AI绘画火爆,以昆仑万维AIGC为例,揭秘AI绘画背后的模型算法
Posted ZackSock
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AI绘画火爆,以昆仑万维AIGC为例,揭秘AI绘画背后的模型算法相关的知识,希望对你有一定的参考价值。
AI绘画火爆,以昆仑万维AIGC为例,揭秘AI绘画背后的模型算法
一、前言
最近AI绘画让人工智能再次走进大众视野。在人工智能发展早起,一直认为人工智能能实现的功能非常有限。通常都是些死板的东西,像是下棋、问答之类的,不具有创造性。那时的人们应该想不到现在的AI已经能够绘画、谱曲、作诗了。这些曾被认为是人类独有的东西,如今也被AI涉猎了。
今天我们要讨论的就是现今大火的AI绘画,我们来看看AI是不是真的有了创造力,还是只是不停的搬运。
可以实现AI绘画的模型有很多种,今天我们主要讨论Conditional GAN和Stable Diffusion两种模型。现在已经有了对应的商业版本,比如昆仑万维的AI绘图就是采用了Stable Diffusion分支模型,并取得了不菲的成绩。
二、GAN
这里我们讨论Conditional GAN(Generative Adversarial Network)实现AI的原理。在讲Conditional GAN之前,我们来看看GAN是怎么回事。
2.1 生成
生成网络一直被认为是赋予AI创造力的突破口,生成包括文本生成、图像生成、音频生成等。
GAN是一种比较成熟的生成网络,通常用来生成图像。GAN有许多变种,包括DCGAN、CycleGAN等。
2.2 专家与赝品
GAN的中文名叫生成对抗网络,在提到GAN时经常会用两个对立的角色来举例。一个是造假专家,专门负责制作赝品;另一个是鉴别专家,专门负责鉴定赝品。他们最开始都不是专家,而是在对抗中学习,最终造假专家能够制造出人都难以识别出来的赝品。最终我们会抛弃鉴别专家,让造假专家为我们服务。
上面提到的造假专家就是G网络,也就是Generator;而鉴别专家就是D网络,也就是Discriminator。它们在互相对抗中学习,最终成为各自领域的专家,这就是GAN的思想。
2.3 Generator
下面我们以生成动漫头像的例子来讨论GAN网络的Generator和Discriminator。
首先讨论Generator,它在GAN中充当造假的作用,也是用它来生成图像。Generator接收一个随机变量,这个随机变量满足一种特定的简单分布,比如高斯分布。接收输入的随机变量后,网络经过运算生成一个非常长的向量,我们可以把这个向量reshape成w×h×3,也就是彩色图像。
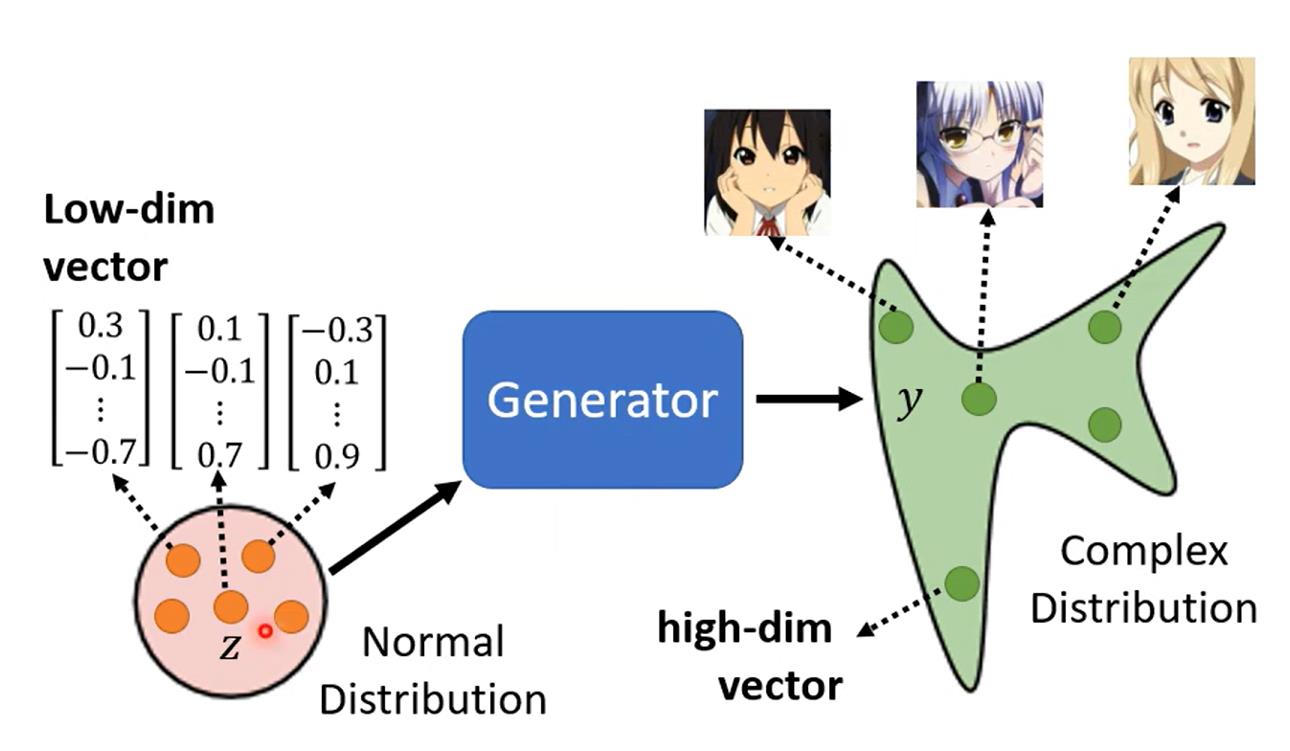
Generator的具体结构可以是多种多样的,通常是以卷积为基础的网络。比如在DCGAN中,Generator由5层反卷积组成,其网络结构如下图:
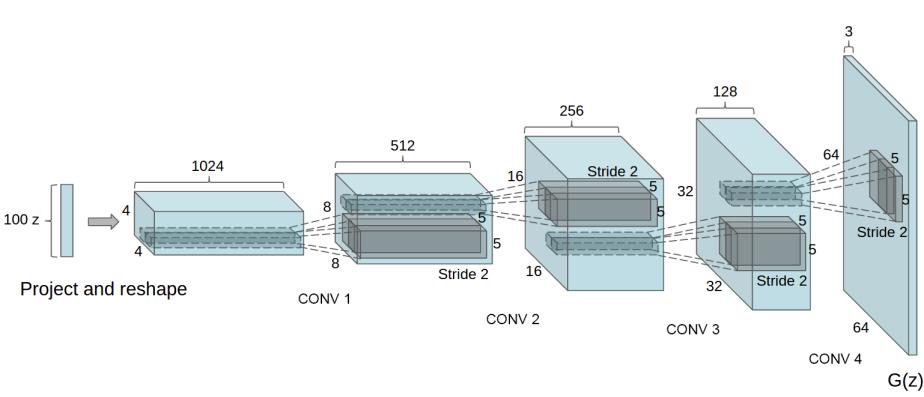
输入一个维度为100的向量,输出一张64×64×3的图像,其PyTorch实现如下:
class Generator(nn.Module):
def __init__(self, ngpu):
super(Generator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# input is Z, going into a convolution
nn.ConvTranspose2d( nz, ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# state size. (ngf*8) x 4 x 4
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# state size. (ngf*4) x 8 x 8
nn.ConvTranspose2d( ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# state size. (ngf*2) x 16 x 16
nn.ConvTranspose2d( ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# state size. (ngf) x 32 x 32
nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False),
nn.Tanh()
# state size. (nc) x 64 x 64
)
def forward(self, input):
return self.main(input)
2.4 Discriminator
Discriminator是GAN中非常重要的一个角色,它是一个接受一个图片输入的网络,输入的图像会包含一部分真实图像real(我们收集的动漫图像),还会包含一部分虚假图像fake(Generator生成的图像),然后输出一个结果。这个结果可以是fake是真实图像的概率,也可以是fake的类别(0表示假,1表示真)。对于Discriminator而言,它的目的就是调整网络参数,让网络知道fake图像是假的。
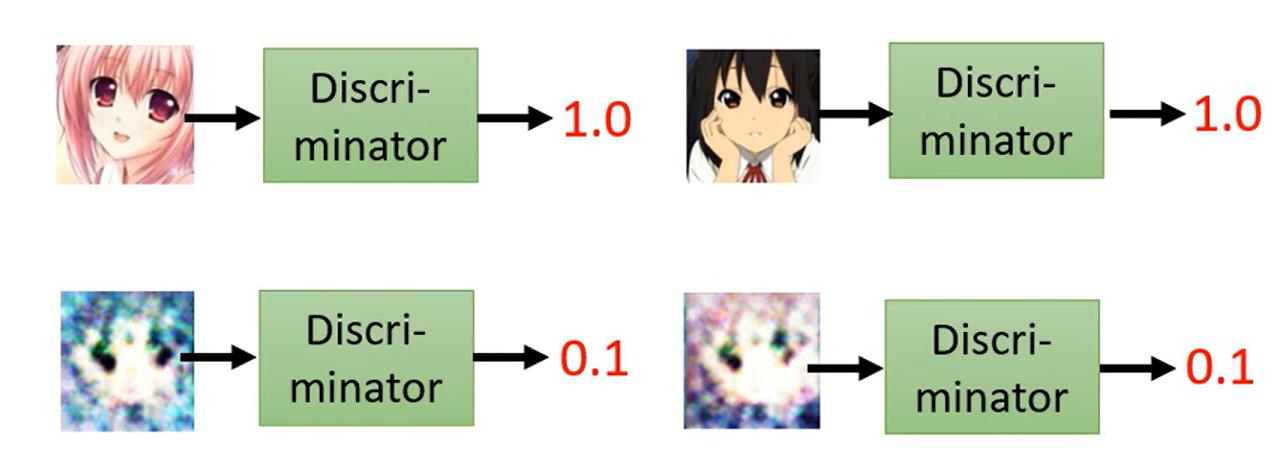
关于Discriminator的结构,并没有非常固定的约束,通常是一个卷积网络。这里同样参考DCGAN,这里实现PyTorch的一个实现:
class Discriminator(nn.Module):
def __init__(self, ngpu):
super(Discriminator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# input is (nc) x 64 x 64
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf) x 32 x 32
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*2) x 16 x 16
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*4) x 8 x 8
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*8) x 4 x 4
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)
这里比较特别的就是LeakyReLU的使用。
2.5 GAN
有了Generator和Discriminator就可以组成GAN网络了。
最开始Generator和Discriminator是两个懵懂小孩,Generator不知道如何生成,Discriminator也不知道如何辨别。GAN网络的训练分为下面几个步骤。
- 第一步:训练Discriminator网络,此时Generator提供的照片都是噪声,先训练Discriminator可以让 Discriminator知道如何区分真实图像和噪声
- 第二步:固定Discriminator,训练Generator,让Generator生成的图像能够瞒过Discriminator
- 第三步:再循环训练Discriminator-Generator,直到Generator生成的图像能够满足我们的需求
- 第四步:用Generator生成图像
上述步骤可以看作下图:

以上就是GAN网络的训练过程。其实就是Generator和Discriminator交替训练的过程,其PyTorch实现如下:
# Create the generator
netG = Generator(ngpu).to(device)
if (device.type == 'cuda') and (ngpu > 1):
netG = nn.DataParallel(netG, list(range(ngpu)))
netG.apply(weights_init)
# Create the Discriminator
netD = Discriminator(ngpu).to(device)
if (device.type == 'cuda') and (ngpu > 1):
netD = nn.DataParallel(netD, list(range(ngpu)))
netD.apply(weights_init)
criterion = nn.BCELoss()
fixed_noise = torch.randn(64, nz, 1, 1, device=device)
real_label = 1.
fake_label = 0.
optimizerD = optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999))
# Training Loop
# Lists to keep track of progress
img_list = []
G_losses = []
D_losses = []
iters = 0
print("Starting Training Loop...")
# For each epoch
for epoch in range(num_epochs):
# For each batch in the dataloader
for i, data in enumerate(dataloader, 0):
############################
# (1) Update D network: maximize log(D(x)) + log(1 - D(G(z)))
###########################
## Train with all-real batch
netD.zero_grad()
# Format batch
real_cpu = data[0].to(device)
b_size = real_cpu.size(0)
label = torch.full((b_size,), real_label, dtype=torch.float, device=device)
# Forward pass real batch through D
output = netD(real_cpu).view(-1)
# Calculate loss on all-real batch
errD_real = criterion(output, label)
# Calculate gradients for D in backward pass
errD_real.backward()
D_x = output.mean().item()
## Train with all-fake batch
# Generate batch of latent vectors
noise = torch.randn(b_size, nz, 1, 1, device=device)
# Generate fake image batch with G
fake = netG(noise)
label.fill_(fake_label)
# Classify all fake batch with D
output = netD(fake.detach()).view(-1)
# Calculate D's loss on the all-fake batch
errD_fake = criterion(output, label)
# Calculate the gradients for this batch, accumulated (summed) with previous gradients
errD_fake.backward()
D_G_z1 = output.mean().item()
# Compute error of D as sum over the fake and the real batches
errD = errD_real + errD_fake
# Update D
optimizerD.step()
############################
# (2) Update G network: maximize log(D(G(z)))
###########################
netG.zero_grad()
label.fill_(real_label) # fake labels are real for generator cost
# Since we just updated D, perform another forward pass of all-fake batch through D
output = netD(fake).view(-1)
# Calculate G's loss based on this output
errG = criterion(output, label)
# Calculate gradients for G
errG.backward()
D_G_z2 = output.mean().item()
# Update G
optimizerG.step()
# Output training stats
if i % 50 == 0:
print('[%d/%d][%d/%d]\\tLoss_D: %.4f\\tLoss_G: %.4f\\tD(x): %.4f\\tD(G(z)): %.4f / %.4f'
% (epoch, num_epochs, i, len(dataloader),
errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))
# Save Losses for plotting later
G_losses.append(errG.item())
D_losses.append(errD.item())
# Check how the generator is doing by saving G's output on fixed_noise
if (iters % 500 == 0) or ((epoch == num_epochs-1) and (i == len(dataloader)-1)):
with torch.no_grad():
fake = netG(fixed_noise).detach().cpu()
img_list.append(vutils.make_grid(fake, padding=2, normalize=True))
iters += 1
经过一段时间的训练后,我们就可以生成一些动漫图像了。关于DCGAN的代码实现可以参考https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.html#sphx-glr-beginner-dcgan-faces-tutorial-py。
三、Conditional GAN
通过上面的GAN网络,我们可以生成动漫图像。但是这个生成是不可控的,我们只知道它生成的是动漫图像,至于图像内容我们无法得知。我们无法根据描述来生成图像,这个是GAN网络的局限,因此提出一种变形叫Conditional GAN,这种GAN网络可以解决上面的问题。
3.1 Generator
Conditional GAN不同于GAN的地方在于其Generator和Discriminator接收参数的数量不同。Generator在接收随机变量的同时还接收一个“思想向量”,这个思想向量可以是对句子的一个编码。此时我们的Generator的结构变成了输入两个向量,输出一个图像的网络。
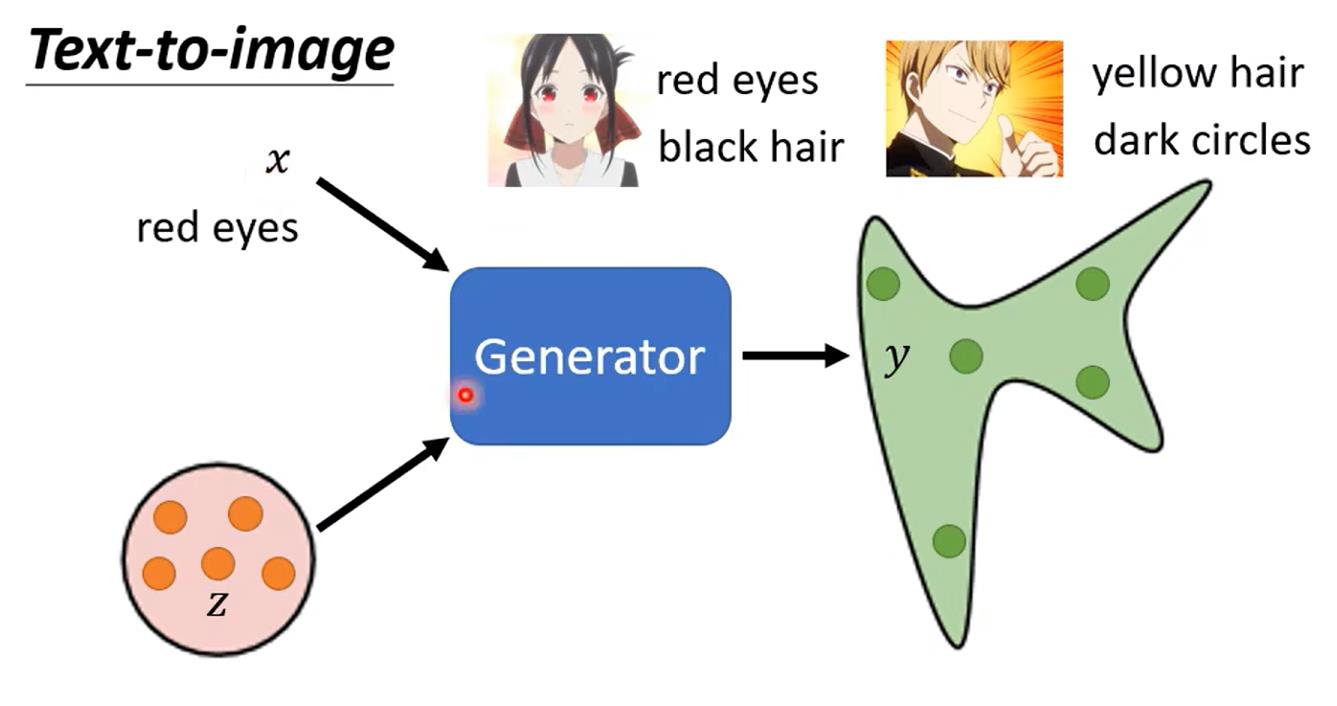
比如上图,我们将red eyes这个句子转化成向量交给Generator,然后让它生成红眼的动漫图像。通过修改x我们可以得到不同的图像,又因为z这个随机变量的存在,我们即使给同样的x也可以得到不同的图像。
为了能让网络学习到文字和描述之间的关系,我们需要准备好(文字描述-图像)这种组合的数据集。
3.2 Discriminator
Discriminator同样需要输入两个向量,分别是Generator生成的图像和输入到Generator的x,然后输出是否正确。

交给Generator的训练数据需要把(正确描述-正确图像)作为类别1,把(正确描述,不正确图像)、(正确描述,正确图像,但图像和描述不匹配)作为类别0。
如果不包含(正确描述,正确图像,但图像和描述不匹配)作为训练数据,我们的网络得不到很好的结果。
知道了Generator和Discriminator网络后,我们可以使用和GAN类似的方式进行训练,最后的Generator就是我们的AI画师了。我们给它文字描述,它给我们返回一张对应的图。
四、Stable Diffusion
Stable Diffusion和Conditional GAN有很多相似的地方,因为都可以用来解决Text-to-image的问题,因此模型都是接收一个文本以及影响图像的高斯噪声。只不过使用的网络结构有所区别,而且Stable Diffusion引入了Latent Diffusion,让训练更加顺利。
Latent Diffusion包括了三个部分,分别是自编码器、U-Net、Text-Encoder。
其中自编码器包括编码器和解码器两部分。编码器的输出会交给U-Net进行处理。而U-Net得输出则会交给解码器。
U-Net在接收编码器输入的同时,还接收一个句子的向量。这个句向量由Text-Encoder给出。下图是U-Net的结构。

因为U-Net是在低维空间上工作的,因此Latent Diffusion快速有效。Stable Diffusion的整体流程如下图:

五、昆仑万维-天工巧绘体验
现在有许多现成的平台可以AI绘画,相比GAN,Stable Diffusion要更擅长绘画,这里可以用昆仑天宫的天工巧绘(SkyPaint)来进行一个简单的体验,天工巧绘SkyPaint就是采用全球第一款多语言Stable Diffusion分支模型,是国内为数不多的支持中英双语的文图生成模型。
昆仑万维AI绘画模型在模型训练过程中主要采取了如下策略:
- 在增加中文提示词输入能力的同时兼容原版stable_diffusion的英文提示词模型,之前用户积累的英文提示词手册依然可以在模型上使用;
- 使用1.5亿级别的平行语料优化提示词模型实现中英文对照,不仅涉及翻译任务语料,还包括了用户使用频率高的提示词中英语料,古诗词中英语料,字幕语料,百科语料,图片文字描述语料等多场景多任务的海量语料集合;
- 训练时采用模型蒸馏方案和双语对齐方案,使用教师模型对学生模型蒸馏的同时辅以解码器语言对齐任务辅助模型训练。
在文本生成图像以及图片生成文本两种应用中,昆仑天工的天工巧绘 SkyPaint 模型均与 AI 作画领域最先进模型相当,下表对比了不同模型在 Flickr30K-CN 数据集上的性能表现。

下面是几个测试的例子。
- 戴帽子拿剑的猫
我原本的设想是得到近似穿长靴的猫一样的图像,下面几个结果有一些穿长靴的猫的韵味

2. 梵高星空
其中第一个效果图和原作场景有几分相似的地方,而其余几幅画则不太一样

3. 阿拉斯加千年不化的雪山 一架红色直升机正在起飞
这次的描述包含很多细节,红色直升机,起飞等。从下面的结果来看AI把握了这些细节,每张图都没有太多违和感,不过细看螺旋桨还是有一些不太满意的地方。

大家可以自己去尝试一下AI绘图的效果。
六、总结与展望
从Conditional GAN的实现来AI绘画并不是简单的照搬,在训练Conditional GAN的时候,我们在做的时学习到图像的分布。对于一张64×64×3的8bit图,可以有12288^256种组合,而这么多组合里面只有极小一部分是我们需要的图像,而Generator网络就是把z从一个简单的分布(比如高斯分布),映射一个复杂的分布(图像的分布)。当学习到这个分布后,我们只需要从z的分布中采样一个点,就可以对应到一张图像。这就是我们Generator在做的事情。
可喜的是,基于对人工智能技术的前瞻性判断,昆仑万维从2020年开始布局AIGC领域,训练集群200张卡,投入数千万元,组建了二百余人的研发团队,2020年底至2021年4月份研发出百亿参数的中文GPT-3模型,并于2021年8月开始研发基于自有大文本模型的对话机器人,;2022年1月启动SkyMusic音乐实验室,2022年4月达到人工智能领域最优效果;2022年9月份启动编程、图像、文本方向的AIGC产品。值得一提的是,目前AI图像、AI文本、AI编程的模型已经在GitHub上开源。
官网链接,体验跳转:http://www.kunlun.com/
昆仑天工开源地址:
Github:https://github.com/SkyWorkAIGCHuggingface https://huggingface.co/SkyWork
Huggingface:https://huggingface.co/SkyWork
相关网站:
天工巧绘SkyPaint:
https://sky-paint.singularity-ai.com
天工智码SkyCode:
https://sky-code.singularity-ai.com
天工妙笔SkyText:
https://openapi.singularity-ai.com
可以相信,通过AIGC模型算法方面的技术创新和开拓,开源AIGC算法和模型社区的发展将会越来越壮大,AIGC技术在各行各业的使用和学习门槛也会逐步降低,属于AIGC的新时代将会到来。
以上是关于AI绘画火爆,以昆仑万维AIGC为例,揭秘AI绘画背后的模型算法的主要内容,如果未能解决你的问题,请参考以下文章
AI绘画火爆,以昆仑万维AIGC为例,揭秘AI绘画背后的模型算法
AI作画的业界天花板被我找到了,AIGC模型揭秘 | 昆仑万维