DSE精选综述 | 关于提升数据库优化器:基数估计代价模型计划枚举
Posted CCF数据库专委
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DSE精选综述 | 关于提升数据库优化器:基数估计代价模型计划枚举相关的知识,希望对你有一定的参考价值。
Data Science and Engineering (DSE)是由中国计算机学会(CCF)主办,数据库专业委员会承办,施普林格·自然(Springer Nature)集团出版的开放获取(OA)期刊。本篇文章精选自DSE最新一期发文。
文章介绍
数据库优化器是关系型数据库以及一些大数据处理引擎的核心部件。给定一个声明式查询语句(例如SQL语句),优化器能够为其找到一个最优的执行计划并将其传给执行器执行。用户只需要关心如何写出符合查询需求的语句,而不用关心这些语句高效地执行。
现有的系统几乎都采用了基于代价的优化器模型,其整体核心部件如图1所示:基数估计、代价模型以及计划枚举。基于统计信息和若干假设(如数据分布、列的相关性、连接关系等),基数估计得到一个中间算子产生中间结果行数。代价模型可以看作是一个复杂的函数,根据当前的数据库状态(如预设并行执行参数等)和中间结果的行数来评估一个给定物理执行(子)计划的代价。计划枚举主要用来解决连接执行顺序的问题以及基表访问方式。其在一个计划空间中通过枚举执行计划,调用代价模型计算其执行物理执行代价,最后返回计算代价最小的执行计划。
图 1.基于代价的物理优化
理论上,只要提供了准确的基数轨迹和物理计划执行代价,并且计划枚举可以有效地在巨大的搜索空间进行,该架构则可以在合理的时间内制定最佳执行计划。但实际上,基于代价的优化器仍然不能为一些“复杂”查询找到最优的执行计划。
为了提高优化器的能力,数据库领域已经发表了大量的相关研究工作进展。在本综述中,作者对现有的研究工作按照上述的三个部件进行总结并提出可能的进一步研究的方向,供广大研究学者参考。
基数估计
现有的基数估计方法主要包括三大类别(图2)。现有大部分数据库都是基于Synopsis的方法(如直方图和CM-Sketch等)并借助采样的方法进行进一步的修正。随着AI技术被广泛使用,研究者们分别提出了基于历史查询信息的监督学习方法和基于对数据分布的学习的非监督方法。上述三种方法有各自的优缺点。例如:基于Synopsis的方法采用某一数据结构来拟合一个表上的数据分布,因此基于Synopsis主要运用于单表(多个过滤条件)上的基数估计。通过对不同的表按照一定采样方式采集元组,进一步利用这些元组进行基数估计。采样方法可以反映不同表之间的关联关系。但如何高效地在一个规模较大的数据集上进行采样、当底层数据发生更新后如何进行重采样、如何支持非等值连接仍然是需求解决的问题。基于学习的方法在现有文献的实验部分表现出较传统方法更好的准确性。但这些方法仍然缺少一个完整的实验对比(比较各自的优缺点、训练时间、适用场景等)。其次,这些方法都受到查询负载变化(监督学习方法)和数据变化(监督学习和非监督学习)的影响。最后,如何将这些方法整合到现有的系统中目前仍然没有方案。
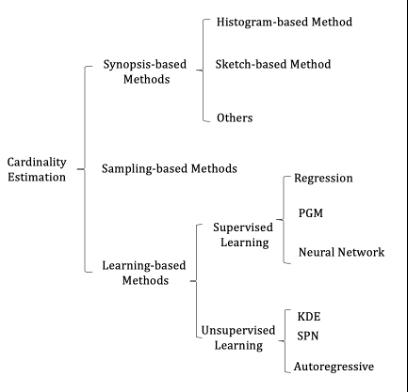
图 2. 基数估计的方法分类
代价评估
如图3所示,现有的代价评估研究工作主要分为三大类。第一类是提升现有代价模型的准确性。该类研究主要是进一步挖掘影响代价模型的因素。例如:在不同的哈希连接实现方式中,内存使用方式对代价模型影响的进一步细化。第二类方法试图寻找代价模型的替代者,目前主要用基于学习的方法来替代代价模型,且现有方法均为基于历史查询信息的监督学习方法。第三类方法是对单个查询的性能评估,这类方法同上一类方法相似,但其输出为一个查询的执行时间估计。利用学习进行代价估计面临着与基于学习方法的基数估计相似的问题,包括如何进行模型更新以及如何整合到现有的数据库系统中。其次,现在许多用户均采用了云数据库,如何使得用户的查询响应时间和用户的实际资源消耗(成本)取得平衡也是一个潜在的方向。这需要对代价模型引入新的维度,即资源消耗估计和计价模型。

图 3.代价估计的方法分类
计划枚举
计划枚举主要关注如何处理表连接问题,即如何找到一个最优的表连接顺序。现有的工作主要分为两类:(1)基于传统方法,如何解决大表连接的问题。这类方法的基本思想是在找到若干表的连接方式后,将其打包看作一个表,进一步同剩余的表进行连接顺序确定。(2)基于学习方法的多表连接顺序确定,这类方法大部分采用了强化学习的方法。如图4所示,在强化学习的每一步中,会根据当前的状态(S),采用一个连接动作(a)。当一个完整的连接顺序形成后,调用优化器评估当前计划的代价作为收益来训练强化学习模型。
基于学习的方法在现有研究的实验中比传统方法表现出了更好的性能,但是这些方法仍然存在需要解决的若干问题:(1)如果表模式发生改变或者数据发生变化,模型如何更新;(2)当前方法仅适用于内连接,如何推广到其它连接方式;(3)同前两个模块一样,如何整合到一个实际系统中也是一个潜在问题。
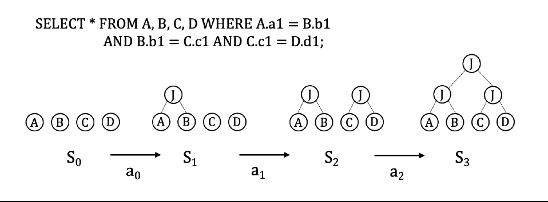
图 4.基于强化学习的连接顺序确定
作者简介
兰海,皇家墨尔本理工大学博士生,主要研究方向为数据库索引设计和时空数据处理。
彭煜玮,武汉大学副教授,2008于武汉大学获得博士学位,主要研究方向包括数据库系统、制造业大数据、族谱数据、数据水印等。
以上是关于DSE精选综述 | 关于提升数据库优化器:基数估计代价模型计划枚举的主要内容,如果未能解决你的问题,请参考以下文章