Java爬虫实战:Jsoup+WebClient实现音乐爬取~
Posted fntp
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java爬虫实战:Jsoup+WebClient实现音乐爬取~相关的知识,希望对你有一定的参考价值。

今天聊得话题也很简单,起因是我的兄弟,问我有没有免费的音乐播放器,其实一开始我是拒绝的,因为这些东西传播是不合法的,但是从学习的角度,我觉得我有必要给大家科普一下这个网络资源的获取的问题,以及,借此机会给支持我的粉丝们来一点硬核的技术文章,本次更新技术类博客的目的一来是为了教大家如何使用基于Java的爬虫工具对网络资源进行定向爬取,但是切记,不可爬取付费资源!本文案例介绍的是非付费资源的爬取介绍,这里我先埋下一个伏笔,我此前一直在致力于网络爬虫,自研了一个Java爬虫框架,名字叫做stupy框架,结合Spark,scalar实现数据分析,数据挖掘,以及附加的网络资源爬取等功能,目前还在开发的过程中,融入了机器学习的内容,借以实现自动化爬取,以爬取的网络数据直接作为训练集训练爬取的目标,提升模糊爬取的准确性,支持无定向爬取与模糊爬取以及定向爬取和自动化爬取等,有了解过magi的同学应该比较理解我所说的含义了,好了,对于我个人的框架我先介绍这些,剩下的等我开发完了就第一时间在CSDN开源,给大家免费用!
序言
其实早在2021年初,我就与我的好兄弟开源过一个android的音乐软件,遵循GPL3.0开源协议,大家可以去看看,顶点音乐,这就是最经典的基于Java爬虫的网络音乐播放软件,最新版本的顶点音乐已经无付费资源爬取,只为学习交流,如下图:顶点音乐官网
软件更新页面:

软件截图:

下载音乐:

软件首页
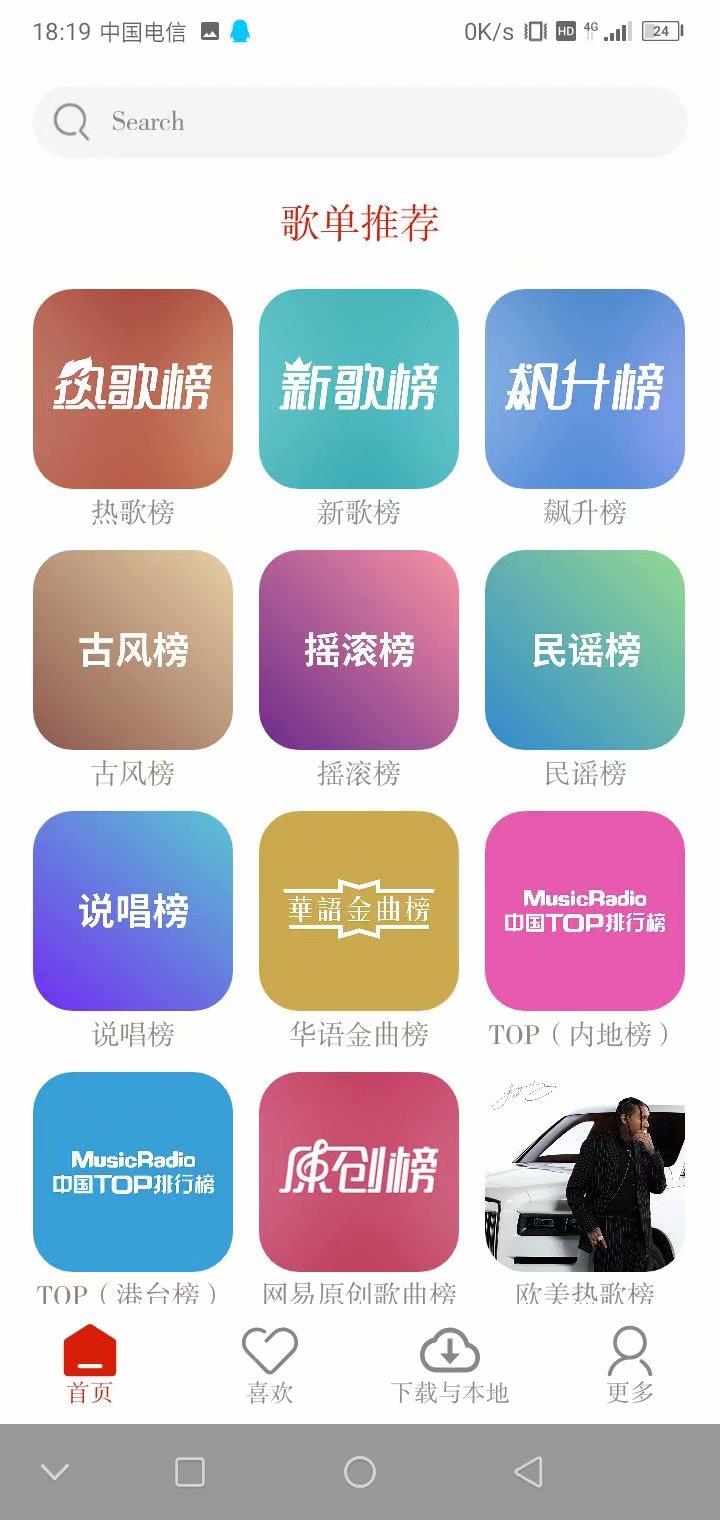
其实软件的整个页面设计与交互都是我的兄弟一手设计的,我只负责了后端的数据获取部分,没错,也就是我们今天要讲的核心内容,Java爬虫!好的,我就不拐弯子了,大家一眼就能看出来这东西有什么用,但是需要注意,我仅仅是为了学习交流,请CSDN的各位同学禁止用于非法途径!技术不是我们目中无法的理由!请慎行!

第一步 了解爬虫基本原理
爬虫(Web crawler)没有什么好神秘的,爬虫你可以理解为就是一系列的脚本,因为爬虫只是将复杂的过程批处理化,你可以就这么理解,爬虫,爬,什么意思,记不记得九齿钉耙,没错,猪八戒的,倒打一耙的耙,有什么用呢?过滤,筛选,也就是选择器,选择出我们所需要的数据,过滤掉我们所不需要的数据,明白了吧!就是这么理解。要想系统化的了解爬虫,需要你有XML以及html的知识储备,如果你没有的话,你需要去恶补一下啊,我这里不赘述了。

我直接一句话告诉你,爬虫就是模拟客户端发送网络请求,接收请求响应,然后按照一定的规则自动的定向解析DOM树的Node节点,直接或者间接获得DOM节点中的value,也就是数据!这就是爬虫。

什么是Dom树?举个简单例子,如下图:

所以你说爬虫他神奇吗?神奇个der,唯一有点难度的地方一是接口验证,这是爬取接口的时候需要的身份验证。这里举一个网易云的例子:网易云的api验证采用的是异步加密处理,前台发起post请求后,本地将数据使用AES加密算法加密,根据来自服务端的随机16位ASC参数,对enSecKey进行加密,使用CBC模式,好奇的是既然都采用了AES算法为何不用CFB模式,这样解密不就复杂多了吗,加密的参数都还是固定的,并且代码有注释,所以早期的网易云api,很容易被抓到,现在不知道换没换…

二是地址信息的匿名封装,就是防止你的IP被封。通常大数据量的请求服务器,如果是同一个IP,很容易被封,你说人家运维半夜被叫起来维护服务器,性能都被你这个爬虫给搞烂了,人家不得哭死啊,封你IP还不是正常操作吗?所以,兄弟们,适量搞搞就得了,不要把人家服务器搞崩了。

了解爬虫的主要用途

(1)数据挖掘引深的数据分析
(2)网络媒体资源的定向获取
(3)数据采集
爬虫与实际生活的联系

爬虫其实与我们的生活息息相关,例如:解析百度文库的时候就有很大的作用。记得有一次女朋友催我给他下载百度付费文档,于是我借助第三方解析网站可以实现下载预览部分的内容,这其实就是爬虫。首先第一步利用爬虫工具模拟浏览器事件,动态加载js脚本获得完整网页,这并不是什么难点。然后第二步就可以用不同的方法,如果采用传统暴力的方式遍历dom节点,那么需要编写脚本来实现模拟点击网页标签触发点击事件,然后便可获得预览内容,由于大多数VIP文档都可以预览,所以理论上获得了预览内容就可以获得完整文档。完整文档把总体文档资源分为文字部分和图片部分。文字的获得有多种途径,一种是dom节点遍历,一种是指定节点爬取,百度这种网站很多东西都是重复性使用的,这就包括鑫软晨报爬取新闻时候获得的新闻文字所在的标签,都是复用性的。另一种获得文字的方法更为简洁,就是文字识别法,也就是ocr模式识别,相当于是用空间代价换取解析速度。这其实对于普通开发者来说,也是一定程度的成本,因为国内提供文字识别服务的厂商大多都是付费的。我反复对比了一些文档解析的网站,基本推断出服务的实现不是文字识别而是dom节点的遍历,遍历同时记录dom树结构,然后将结果按照原树结构还原。这就是文档解析的核心流程。对于文档图片化的内容,无非还是ocr模式识别。原理都相当。其实相信大多数开发者在使用这些工具时候,能基本猜测出解析的过程,只是疲于学习工作,没有精力去自己动手了,我亦是如此。

实操Java爬虫:Jsoup+webclient

第一步 创建Webclient浏览器对象
对于一些难以直接伪装越过服务器验证的网站,我们可以采用微型浏览器的代理方法来实现网络爬虫,为什么?因为网络爬虫爬的对象是HTML与XML的dom树,又不是哪一个指定的网站,所以啊,我们大可不必花费时间在身份验证上,直接模拟一个小型浏览器即可!
/**
* TODO:有代理的web浏览器抓取的Client客户端
* TODO:默认为谷歌浏览器
* @param hostIpAddress
* @param hostPort
* @return
*/
public static WebClient getReadyWebClient(String hostIpAddress,int hostPort)
//设置本地代理
webClient = new WebClient(BrowserVersion.CHROME, hostIpAddress, hostPort);
// 取消 CSS 支持
webClient.getOptions().setCssEnabled(false);
// 保留 javascript支持 ✔
webClient.getOptions().setJavaScriptEnabled(true);
//是否使用不安全的SSL
webClient.getOptions().setUseInsecureSSL(true);
//状态码错误时,是否抛出异常
webClient.getOptions().setThrowExceptionOnFailingStatusCode(true);
//等待js时间
webClient.waitForBackgroundJavaScript(60*1000);
//设置超时时间
webClient.getOptions().setTimeout(65000);
//直接返回
return webClient;
第二步:设置请求头
这是将请求头的信息封装进入Map集合中,我们需要知道浏览器发起请求的方式以及浏览器请求服务器的标准格式,我这里,仅仅是对请求头部分做了说明:
public static Map<String,String> setHeaders()
headerMap = new LinkedHashMap<String, String>();
headerMap.put("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36");
headerMap.put("Cookie", "nts_mail_user=stickpoint@163.com:-1:1; _iuqxldmzr_=32; _ntes_nnid=b49621477869026d8f2893ae6245e6ca,1617787746798; _ntes_nuid=b49621477869026d8f2893ae6245e6ca; NMTID=00ObXGNe6f1I-KkwkFWnO_7sTlGY68AAAF4q6n_JQ; WM_TID=AF2215MJFaVBQUUBAUY%2BwI3fmN1RED6F; P_INFO=mysinsy@163.com|1617787767|0|mail163|00&99|hlj&1617699533&carddav#hlj&230600#10#0#0|&0|youdao_zhiyun2018&mail163|mysinsy@163.com; pver_n_f_l_n3=a; vinfo_n_f_l_n3=255d04cb1a59be57.1.0.1619616177348.0.1619616199659; JSESSIONID-WYYY=E5TA%2Bd3SvayzS%5Ca2M%5CKZxqgy3%5CjlbTlKo8yDD7cr3PP7xegkxygJoi%2FGE%2BQzJZxBH6lVl6%5CSyMEVdO4RAjSMZ1YXdgWv4vwkKgBCtYbVHOuwR%5CfY%5C58kQorsaD89tWr3Wb8Np%5C%2B%5CdsbvQ%2FwGZIPkBYRvAJCXFPsB0slUvoJeW3HresV0%3A1620051123573; WEVNSM=1.0.0; WM_NI=YSmXQ%2FIohuG62lg6v%2BExREPzBjtfl3AnvGCF724VYlIpF3quDjzOb%2F4pPmwW5SVjBOSEUqfQ%2BPwmPjv2K9gblnjiEpXJVaQM%2Fo1QcuWIA0OhYi6ZONlix%2BaRvPhSt7rncU0%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6ee9af025a39396d6cf5a8cb08ab2d15e869a8f84f57db5b187b0b139f68da584c92af0fea7c3b92a9b8da3b9d4258bb1a896c63ef2b4a9d7f52187a89ea6d37282b6bc87ef3983b2baa8c24ef5eefcb7dc688bb08ad4f47f88b6b6b0e125f8b0a08ef65df78d9a8bc145919b9b92e55be990b98ed362b6ee85dae66ab0b2a68ac87c9c969a82d447edb1ffb2e27f95978fd1ce649bb7fabbce46b0b7b8cce45ab690a8b4f73db2b2adb6b337e2a3; __csrf=d29f199b16fe492a7a177cccf6e94cc1; __remember_me=true; MUSIC_U=bd490159dfb5062a7295e6816e93836a05947b73657916bb1c7677a3a66d938433a649814e309366; ntes_kaola_ad=1");
return headerMap;
public static Map<String,String> universalHeaders()
headerMap = new LinkedHashMap<String, String>();
headerMap.put("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36");
return headerMap;
第三步 准备Jsoup的连接
这是为Jsoup准备Connector的连接,以便于获得Connection
public Connection getConnection(String url)
connection = Jsoup.connect(url);
connection.headers(setHeaders());
return connection;
public Connection getConnectionUniversal(String url)
connection = Jsoup.connect(url);
connection.headers(universalHeaders());
return connection;
第四步 :获得服务器响应的文档或者是Json
由于我们进行爬取的时候,有的时候收到来自服务器的响应是json数据,有的时候是html文件,这就取决于服务器的响应内容了。因此,做好两手准备最好。
public Document getDocUniversal (String url)
try
return getConnectionUniversal(url).timeout(5000).get();
catch (IOException e)
e.printStackTrace();
return null;
public static String getJson(String reqUrl) throws IOException
Response res = Jsoup.connect(reqUrl)
.header("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64; rv:48.0) Gecko/20100101 Firefox/48.0")
.timeout(10000).ignoreContentType(true).execute();
String json = "";
json=res.body();
return json;
第五步 执行连接,获得服务器的返回数据
这里是最为关键的数据,因为这里我们借用的是webclient浏览器,通过这个东西,可以直接让她代替我们进行点击事件的触发,让他自己去输入,然后点击搜索,我们只负责拿到最后返回的数据即可!因为拿到服务器响应的数据没我们就可以交付给Jsoup来进行Dom节点的遍历,获得指定节点下的数据。
readyWebClient= HttpReq.getReadyWebClient();
//获得首页页面
HtmlPage htmlPage = readyWebClient.getPage(reqUrl);
//截取搜索框
HtmlTextInput input = (HtmlTextInput)htmlPage.getElementById("query");
HtmlTextInput myInput =(HtmlTextInput) htmlPage.getElementById("myInput");
//填充内容
input.setValueAttribute(searchSeed);
myInput.setValueAttribute(searchSeed);
//开始截取搜索框
// System.out.println(htmlPage.asXml());
HtmlElement button = null;
DomNodeList<DomElement> buttons = htmlPage.getElementsByTagName("button");
for (DomElement domElement : buttons)
// 根据目标元素 class 属性循环匹配
if (domElement.getAttribute("class").equals("btn btn-primary search"))
button = (HtmlElement) domElement;
//拿到等待js加载之后的网页
HtmlPage page = button.click();
String pageXml = page.asXml();
//最后将指定页面返回即可
return pageXml;
第六步 装载数据
根据我们之前说的,数据都是处于Html的节点中,所以我们获取数据的方式就是遍历可能出现数据的节点(这是针对模糊爬取),针对于定向爬取,我们只需要提前准备好知道目标数据的位置出现在哪里就可以了!则:
//拿到一百首歌
Element list = result.select("[class=list-group]").get(0);
Elements lis = list.select("[class=list-group-item]");
int size = lis.select("[class=list-group-item]").size();
System.out.println("size是"+size);
for (int i = 0; i < size; i++)
String downLoadUrl = lis.get(i).child(2).attr("href");
String singer =lis.get(i).child(3).text();
String musicName = lis.get(i).child(4).text();
Music music = new Music();
music.setUrl(downLoadUrl);
music.setArtist(singer);
music.setTitle(musicName);
musicList.add(music);
//最后将musicList返回
return musicList;
最后我们可以获得如下的解析结果:
我们这里以某某伦的歌曲为案例,我们可以看到:最终爬取到了某董一百首的歌曲,啊,真爽,爬虫白嫖奥利给啊!好了,如果你们还想看什么类型的技术文章,请私信或者是直接文章评论吧!我会尽力满足大家的需求,想要源代码的同学可以留个评论~你的email邮箱,仅为学习交流哦!fntp开源。
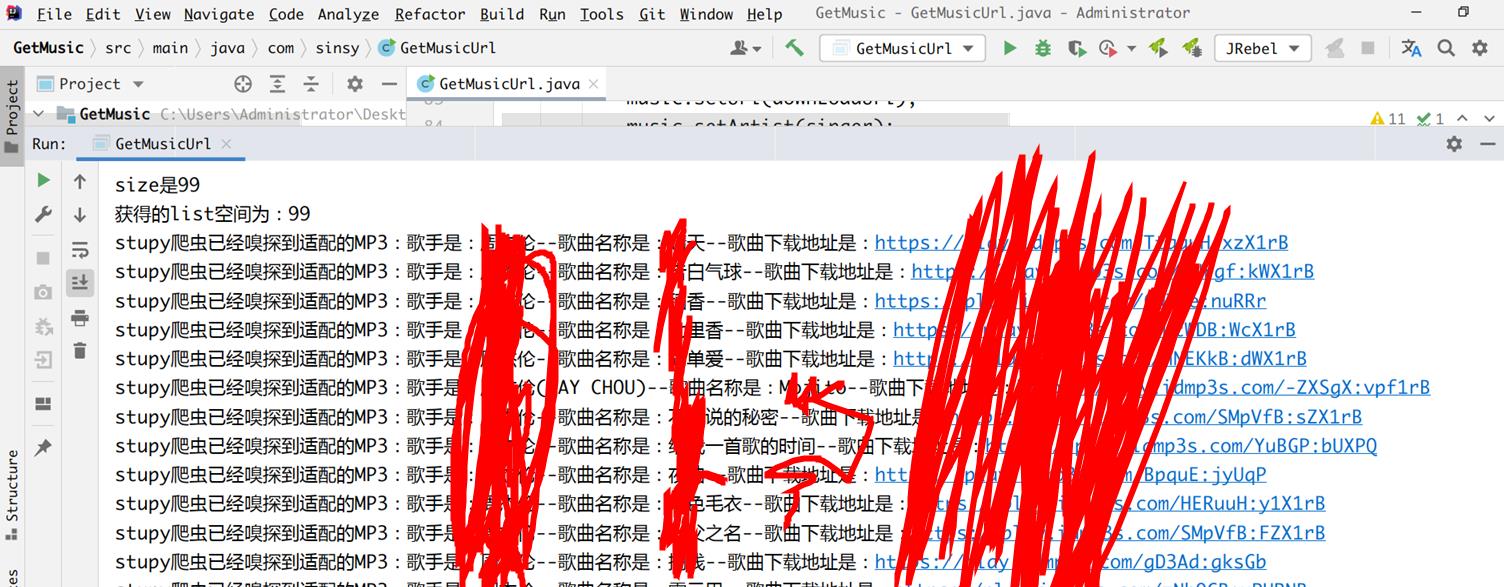
来测试一下是否正确解析了Dom节点,当前资源为非付费资源,这里只是做一个简单演示,结果如下:

以上是关于Java爬虫实战:Jsoup+WebClient实现音乐爬取~的主要内容,如果未能解决你的问题,请参考以下文章