个执行节点的代价,分为两个部分
- 该执行节点对数据集的影响,或者说该节点输出数据集的大小与分布
- 该执行节点操作算子的代价
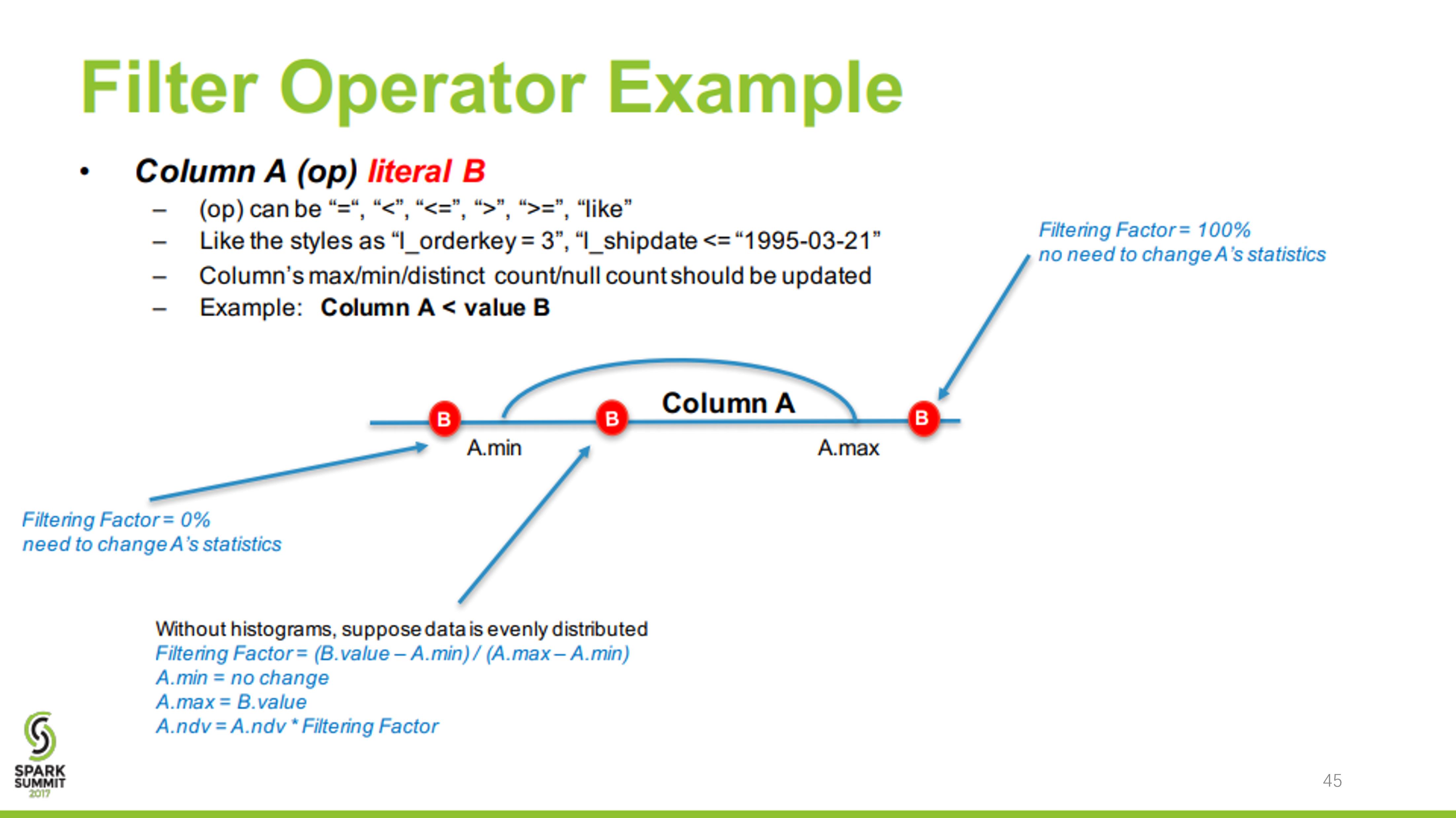
每个操作算子的代价相对固定,可用规则来描述。而执行节点输出数据集的大小与分布,分为两个部分:1) 初始数据集,也即原始表,其数据集的大小与分布可直接通过统计得到;2)中间节点输出数据集的大小与分布可由其输入数据集的信息与操作本身的特点推算。
所以,最终主要需要解决两个问题
- 如何获取原始数据集的统计信息
- 如何根据输入数据集估算特定算子的输出数据集
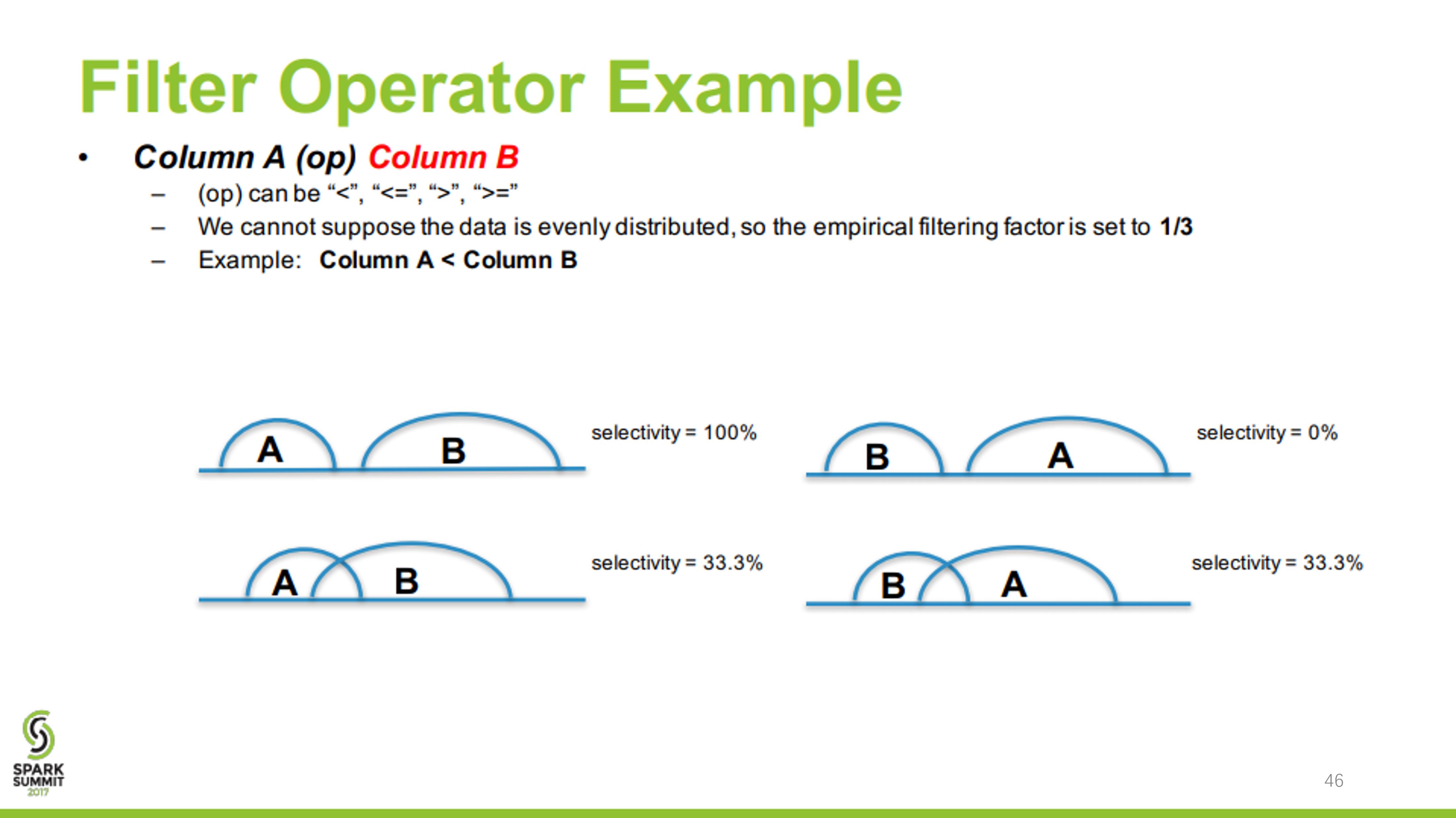
如何查看GBase8s的执行计划
开启并配置执行计划
> set explain on;
Explain set.
> set explain file to '/opt/GBASE/gbase/aaa.out';
Explain set.
> select o.oid,o.counts,o.memo,i.iid,i.name,i.catalog,(1+1+i.iid) from order_table as o inner join item_table as i on o.iid = i.iid where i.iid < 10;
oid 1
counts 10
memo
iid 1
name fifa2022
catalog game
(expression) 3
1 row(s) retrieved.
查看执行计划
[jacky@localhost gbase]$ cat aaa.out
QUERY: (OPTIMIZATION TIMESTAMP: 02-17-2022 22:44:39)
------
select o.oid,o.counts,o.memo,i.iid,i.name,i.catalog,(1+1+i.iid) from order_table as o inner join item_table as i on o.iid = i.iid where i.iid < 10
Estimated Cost: 4
Estimated # of Rows Returned: 1
1) gbasedbt.o: SEQUENTIAL SCAN
Filters: gbasedbt.o.iid < 10
2) gbasedbt.i: INDEX PATH
(1) Index Name: gbasedbt. 299_5
Index Keys: iid (Serial, fragments: ALL)
Lower Index Filter: gbasedbt.o.iid = gbasedbt.i.iid
NESTED LOOP JOIN
Query statistics:
-----------------
Table map :
----------------------------
Internal name Table name
----------------------------
t1 o
t2 i
type table rows_prod est_rows rows_scan time est_cost
-------------------------------------------------------------------
scan t1 1 1 1 00:00.00 2
type table rows_prod est_rows rows_scan time est_cost
-------------------------------------------------------------------
scan t2 1 1 1 00:00.00 0
type rows_prod est_rows time est_cost
-------------------------------------------------
nljoin 1 1 00:00.00 4
好了,今天我们就先分享到这里,欢迎大家与我交流。
参考资料
本文中图片大部分引用自Spark Catalyst 介绍
https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=158869574
https://www.jianshu.com/p/410c23efb565
以上是关于浅谈SQL执行计划优化(GBase8s篇)的主要内容,如果未能解决你的问题,请参考以下文章