爬虫实践-基于Jsoup爬取Facebook群组成员信息
Posted everlastxgb
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫实践-基于Jsoup爬取Facebook群组成员信息相关的知识,希望对你有一定的参考价值。
基于Jsoup爬取Facebook群组成员信息
我们知道,类似今日头条、UC头条这类的App,其内容绝大部分是来源于爬虫抓取。我们可以使用很多语言来实现爬虫,C/C++、Java、Python、php、NodeJS等,常用的框架也有很多,像Python的Scrapy、NodeJS的cheerio、Java的Jsoup等等。本文将演示如何通过Jsoup实现Facebook模拟登录,爬取特定群组的成员信息,并导出Excel。
Keywords: Netbeans, JSwing, Jsoup, Apache POI , Jackson
Source Code: FacebookGrabber
1. Facebook模拟登录
想要爬取Facebook上面的群组成员信息,第一步需要先进行登录,并将登录成功后的cookie保存,之后每次请求的headers中都要带上该cookie用于用户识别。
访问https://www.facebook.com/login 通过chrome检查html元素可以看到:
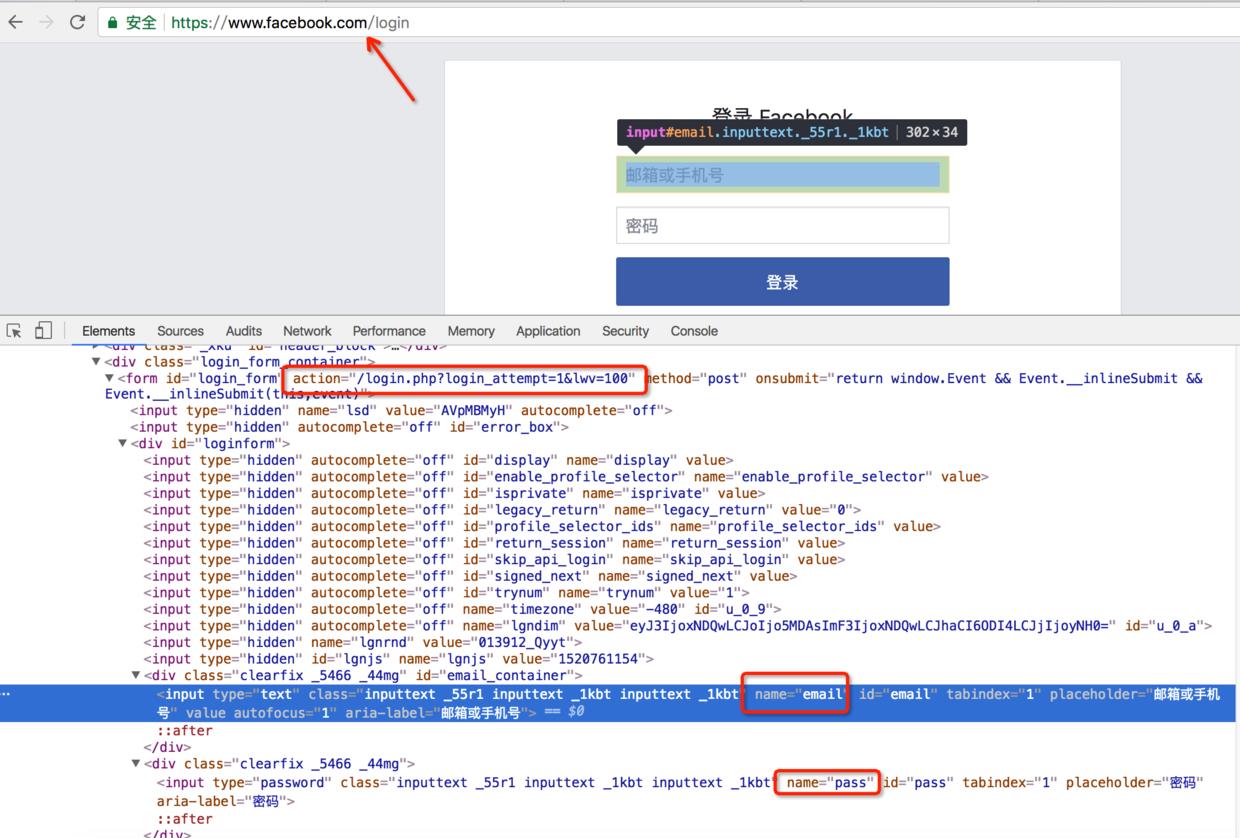
知道对应的登录url以及请求参数之后,现在我们通过Jsoup来构造登录请求以获取用户cookie信息。
这里,我写了一个基类,方便请求调用的同时,自动将每次请求获取到的cookie保存并附带到下一次的请求当中:
private Connection getConnection(String url)
return Jsoup.connect(url)
.timeout(TIMEOUT_CONNECTION)
.userAgent(userAgent)
.followRedirects(true)
.ignoreContentType(true);
protected Document requestDocument(String url, String httpMethod, Map<String, String> data) throws Exception
Connection connection = getConnection(url);
if (data != null && data.size() > 0)
connection.data(data);
if (cookies != null)
connection.cookies(cookies);
Document resultDocument = HTTP_POST.equalsIgnoreCase(httpMethod) ? connection.post() : connection.get();
return resultDocument;
protected Response requestBody(String url, String httpMethod, Map<String, String> data) throws Exception
Connection connection = getConnection(url);
if (data != null && data.size() > 0)
connection.data(data);
if (cookies != null)
connection.cookies(cookies);
connection.method(HTTP_POST.equalsIgnoreCase(httpMethod) ? Connection.Method.POST : Connection.Method.GET);
Connection.Response res = connection.execute();
if (res.cookies() != null && !res.cookies().isEmpty())
cookies = res.cookies();
return res;
基于封装好的请求基类,接下来实现 模拟登录 就变得更加简单了:
public FbUserInfo login(String email, String pass) throws Exception
// Urls.LOGIN = "https://www.facebook.com/login.php?login_attempt=1";
Response initResponse = requestBody(Urls.LOGIN, HTTP_GET, null); //fetching cookie and saving
Map<String, String> loginParams = new HashMap<>();
loginParams.put("email", email);
loginParams.put("pass", pass);
Response loginResponse = requestBody(Urls.LOGIN, HTTP_POST, loginParams);
Document loginDoc = loginResponse.parse();
FbUserInfo userInfo = null;
String userId = loginResponse.cookies().get("c_user"); // current login userId
if (userId != null && userId.length() > 0)
userInfo = new FbUserInfo();
userInfo.setId(userId);
return userInfo;
2. 获取群组中的管理员以及成员列表
下面将以 Homesteads.and.Sustainability 为例,演示如何获取对应群组中的管理员以及成员列表。
访问https://www.facebook.com/groups/Homesteads.and.Sustainability/members/
,通过查看chrome的network中的请求和返回的response进行分析:
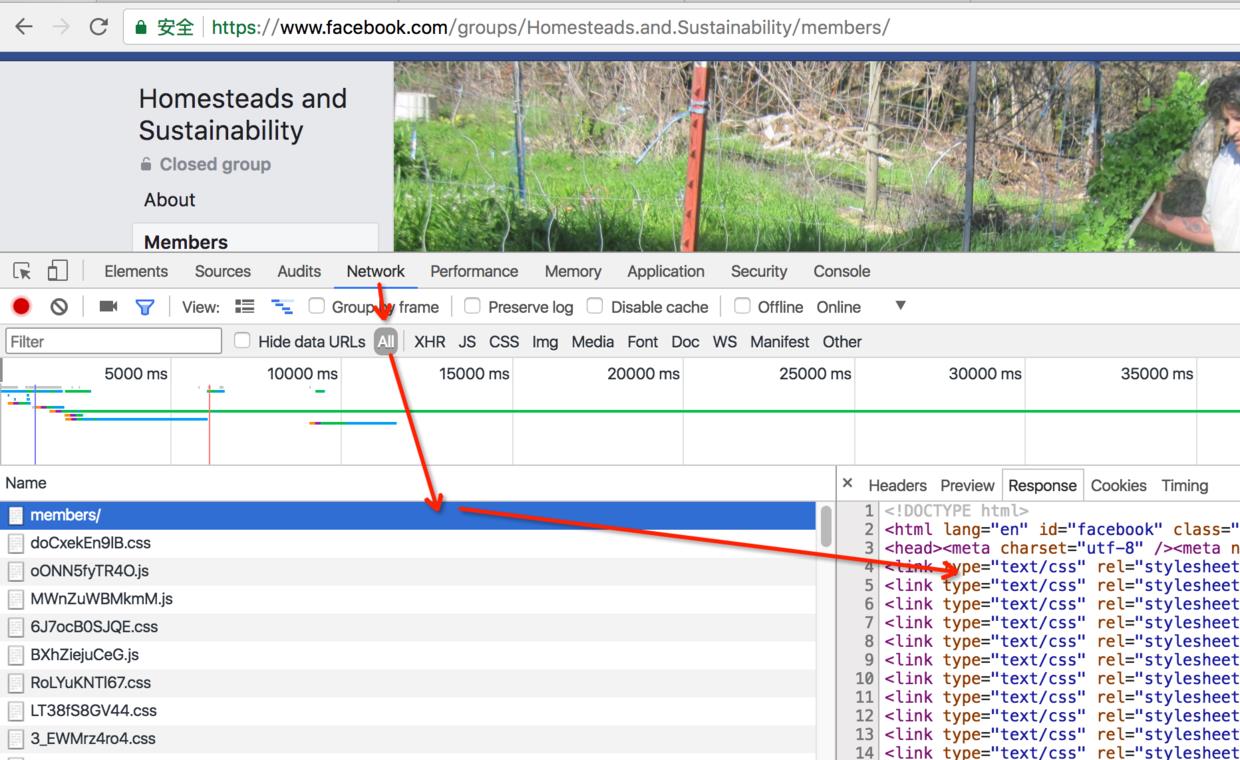
将response中的html拷贝出来,通过查找首次加载页面中显示的人名,定位到管理员和成员对应的html信息如下(位于id为groupsMemberBrowser的Element中):
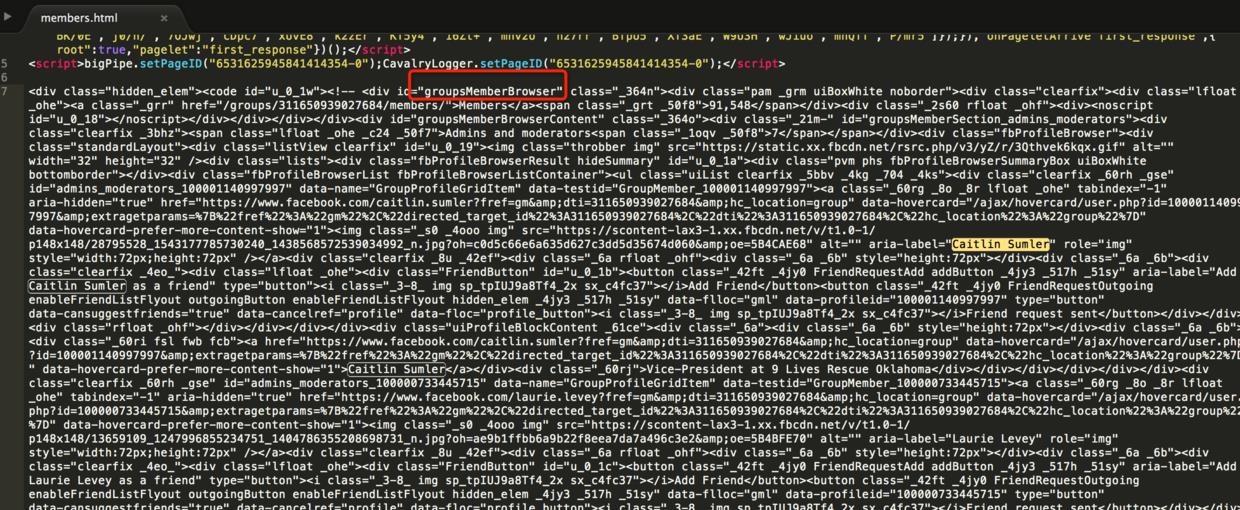
格式化文本后,再进行详细的分析:
区分管理员和普通成员,以及获取他们的id,可以通过下图所示的前缀规则识别出来:
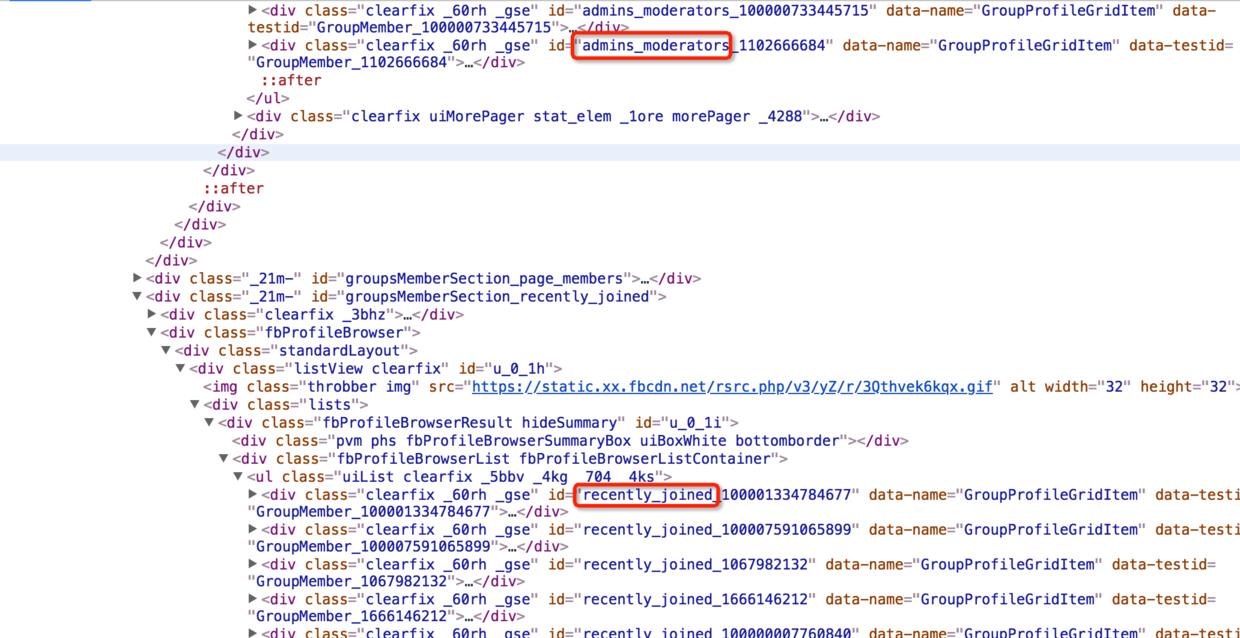
大致代码如下:
private List<FbGroupUserInfo> getMembers(Element groupsMembersElement, int role)
String prefix = role == Constants.GROUP_ROLE_ADMIN ? "admins_moderators_" : "recently_joined_";
List<FbGroupUserInfo> userInfoList = new ArrayList<>();
Elements memberElements = groupsMembersElement.select(String.format("div[id^=%s]", prefix));
if (memberElements != null && memberElements.size() > 0)
for (Element e : memberElements)
String id = e.attr("id").replace(prefix, "");
String nickName = e.select("a img").first().attr("aria-label");
String userName = e.select("a").first().attr("href").split("\\\\?")[0];
userName = userName.substring(userName.lastIndexOf("/"));
Elements joinElements = e.getElementsByClass("_60rj");
String joinDate = joinElements.size() > 0 && role == Constants.GROUP_ROLE_GENERAL
? joinElements.first().text().trim() : "";
FbGroupUserInfo userInfo = new FbGroupUserInfo();
userInfo.setId(id);
userInfo.setNickName(nickName);
userInfo.setUserName(userName);
userInfo.setJoinInfo(joinDate);
userInfo.setRole(role);
userInfoList.add(userInfo);
return userInfoList;
上面我们只是通过解析首次访问的html文本获取到对应的成员信息,但是我们知道群组中的成员是远远不止这几个的,我们通过触发网页页面中的加载更多可以看到,每次往下,都会发起请求获取更多成员信息:
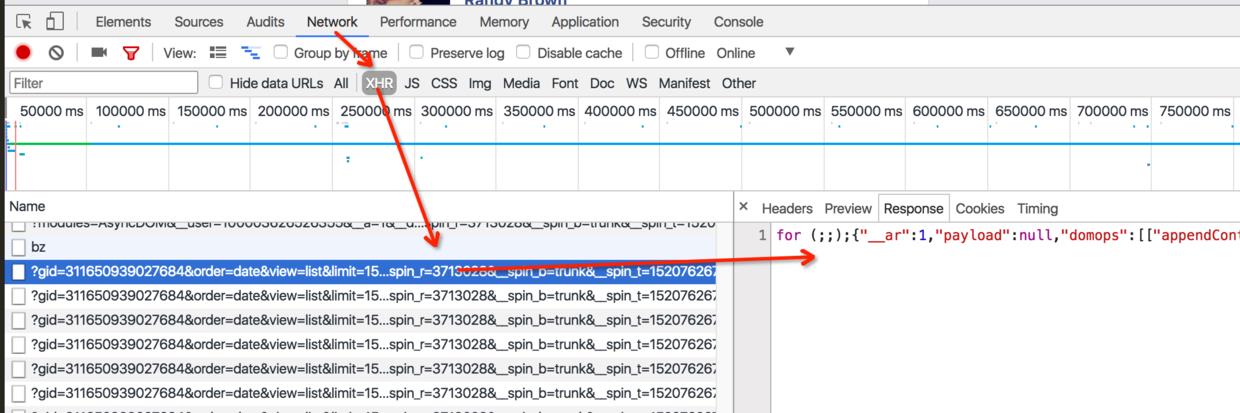
那么,这个请求更多数据的url从哪里获取呢?回头看首次返回的html,可以看到:
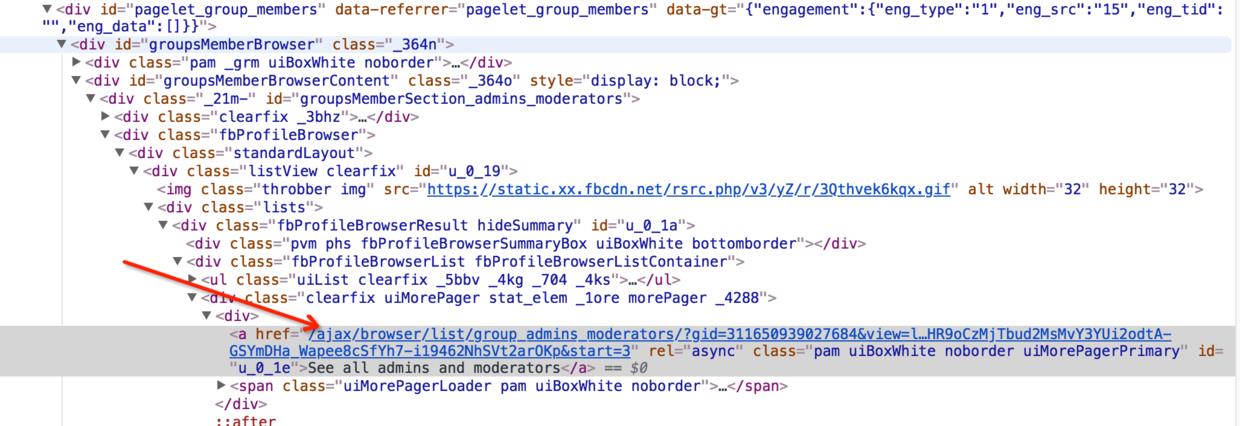
获取加载更多的url代码大致如下:
private String getMoreItemUrl(Element groupsMembersElement, int role)
String prefix = role == Constants.GROUP_ROLE_ADMIN ? "group_admins_moderators" : "group_confirmed_members";
String moreItemUrl = "";
try
moreItemUrl = groupsMembersElement.select(String.format("a[href^=/ajax/browser/list/%s/]", prefix))
.first().attr("href");
catch (Exception e)
return moreItemUrl;
第一次我们通过分析首次的html可以知道第一批成员以及第一个加载更多的url,那么接下来第二次以及之后每次返回的都是json数据了。同样的,通过分析返回的json格式,可以看到,json中的成员信息也是以html的文本返回的,依葫芦画瓢,不断循环直到没有加载更多的url,这样就可以获取到所有成员的id和nickname了。
获取ajax返回数据中的groupMembersElement,大体代码如下
ajaxString = ajaxString.substring(ajaxString.indexOf(""));
ObjectMapper m = new ObjectMapper();
JsonNode rootNode = m.readValue(ajaxString, JsonNode.class);
String html = rootNode.get("domops").get(0).get(3).get("__html").getValueAsText();
Element groupMembersElement = Jsoup.parse(html, "", Parser.xmlParser());但是,只是获取到成员的id和nickname还不够,我们需要获取到成员更详细的信息:故乡、居住地、性别等。
3.获取用户详细信息
下面以 own a salon 这个Facebook用户为例,演示如何获取用户详细信息。
这里通过访问手机版页面(手机版页面获取信息更方便)https://m.facebook.com/profile.php?v=info&id=100005502877898
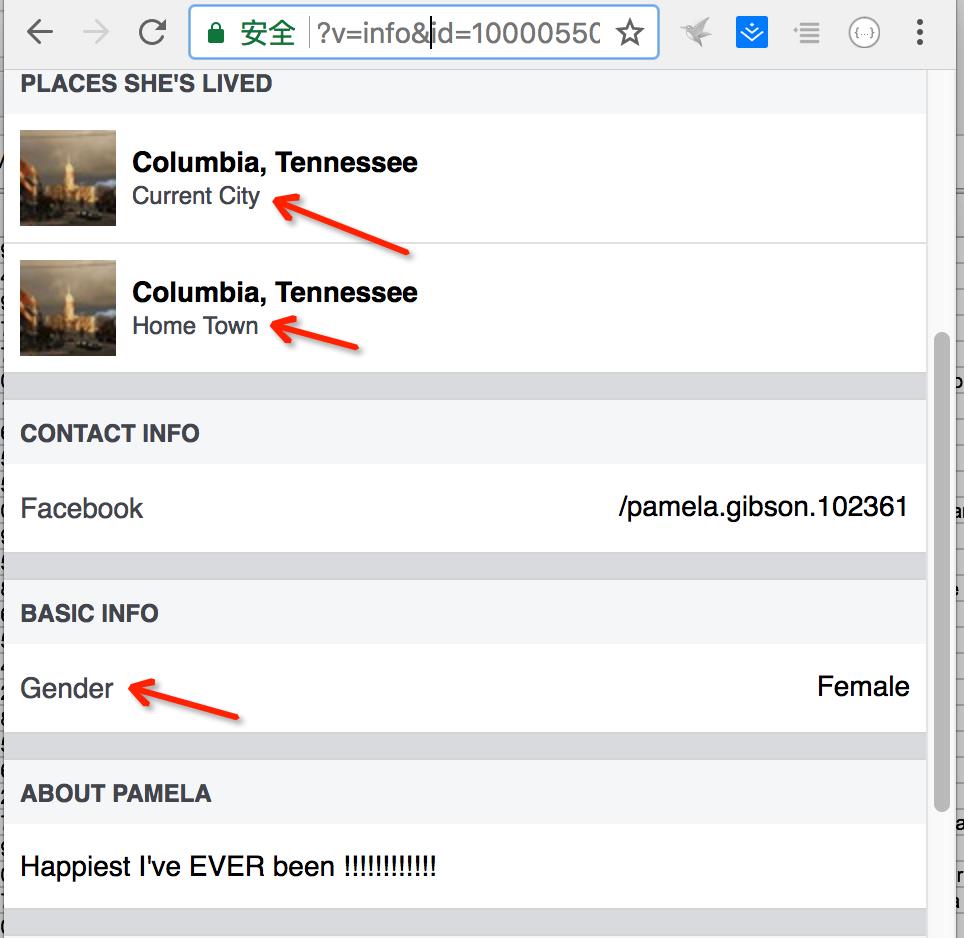
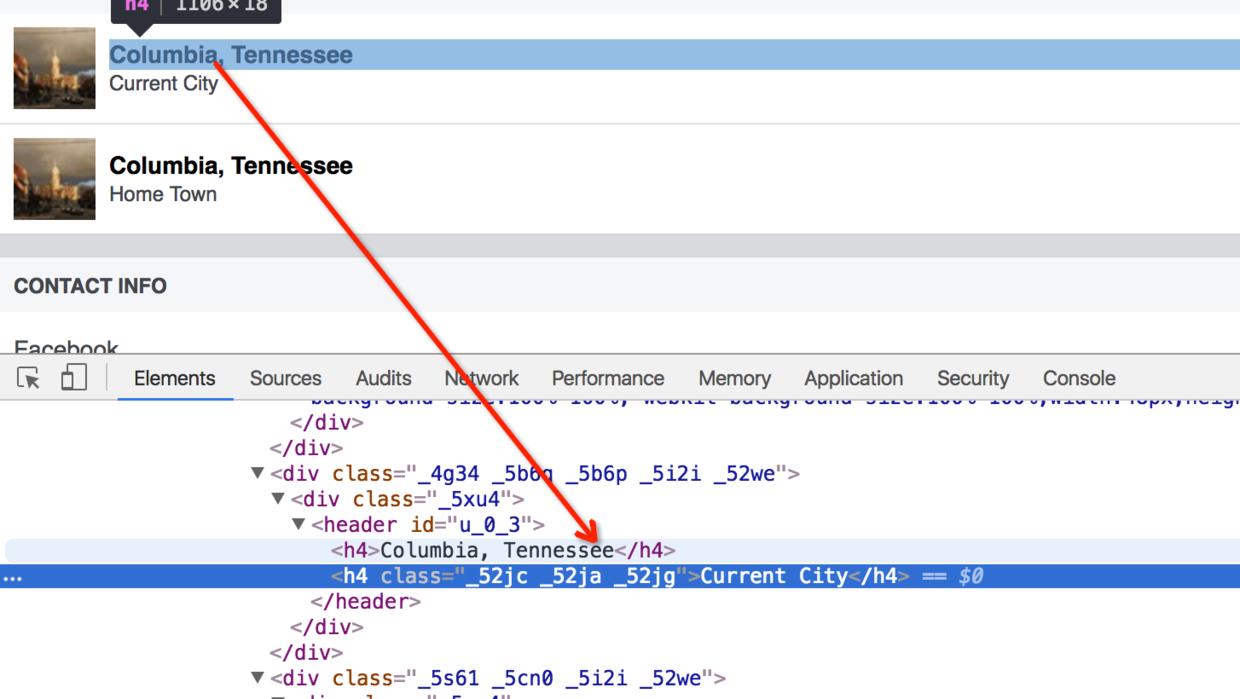
很明显的,我们可以通过html中的关键字来获取对应的故乡、居住地、性别等。大致代码如下:
public FbUserInfo getUserInfo(String userId) throws Exception
// Urls.USER_PROFILE = https://m.facebook.com/profile.php?v=info&id=%s;
String url = String.format(Urls.USER_PROFILE, userId);
Document doc = requestDocument(url, HTTP_GET, null);
Elements userNameElements = doc.select("div[title=Facebook] div div");
Elements genderElements = doc.select("div[title=Gender] div div");
Elements hometownElements = doc.select("h4:contains(Home Town)");
Elements locationElements = doc.select("h4:contains(Current City)");
String userName = userNameElements.size() > 0 ? userNameElements.first().text().trim() : "";
String gender = genderElements.size() > 0 ? genderElements.first().text().trim() : "";
String hometown = hometownElements.size() > 0 ? hometownElements.first().firstElementSibling().text().trim() : "";
String location = locationElements.size() > 0 ? locationElements.first().firstElementSibling().text().trim() : "";
FbUserInfo userInfo = new FbUserInfo();
userInfo.setId(userId);
userInfo.setUserName(userName);
userInfo.setGender(gender);
userInfo.setHometown(hometown);
userInfo.setLocation(location);
return userInfo;
4.最终效果
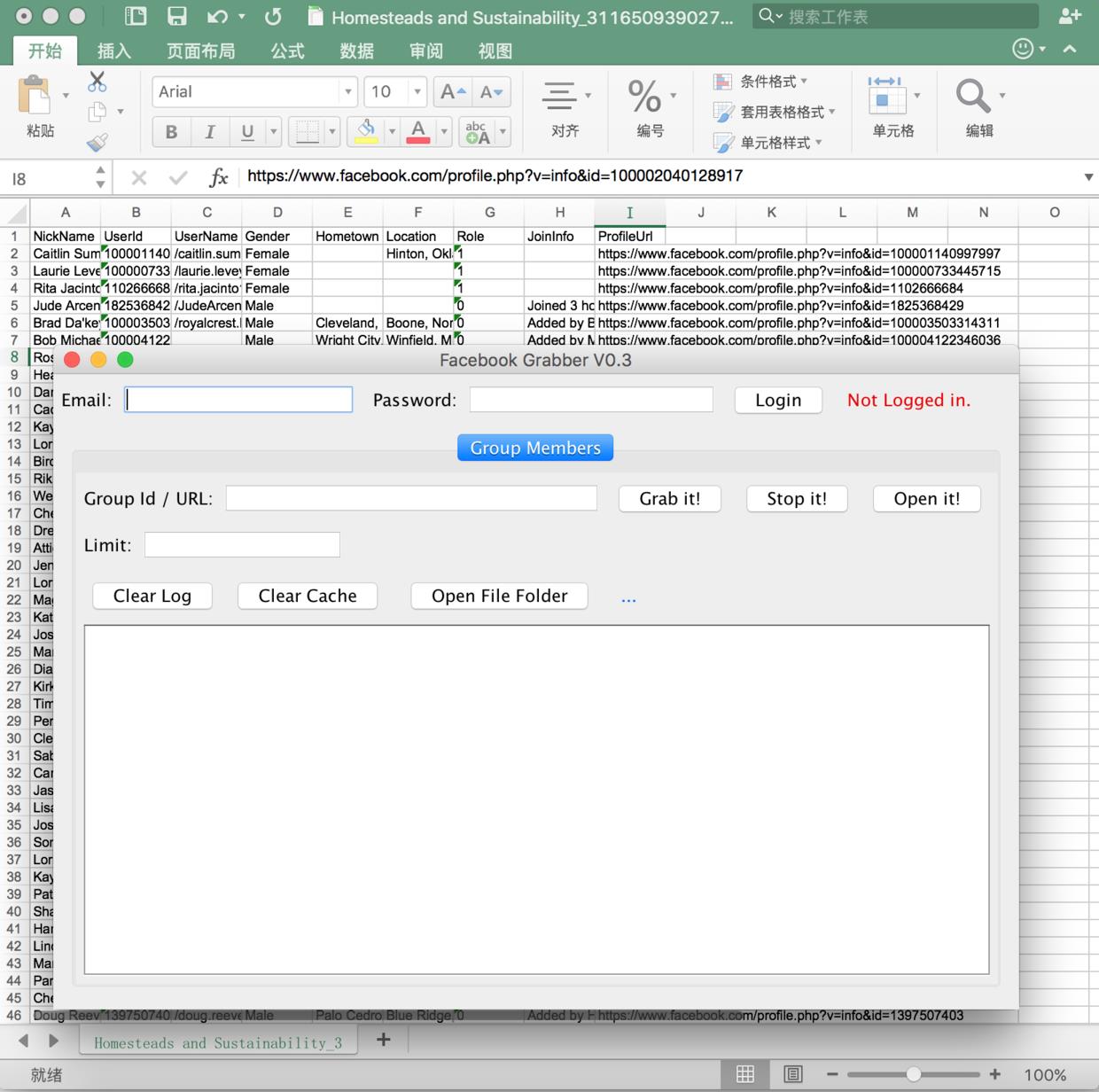
以上是关于爬虫实践-基于Jsoup爬取Facebook群组成员信息的主要内容,如果未能解决你的问题,请参考以下文章
Java爬虫实战:Jsoup+WebClient实现音乐爬取~