AI绘画火了!一文看懂背后技术原理
Posted 腾讯云开发者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AI绘画火了!一文看懂背后技术原理相关的知识,希望对你有一定的参考价值。
图片](https://img-blog.csdnimg.cn/img_convert/9dd409913876c1d1f66964586a6c75fd.gif)

导语 | 近些年AI蓬勃发展,在各行各业都有着不同方式的应用。而AI创作艺术和生产内容无疑是今年以来最热门的话题,AI创作到底发生过什么,原理又是如何,是噱头还是会有对我们有用的潜在应用场景呢?我们旨在深入浅出的尝试回答这些问题。

AI创作怎么火了?
今年开始,文本描述自动生成图片(Text-to-Image)的AI绘画黑科技一下子变火了。很多人对AI绘画产生巨大兴趣是从一副AI作品的新闻开始的。这幅由MidJourney生成的数字油画参加了Colorado博览会的艺术比赛,并且获得了第一名。这个事件可以想象的引起了巨大的争论。(难道300刀的奖金撬起了3千亿的市场?)

Jason Allen’s A.I.-generated work, “Théâtre D’opéra Spatial,” took first place in the digital category at the Colorado State Fair.Credit…via Jason Allen
Disco Diffusion是今年2月爆火的AI图像生成程序,可以根据描述的场景关键词渲染对应的图片。今年4月,大名鼎鼎的OpenAI也发布了新模型DALL-E 2,命名来源于著名画家Dali和机器人总动员Wall-E,同样支持Text-to-Image。在年初的时候,Disco Diffusion可以生成一些有氛围感的图片,但还无法生成精致的人脸,但很快到了DALL-E 2后就可以非常清晰的画出人脸了。而现在到了Stable Diffusion在创作的精致程度和作画速度上更上了一个新的台阶。

Disco Diffusion: Mechanical arm with a paint brush and a canvas by Li Shuxing and Tyler Edlin

DALL-E2: 将Johannes Vermeer 的名画“戴珍珠耳环的女孩”转换生成不同的面孔

Stable Diffusion: a beautiful painting of a building in a serene landscape
2022年8月,被视为当下最强的AI创作工具Stable Diffusion正式开放,这无疑进一步给AI创作带来了最近的火热。通过网站注册就可以使用,提供了方便简洁的UI,也大大降低了这类工具的使用门槛,而且效率高,图像质量好。而如果不想花钱的话,Stable Diffusion还正式开源了代码、模型和weights,在huggingface上都可以直接clone和下载,部署到GPU上就可以随便用了。huggingface上同时也已经有了diffusers库,可以成为调包侠直接使用,colab上也都有现成的notebook example了。也因此热度,推出Stable Diffusion的AI公司StabilityAI完成了1亿美元的种子轮融资,公司估值达到了10亿美元。
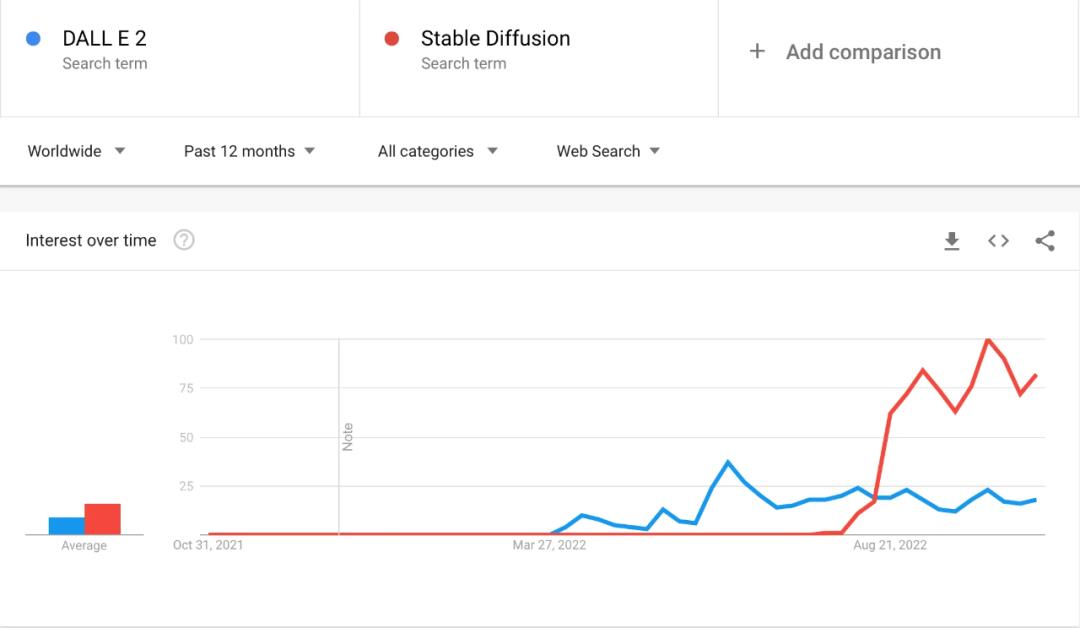
Stable Diffusion开源后的搜索热度已经保持两个月了
和机器学习刚开始火的时候一样,AI生成技术也并不是凭空出现的。只是近一两年以来,作品的质量和计算速度日益快速提升,让我们忽略了AI绘画同样悠久的历史。
 历史发展
历史发展
AI绘画在计算机出现后不久就已经开始有了最初的探索。在70年的时候艺术家Harold Cohen就已经创造了程序“AARON”进行绘画,而不同于现在的黑科技,当时AARON是真的去操作机械臂来画画。Harold对AARON的改进持续了很久,80年代的时候,ARRON可以尝试画三维物体,并且很快就可以画彩图了。但AARON没有开源,所以它学习的是Harold本人的抽象色彩绘画风格。2006年,出现了The Painting Fool,有点类似AARON,通过观察照片提取颜色信息,使用现实中的材料进行创作,所以同样电脑程序通过学习信息就行物理绘画的方式。

现在我们说的更多的“AI创作”的概念,更多的指的是基于Deep Learning模型进行自动作图的程序,这种绘画方式得益于近些年计算机软硬件的高速发展。2012年两位大神Andrew Ng和Jeff Dean进行了一次实验,使用1.6万个CPU和Youtube上一千万个猫脸图片用了3天训练了当时最大的深度学习网络,生成了一个猫脸。在现在看来这个结果不值一提,但对当时的CV领域来说,是具有突破性的意义的尝试,并且正式开启了AI创作的全新方向。

2006年,李飞飞教授发现了很多研究工作在AI算法方面忽略了“数据”的重要性,于是带头开始构建大型图像数据集 - ImageNet,也因此图像识别大赛由此拉开帷幕,三年后李飞飞团队发表了ImageNet的论文从而真正发布了ImageNet数据集,给AI创作提供了强大的数据库。同样2006年,Geoffrey Hilton团队实现了GPU优化深度神经网络的方法,从而“深度学习”这个新名词的概念被提出,各种Neural Networks的技术手段开始不断出现,深度学习的发展也加速了AI在两个赛道Discriminative model和Generative model的发展。2012年的AlexNet,2014年的VGGNet,2015年的ResNet,2016年的DenseNet都是前者的经典模型。
而对于Generative model,2014年大神Ian Goodfellow提出了GAN,两个神经网络互相学习和训练,被认为是CV领域的重大突破,通过两个神经网络的相互博弈,使得生成的数据分布更接近真实数据分布。从此2014年的GAN、VAE以及2016年的PixelRNN/CNN成为了三类主流的Generative models。2017-2018年深度学习框架也建设成熟,PyTorch和Tensorflow成为首选框架,提供了很多图像处理的大量预训练模型,大大降低了技术门槛。2018年,Nvidia发布了Video-to-Video synthesis,它可以通过发生器、鉴别器网络等模块,合成高分辨率照片一样真实的视频,实现了把AI推向新的创造场景。GAN的大规模使用,也出现了很多基于GAN的模型迭代和优化,2019年BigGAN的出现让GAN的世界更强大,由它训练生成的图像已经无法分辨真假了,被认为是当时最强的图像生成器。
但是GAN依然存在一些缺陷,比如一些研究中都有提到模型的稳定性和收敛较差,尤其是面对更加复杂和多样的数据。更为重要的是,让生成的数据分布接近真实数据分布,也就是接近现有的内容的样子同样会形成一个问题,就是生成的内容是非常接近现有内容,接近也就是没法突破带来艺术上的“创新”。
而2020年开始在图片生成领域研究更多的Diffusion model克服了这些问题。Diffusion model的核心原理就是给图片去噪的过程中理解有意义的图像是如何生成的,同时又大大简化了模型训练过程数据处理的难度和稳定性问题。所以Diffusion模型生成的图片相比GAN模型京都更高,且随着样本数量和训练时长的累积,Diffusion model展现了对艺术表达风格更好的模拟能力。2021年的对比研究表明,在同样的ImageNet的数据库训练后的图片生成质量,使用Diffusion model得到的FID评估结果要优于当时最好的Generative models BigGAN-deep等等。
正如开头提到,今年的AI热点属于文本创作内容,而其实一直到2021年初,OpenAI发布的DALL-E其AI绘画水平也就一般,但这里开始拥有的一个重要能力就可以按照文本描述进行创作。然后今年2022年,在三座大山Stable Diffusion、DALL-E 2、MidJourney生成的各种画作中,已经引起了各种人群包括开发者、艺术家、美术工作者等等的兴趣尝试和争论。Stable Diffusion的开源和简单的过滤器功能无疑将Text-to-Imagede的热点和争议推向了高潮。
而很快大厂们不再只局限于图片,同时又推出了Text-to-Video的产品。Meta在刚过去的九月底宣布了新的AI产品Make-A-Video,使用者可以同样使用文本的方式生产简洁和高质量的短视频,他们的说明是系统模型可以从文本-图片配对数据中学习这个世界的样子并从视频片段中推理没有文本情况下的世界变化。从实现场景来看也有多种使用方式,比如文本描述不同类型的场景动作、使用单张或一对图片生成变化视频、在原始视频中加入额外的元素和变化,Meta也表明了他们之后会发布demo工具。很快在十月初,Google也发布了他们新的AI产品Imagen Video,同样是使用文本生产视频的工具。Imagen Video还在研发阶段,但Google的学术论文表明了这个工具可以通过文本描述生产24 fps的分辨率在1280x768的视频,同时可以有风格化能力和物体3D旋转能力。文章还表明Imagen Video在文本内容的视频呈现上也会相对于优于DALL-E和Stable Diffusion。又没过几天,Google和Phenaki宣布了另一个文本生产视频工具Phenaki,甚至可以生产2分钟以上较长的视频。Google同时也说明了“问题数据”对于AI模型的影响和潜在的风险,公司一直致力于严谨过滤暴力和色情内容以及文化偏差等问题,因此短期内并不会开源Imagen Video模型,但我们相信不久的将来,不管通过工具或者源代码的方式,这些cutting-edge的视频生产模型也会和图片生产模型一样很快和AI创作者们相见。
既然有了Text-to-Image和Text-to-Video,那Text-to-Speech肯定也要蹭一下热度。10月中旬postcast.ai发布了一段音频是跟用AI生成的跟Steve Jobs的对话火了(新闻),从语音语调上听起来真的和Steve本人没有差别,完全不像是机器人的声音。而技术提供方play.ht在他们的网站上也上线了新的这个非常有吸引力的功能Voice Cloning,上面提供各种名人的AI合成声音。他们并没有提供更多的技术信息,但看起来他们使用了2020年上线并在2021年底开放的GPT3模型,同时从效果上看起来已经非常接近复制真人的声音了。


技术解读
看到历史和一些生动的例子,是不是觉得AI生成各种内容已经就在眼前了?我们可以随便写几句话就能生成精美的图片、视频、声音满足各种需求了?但是实际操作上依然会有很多的限制。下面我们就来适当剖析一下最近较热的文本生成图片和视频技术原理,到底实现了什么功能以及相关的局限性在哪里,后面我们再针对实际游戏内容做一些demo,更贴合应用场景的了解这些局限性。
(一)Text-to-Image技术
不同的AI图片生成器技术结构上会有差别,本文在最后也附上了一些重要模型的参考文献。我们在这里主要针对最近热门的Stable Diffusion和DALL-E 2做一些解读和讨论。这类的AI生成模型的核心技术能力就是,把人类创作的内容,用某一个高维的数学向量进行表示。如果这种内容到向量的“翻译”足够合理且能代表内容的特征,那么人类所有的创作内容都可以转化为这个空间里的向量。当把这个世界上所有的内容都转化为向量,而在这个空间中还无法表示出来的向量就是还没有创造出来的内容。而我们已经知道了这些已知内容的向量,那我们就可以通过反向转化,用AI“创造”出还没有被创造的内容。
Stable Diffusion的整体上来说主要是三个部分,language model、diffusion model和decoder。

Language model主要将输入的文本提示转化为可以输入到diffusion model使用的表示形式,通常使用embedding加上一些random noise输入到下一层。
diffusion model主要是一个时间条件U-Net,它将一些高斯噪声和文本表示作为模型输入,将对应的图像添加一点高斯噪声,从而得到一个稍微有噪点的图像,然后在时间线上重复这个过程,对于稍微有噪点的图像,继续添加高斯噪声,以获得更有噪点的图像,重复多次到几百次后就可以获得完全嘈杂的图像。这么做的过程中,知道每个步骤的图像版本。然后训练的NN就可以将噪声较大的示例作为输入,具有预测图像去噪版本的能力。
在训练过程中,还有一个encoder,是decoder的对应部分,encoder的目标是将输入图像转化为具有高语义意义的缩减采样表示,但消除与手头图像不太相关的高频视觉噪声。这里的做法是将encoder与diffusion的训练分开。这样,可以训练encoder获得最佳图像表示,然后在下游训练几个扩散模型,这样就可以在像素空间的训练上比原始图像计算少64倍,因为训练模型的训练和推理是计算最贵的部分。
decoder的主要作用就是对应encoder的部分,获得扩散模型的输出并将其放大到完整图像。比如扩散模型在64x64 px上训练,解码器将其提高到512x512 px。
DALL-E 2其实是三个子模块拼接而成的,具体来说:
-
一个基于CLIP模型的编码模块,目标是训练好的文本和图像encoder,从而可以把文本和图像都被编码为相应的特征空间。
-
一个先验(prior)模块,目标是实现文本编码到图像编码的转换。
-
一个decoder模块,该模块通过解码图像编码生成目标图像。
在本篇文章开始前,希望你可以了解go的一些基本的内存知识,不需要太深入,简单总结了如下几点:
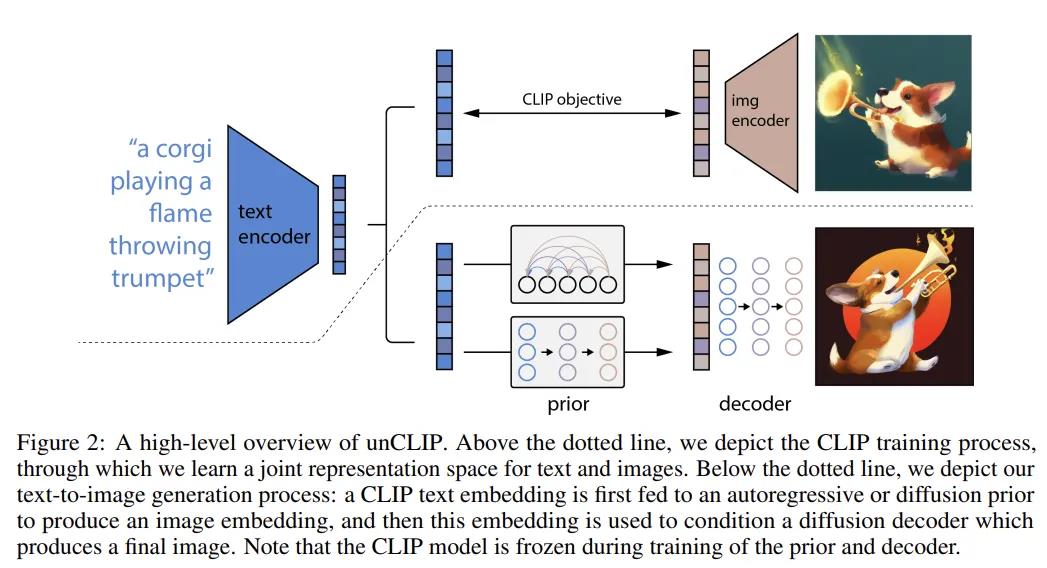
从上面的模型拆解中可以看出,DALL-E 2和Stable Diffusion的text encoder都是基于openAI提出的CLIP,图像的生成都是基于diffusion model。其中,CLIP是学习任意给定的图像和标题(caption)之间的相关程度。其原理是计算图像和标题各自embedding之后的高维数学向量的余弦相似度(cosine similarity)。

(二)Text-to-Video技术
文本生成视频大概从2017年就开始有一些研究了,但一直都有很多限制。而从今年10月初Meta宣布了他们的产品Make-A-Video以及Google宣布了Imagen Video。这两款都是创新了Text-to-Video的技术场景。而这两款最新产品都是从他们的Text-to-Image产品衍生而言的,所以技术实现方式也是基于Text-to-Image的技术演变而成。
本质上来说我们可以认为静态图片就是只有一帧的视频。生成视频需要考虑图片中的元素在时间线上的变化,所以比生成照片会难很多,除了根据文本信息生成合理和正确的图片像素外,还必须推理图片像素对应的信息如何随时间变化。这里我们主要根据Make-A-Video的研究论文做一下拆解。
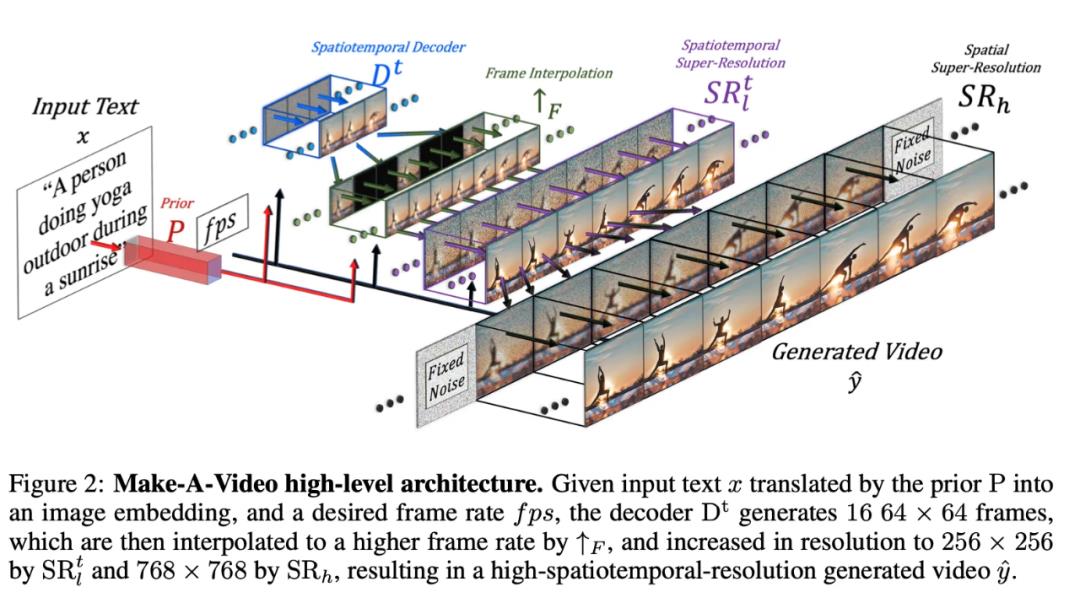
Make-A-Video正是建立在text-to-Image技术最新进展的基础上,使用的是一种通过时空分解的diffusion model将基于Text-to-Image的模型扩展到Text-to-Video的方法。原理很直接:
-
从文本-图像数据里学习描述的世界长什么样(文本生成图像)
-
从无文本的视频数据中学习世界的变化(图像在时间轴上的变化)
训练数据是23亿文本-图像数据(Schuhmann et al),以及千万级别的视频数据(WebVid-10M and HD-VILA-100M)。
整体上来说Make-A-Video也是有三个重要组成部分,所有的组成部分都是分开训练:
-
基于文本图像pair训练的基本的Text-to-Image的模型,总共会用到三个网络:
-
Prior网络:从文本信息生成Image特征向量,也是唯一接收文本信息的网络。
-
Decoder网络:从图像特征网络生成低分辨率64x64的图片。
-
两个空间的高分辨率网络:生成256x256和768x768的图片。
-
时空卷积层和注意层,将基于第一部分的网络扩展到时间维度
-
在模型初始化阶段扩展包含了时间维度,而扩展后包括了新的注意层,可以从视频数据中学习信息的时间变化
-
temporal layer是通过未标注的视频数据进行fine-tune,一般从视频中抽取16帧。所以加上时间维度的decoder可以生成16帧的图片
-
以及用于高帧速率生成的插帧网络
空间的超分辨率模型以及插帧模型,提高的高帧速率和分辨率,让视觉质量看起来更好。
整体评估上都要优于今年早些时期的研究:
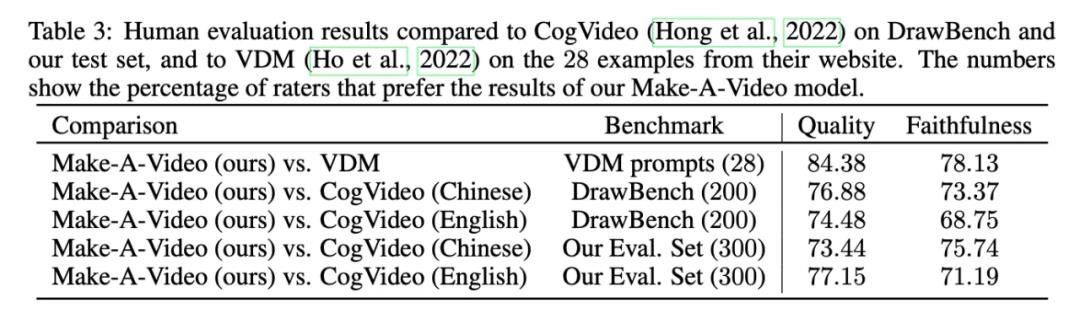
优势:
-
这里的好处很明显就是不再需要使用大量的文本视频pair数据来训练模型。
-
因此也大大加速了模型训练时间。
-
继承了现在最好的文本生成图像模型的优质结果。
*前两点都是之前text-to-video生成模型发展的瓶颈。
限制:
-
这个方法无法学习只能从视频中得到的关系文本和现象的关系,比如一个人是从左往右挥手还是从右往左挥手的的视频细节。
-
目前限于简单的动作和变化,包括多个场景和事件的较长视频,或者更多的视频中展现的故事细节很难实现。
-
一样是使用大量公开数据的大规模模型,一样有用于生产有害内容的风险。
-
Google’s Imagen Video
是由7个串联的子模型构成,模型包含多达116亿个参数,其中T5是一个language model用来理解文本语义,Base是负责生产视频中的关键帧,SSR模型提升视频的像素,TSR负责填充关键帧之间辅助帧。
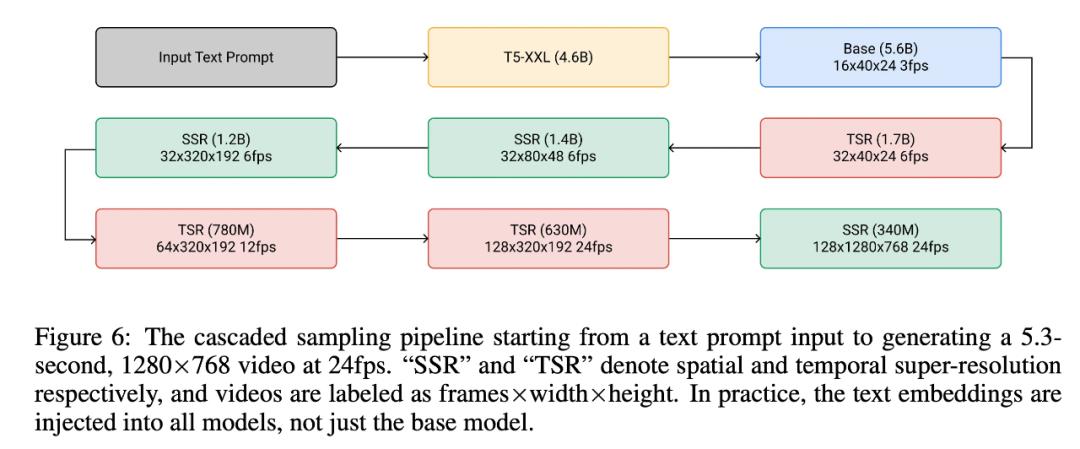

能够实现的技术应用场景
通过底层技术尤其在CV、NLP相关的各类模型在不同内容和多模态场景中的尝试和迭代,对于AI创作和内容生产同样无外乎在不同类型内容(文本、音频、图像、视频)生产和内容跨类型的生产场景。下图很好地总结了这些实际中可以使用的技术场景。
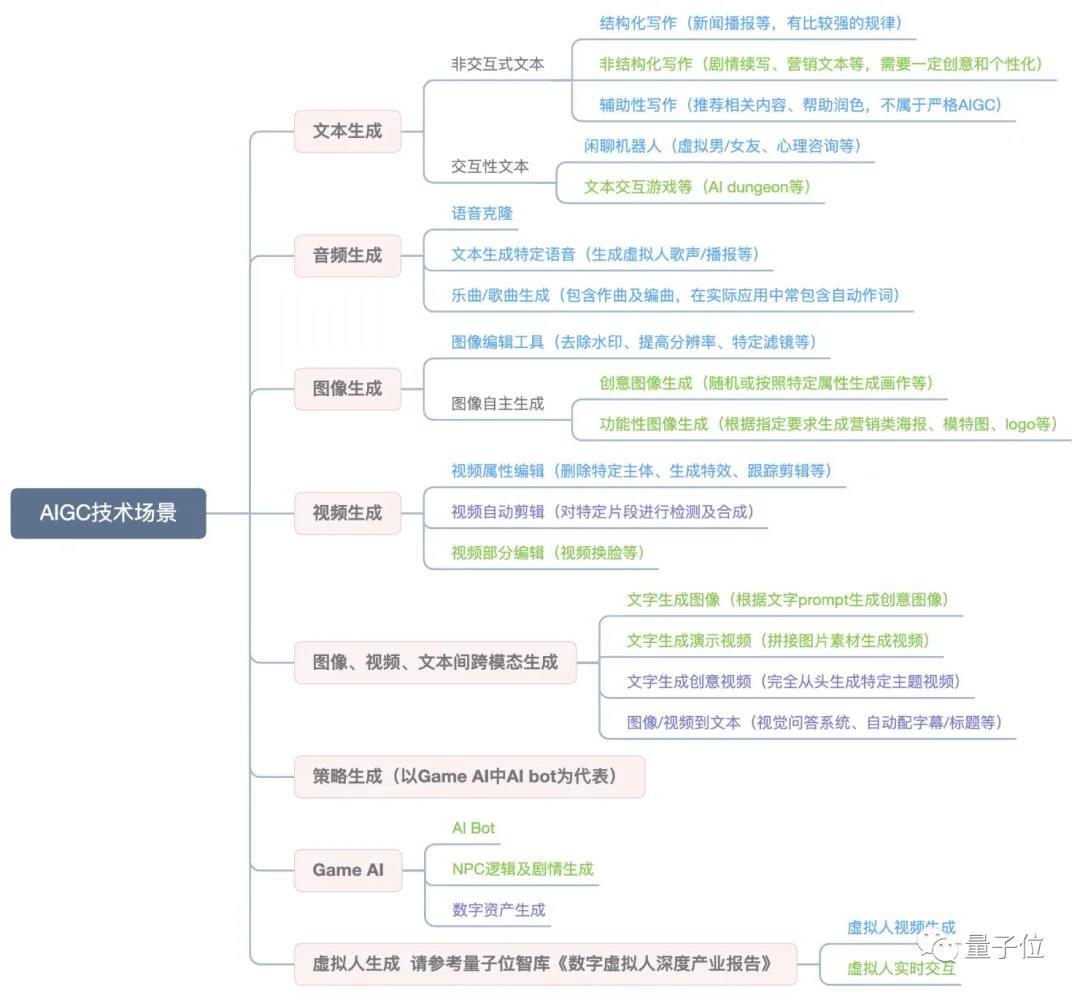

针对游戏内容的Demo
这些技术实现是否同样能给我们提供游戏相关的应用场景呢?我们在这里针对相对较为成熟的图像相关的生成场景做了几个demo尝试。整体上来说在我们游戏中台相关的业务场景中是有一些应用点的。下面看一下这几个demo的样子。
(一)文本生成图像
针对庄周这个英雄的样子我们使用工具和代码都尝试了一下如何能够生产不同风格的庄周
游戏中的样子:

经过我们以下描述后的样子,同时也可以加上卡通、二次元、素描等等风格的描述,我们得到各种不同风格类型的样子:
Ultra detailed illustration of a butterfly anime boy covered in liquid chrome, with green short hair, beautiful and clear facial features, lost in a dreamy fairy landscape, crystal butterflies around, vivid colors, 8k, anime vibes, octane render, uplifting, magical composition, trending on artstation

我们在各种尝试的过程中很明显的感知和发现一些限制:
-
文本描述生成的结果会有一些随机性,生成的图片大概率是很难完全按照“需求”生成,更多带来的是“惊喜”,这种惊喜在一定的层面上代表的也是一种艺术风格。所以在实际的使用中并不是很适用于按照严格要求生产图片的任务,而更多的适用于有一定的描述,能够给艺术创意带来一些灵感的迸发和参考。
-
文本的准确描述对于生成的图片样子是极其重要的,技术本身对文本描述和措辞有较高要求,需对脑海中的核心创意细节有较为准确的描述。
-
生产Domain-specific例如腾讯游戏高度一致的内容元素需对预训练大模型进行再训练。
而文本生成视频的场景相对很新,Google/Meta也是这两三周才官宣对应的视频生成器,且还没有开放使用和开源,但我们预估以目前的热度和迭代速度,在未来的3-6个月内我们可以对相关能力有更清晰的探索和尝试。
(二)图像融合和变换
图像本身的融合变换在早几年的时候就已经有了一些研究和探索,且有了相对较为成熟的生成的样子,这里我们使用和平精英的素材尝试做一种变换风格的样子。
和平精英素材原图和星空:

更加深度的将星空的颜色和变化融合到原始图片中:

相对较浅度的将星空的颜色像素融合到原始图片中:

另外一种很有意思的方式是,我们可以变换人物风格,比如王者英雄不知火舞和亚瑟在我们印象的样子,我们可以把他们Q化成数码宝贝的样子:
不知火舞



亚瑟



试想一下,这些不同的技术实现甚至都可以串联在一起,比如我们可以先用文本描述生成图片,再对图片进行风格变换等等,那这里可以操作的事情就越来越多了,这里就不一一展开了。
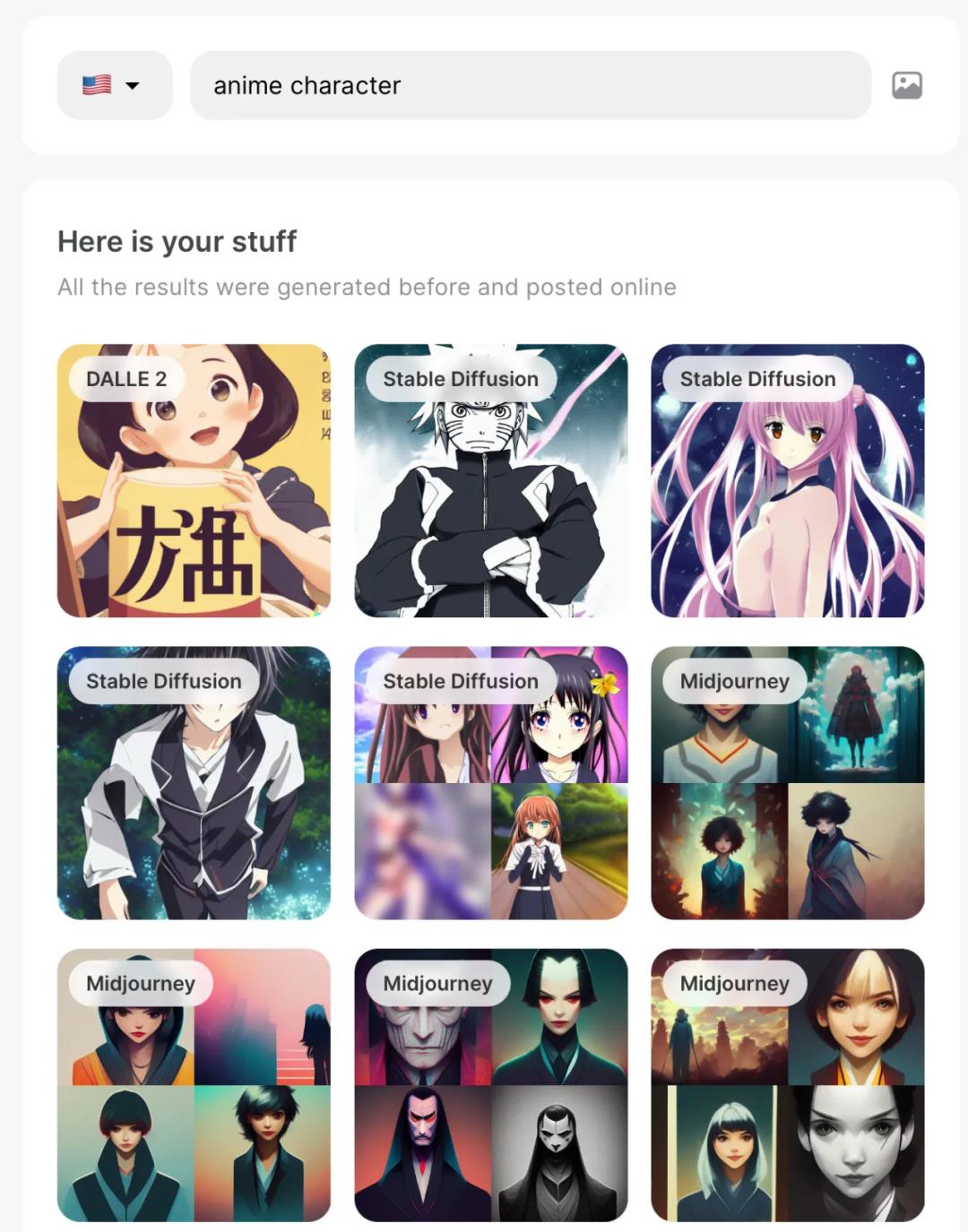
而再进一步思考(发自懒人的思考),我们是不是都不用去思考文本怎么写?有没有帮忙生成文本或者我们可以搜索之前生成过的文本?答案是有,比如Phraser就提供了这样的方式,甚至可以通过图片搜索相关的文本:

AI创作的意义及风险
(一)意义
正如开头提到,今年的AI热点属于AI创作,从2月的Disco Diffusion,到4月的DALL-E 2和MidJourney内测,到5/6月的Google模型Imagen和Parti,再到7月底的Stable Diffusion。越来越多的人开始尝试AI创作图像、声音、视频、3D内容等等,这让我们看到了AI在艺术领域越来越多的可能性。
十多年前当世界都开始为AI和机器学习欢呼的时候,我们看到了很多AI可以做的事情,而“创作力”和“想象力”也是一直以来AI最无法啃动的硬骨头,也是人类世界在AI和机器取代面前最后的倔强,然而现在看起来也是可以被技术拆解的。
从Alpha GO身上,我们就看到了AI在智慧和谋略上就已经突破了人类极限,而AI创作又进一步在创造力和想象力逐渐取代人类。在未来,一个各方面成熟的AI完全取代人类看起来已经是越来越现实的问题。如果AI未来可以完成计算机领域上下游所有的事情包括自己写代码,那么人类需要思考的问题就是如何和一个超越自己所有方面的人共存于世了。
(二)风险
AI创作的大火在很长时间以后回头看一定有Stable Diffusion的开源的一席之地,同样这也会带来一些争议和风险。Stability AI的开源是简单粗暴的,他们几乎不对生成内容做任何审核或者过滤,他们只包含了一些关键词过滤,但技术上可以轻松绕过,Reddit上就有教程如何5秒内移除Stable Diffusion的安全过滤。因此用户可以轻松指控Stable Diffusion生成暴力或不良图片,描绘公众人物和名人,也可以高度仿制艺术品或者有版权保护的图像,aka deepfakes。
由此我们也可以设想这项技术可能被用于各类恶意和影响巨大的用途,我们还很难判断在更久的未来,这项技术的开源是会给我们更大的技术革新还是各种问题。目前最大的乱子可能就是Stable Diffusion让生成暴力和色情图像变得更容易,且内容中往往包含真人特征。虽然开源说明禁止人们使用该模型实施各类犯罪行为,但只要把Stable Diffusion下载到自己的电脑上,使用者可以完全不守约束。虽然很多论坛例如Reddit有不少约束政策且会封禁相关内容,但仍有用户不断生成各种名人明星的荒诞图像,AI生成内容的伦理问题再次会出现在风口浪尖。
在AI创作内容的这些模型中,训练数据中一类很明显的视觉素材就是受版权保护的作品。这在艺术家眼里,模仿艺术风格和美学的行为是不道德行为,且可能违反版权。Stable Diffusion也是其中重要一员,它的训练集LAION-5B包含50多亿张图像与匹配的文本标注,其中就包含了大量受版权保护的内容,这些内容其实归众多独立艺术家和专业摄影师所有。这些版权争议,也给这些AI创作工具带来了盗窃艺术家创作成果的骂名,也让很多有抱负有想法的艺术家越来越难以生存。
参考资料:
1.https://arxiv.org/pdf/2209.14697.pdf
2.https://arxiv.org/pdf/2112.10752.pdf
3.[1907.05600] Generative Modeling by Estimating Gradients of the Data Distribution
4.https://arxiv.org/pdf/2204.06125.pdf
5.https://imagen.research.google
6.[2105.05233] Diffusion Models Beat GANs on Image Synthesis
7.https://ommer-lab.com/research/latent-diffusion-models/
(注意:后台回复关键词“AI”,即可获取demo生产工具)
以上是关于AI绘画火了!一文看懂背后技术原理的主要内容,如果未能解决你的问题,请参考以下文章
AI绘画火爆,以昆仑万维AIGC为例,揭秘AI绘画背后的模型算法
AI绘画火爆,以昆仑万维AIGC为例,揭秘AI绘画背后的模型算法