《作文精编大全》,Python程序员用爬虫制作的
Posted 梦想橡皮擦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《作文精编大全》,Python程序员用爬虫制作的相关的知识,希望对你有一定的参考价值。
文章目录
⛳️ 实战场景
本篇博客又是一个 Python 爬虫实战,目标站点时作文吧,一个充满作文的站点 zuowen8.com,由于其站点有那么一点点的付费需求,所以有一名爸爸级开发工程师不开心了,决定写一个小小的爬虫,他要的不多,就是一年级那一点点作文。
就是下面这个图让程序员干活的~

打开一年级作文列表页,页面如下所示,接下来要完成的第一步就是采集这个列表页的数据。
⛳️ 采集列表页
Python 在编写简易爬虫的时候,requests + lxml 是最简单的方式。
import requests
import json
headers =
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/106.0.0.0 Safari/537.36"
res = requests.get('https://www.zuowen8.com/xiaoxue/yinianjizuowen/', headers=headers)
print(res.text)
直接运行代码,会得到中文乱码界面,即下图所示内容。

对响应对象设置编码,代码如下:
res = requests.get('https://www.zuowen8.com/xiaoxue/yinianjizuowen/', headers=headers)
res.encoding = 'utf-8' # 编码错误
print(res.text)
结果设置 utf-8 之后,编码依旧错误,此时就需要查看一下网页源码中的具体编码设置了,打开开发者工具,查看源码编码,发现网站采用的是 gb2312,参考该值进行设置即可。

res = requests.get('https://www.zuowen8.com/xiaoxue/yinianjizuowen/', headers=headers)
res.encoding = 'gb2312'
print(res.text)
⛳️ 提取列表作文地址
页面源码获取到之后,就可以提取作文详情页地址了,即下图红框区域链接。
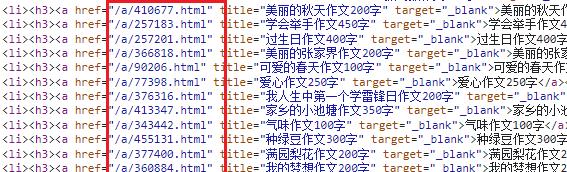
res.encoding = 'gb2312'
e = etree.HTML(res.text)
h3_list = e.xpath("//h3/a/@href")
print(h3_list)
链接获取完毕,需要将其进行拼接,得到详情页完整地址,使用 f-strings 即可。
base_domain = 'https://www.zuowen8.com'
for url in h3_list:
url = base_domain+url
print(url)
详情页地址拼接完毕,再次使用 requests 模块对详情页源码进行捕获。
for url in h3_list:
url = base_domain+url
detail = requests.get(url,headers=headers)
detail.encoding = 'gb2312'
print(detail.text)
获取到作文详情页面源码,提取作文内容,即下图红框区域展示信息。
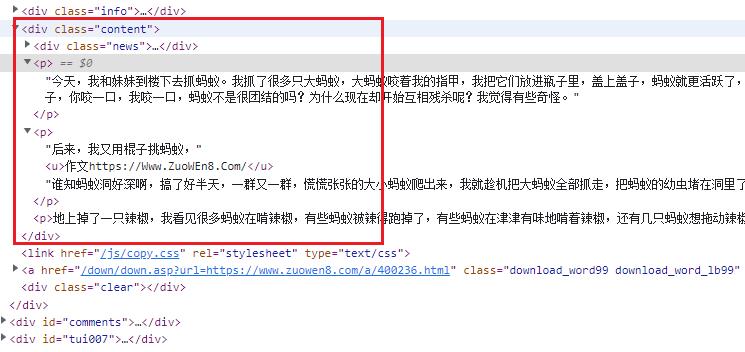
⛳️ 提取作文 8 内容
观察上图可以看到作文内容全部都在 class 等于 content 的 div 中,所以对其解析即可。
for url in h3_list:
url = base_domain+url
detail = requests.get(url,headers=headers)
detail.encoding = 'gb2312'
d = etree.HTML(detail.text)
content = d.xpath('//div[@class="content"]//p/text()')
print(content)
上述 xpath 表达式仅提取 div 元素中的子标签 p 的内部文字,恰好忽略了标签 u 中的反爬信息,即下图绿框数据需要被忽略。
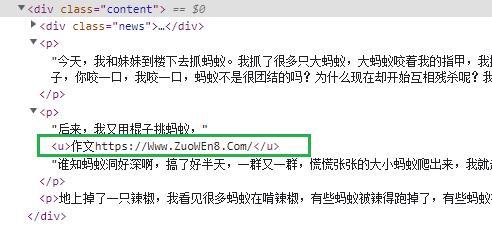
运行代码,得到的内容如下所示,每一篇作文都按照段落提取成列表。
['今天,我和妹妹到楼下去抓蚂蚁。我抓了很多只大蚂蚁,大……', '后来,我又用棍子挑蚂蚁,', '谁知蚂……来。', '地上掉了一只辣椒,我看见很多蚂蚁在啃辣椒,有些蚂蚁被辣得跑掉了,有些蚂蚁在津津有味地啃着辣椒,还有几只蚂蚁想拖动辣椒,但是拖了半天都没拖动。']
最后只需要将列表中的内容进行拼接,就可以完成属于你的《作文精编大全》。
📢📢📢📢📢📢
💗 你正在阅读 【梦想橡皮擦】 的博客
👍 阅读完毕,可以点点小手赞一下
🌻 发现错误,直接评论区中指正吧
📆 橡皮擦的第 739 篇原创博客
从订购之日起,案例 5 年内保证更新
以上是关于《作文精编大全》,Python程序员用爬虫制作的的主要内容,如果未能解决你的问题,请参考以下文章