java8中的Stream
Posted miaomiaoLoveCode
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java8中的Stream相关的知识,希望对你有一定的参考价值。
java8提出的函数式编程旨在帮助程序猿们写出更优雅的代码,上文函数式编程基础也介绍了java8新提出的一些函数式接口,通过它们代码貌似已经简洁了一波,但是,代码其实还可以更简洁下,接下来就要开始给大家介绍另一个神器了:Stream,通过它可以进一步利用函数式接口来简化代码了。
注:Stream是java8核心类库中新引入API,它使程序猿们站在更高的抽象层次上对集合进行操作。
常用的流操作
流对象的创建
通过Stream创建流对象:
a. 通过empty方法创建空的流对象:public static<T> Stream<T> empty() return StreamSupport.stream(Spliterators.<T>emptySpliterator(), false);b. 通过of方法创建流对象:
//创建只含有一个元素的流对象 public static<T> Stream<T> of(T t) return StreamSupport.stream(new Streams.StreamBuilderImpl<>(t), false); //创建有多个元素的流对象 public static<T> Stream<T> of(T... values) return Arrays.stream(values);c. 通过iterate方法创建流对象:
public static<T> Stream<T> iterate(final T seed, final UnaryOperator<T> f) Objects.requireNonNull(f); final Iterator<T> iterator = new Iterator<T>() @SuppressWarnings("unchecked") T t = (T) Streams.NONE; @Override public boolean hasNext() return true; @Override public T next() return t = (t == Streams.NONE) ? seed : f.apply(t); ; return StreamSupport.stream(Spliterators.spliteratorUnknownSize( iterator, Spliterator.ORDERED | Spliterator.IMMUTABLE), false);从源码可以看出,该方法会返回一个无限有序的Stream对象,它的第一个元素是seed,第二个元素是f.apply(seed)…第n个元素是f.apply(n - 1元素的值),它一般与limit等方法一起使用,来获取前多少个元素。
我们来看看它是如何和limit方法搭配使用的://定义一个第一个元素 = 10, 后一个元素 = 前一个元素 + 2, 长度为20的集合并输出 Stream.iterate(10, n -> n + 2).limit(20).forEach(System.out::println);d. 通过generate方法创建流对象,它跟iterate方法有点类似,但是它的每个元素都与前一个元素没有什么关系,并且无序,多用于创建常量Stream或者随机Stream,我们来看看它是如何使用的:
//定义一个长度为10的随机字符串集合并输出 Stream.generate(() -> UUID.randomUUID().toString()).limit(10).forEach(System.out::println);e. 通过concat方法连接两个Stream对象生成一个新的Stream对象:
//定义一个长度为3的随机字符串集合 Stream stream1 = Stream.generate(() -> UUID.randomUUID().toString()).limit(3); //定义一个第一个元素 = 0, 后一个元素 = 前一个元素 + 2, 长度为3的集合 Stream stream2 = Stream.iterate(0, n -> n + 2).limit(3); //连接stream1和stream2, 遍历输出 Stream.concat(stream1, stream2).forEach(System.out::println);我们来看下运行结果:
ccf394b2-513c-4d4e-8aa4-b824c95918f4 907b0793-fa19-4cc7-8292-7b7e0818b0a4 a4b8d4a4-80b2-47e0-973e-80694d355ab2 0 2 4通过Collection的stream方法和parallelStream方法创建串行或并行的流对象:
//创建串行流对象
default Stream<E> stream()
return StreamSupport.stream(spliterator(), false);
//创建并行流对象
default Stream<E> parallelStream()
return StreamSupport.stream(spliterator(), true);
我们来看看具体使用:
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
//创建串行流对象
Stream stream = list.stream();
//创建并行流对象
Stream parallelStream = list.parallelStream();流对象的创建基本就这些方式创建了,知道怎么创建了,我们接下来看看流常用的方法。
Stream常用方法
map
元素一对一转换,如果你想将一种类型的值转换成另一种类型的值可以用该方法,它的定义如下:
<R> Stream<R> map(Function<? super T, ? extends R> mapper);从定义可以看出,它接受一个Function参数,元素相关处理转换处理都在Function里实现,同时将处理后的结果放在新的Stream对象中返回。另外,Stream也提供方法针对转换成基本类型(int,long,double)场景:
//转换成int类型
IntStream mapToInt(ToIntFunction<? super T> mapper);
//转换成long类型
LongStream mapToLong(ToLongFunction<? super T> mapper);
//转换成double类型
DoubleStream mapToDouble(ToDoubleFunction<? super T> mapper);我们来看看它是如何使用的:
//定义一个第一个元素 = "1", 后一个元素 = 前一个元素 + "2", 长度为10的集合
List<String> origins = Stream.iterate("1", n -> n + "2").limit(10).collect(Collectors.toList());
//将origins中的字符串转换成int类型并输出
origins.stream().mapToInt(value -> Integer.valueOf(value)).forEach(System.out::println);
//将origins中的字符串转换成User类型并输出
origins.stream().map(value -> new User(value)).forEach(System.out::println);flatMap
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);可以理解成元素一对多转换,从定义可以看出,Stream对象中的每个元素经过Function处理后变成一个多元素的Stream对象,然后将多个Stream拼接成一个新的Stream对象返回。我们来个例子:假如我们有一个字符串列表:[“I”, “Love”, “Programing”],要将该单词列表转换成:[“I”, “L”, “o”, “v”, “e”, “P”, “r”, “o”, “g”, “r”, “a”, “m”, “i”, “n”, “g”]:
Stream<String> origins = Stream.of("I", "Love", "Programing");
//字符串转换
List<String> characters = origins.flatMap(value -> Stream.of(value.split(""))).collect(Collectors.toList());
System.out.println(characters);我们看看输出结果:
[I, L, o, v, e, P, r, o, g, r, a, m, i, n, g]filter
元素过滤,将符合一定条件的元素过滤出来,它的定义如下:
Stream<T> filter(Predicate<? super T> predicate);从定义可以看出,它接受一个Predicate参数,元素条件判断都放在Predicate里,同时将符合条件的元素放在新的Stream对象中返回。我们来看看它的使用:
Stream<String> origins = Stream.of("I", "Love", "Programing");
//输出包含"o"的字符串
origins.filter(value -> value.contains("o")).forEach(System.out::println);match
判断是否有元素符合一定条件,Stream主要提供以下三个方法来实现该操作:
//部分符合,只要有一个元素符合条件时就返回true
boolean anyMatch(Predicate<? super T> predicate);
//全部符合,所有元素符合条件才返回true
boolean allMatch(Predicate<? super T> predicate);
//全部不符合,所有元素都不符合条件时返回true
boolean noneMatch(Predicate<? super T> predicate);collect
在上面的例子中总是能看到将Stream对象转换成集合的时候用了该方法,是一个及早求值操作。其实它的用法远远不止这些,其他用法后续会出文单独分析,这里就不详加赘述了
注:及早求值与惰性求值
判断及早求值与惰性求值很简单,只需要看返回值,如果返回值是Stream,就是惰性求值,如果返回值是另外的值或者为空,则为及早求值。使用流的各种操作的理想方式就是形成一个惰性求值的链,最后用一个及早求值的操作返回想要的结果。只有在对需要什么样的结果和操作有一定的了解之后才能更有效的作出正确计算。
reduce
从一组值生成另一组值,count/min/max其实都是reduce的操作。我们来个小例子:求和
Stream<Integer> origins = Stream.of(1, 2, 3, 4, 5);
//求和
int sum = origins.reduce(0, (m, n) -> m + n);
System.out.println(sum);来个图我们来形象的展示下通过reduce进行累加的一个过程:
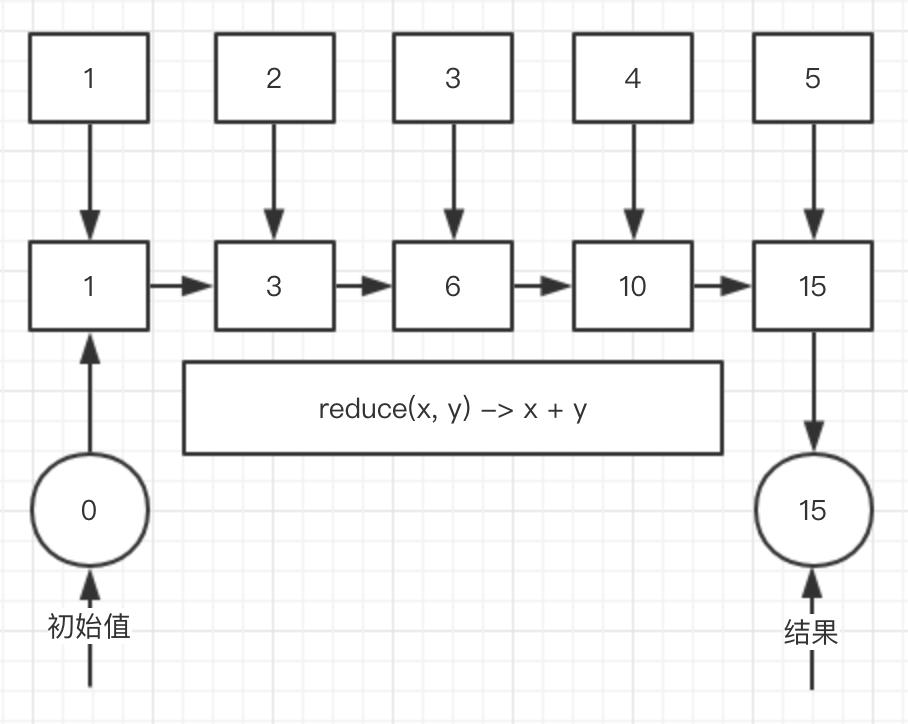
以0作为起点,每一次都将Stream中的元素累加到accumulator,遍历累加到最后一个元素,accumulator里的值其实就是最后的结果。
到这里为止,常用的一些流操作基本上就介绍完了,还有一些去重,排序,查找等简单的内容这里就不做赘述了,有感兴趣的同学可以自行翻阅源码,用法也很简单。
后记
从java8之前的集合操作到java8 Stream对集合的操作,代码更加简单、易读,这一巨大的改变其实是依赖外部迭代 -> 内部迭代这个转变。比如我们遍历求和,java8之前的代码会这样写:
int sum = 0;
for (Integer number : numbers)
sum += number;
虽然这样做其实也不会有问题,但是还是要正面它的不好处:
1. 每次对集合做遍历都要写一堆这样子的代码;
2. 比较难抽象操作,操作和遍历都糅合在一起;
3. 在for循环的模式下再进行性能改造其实比较困难(比如并行);
4. 代码易读性较差,特别是有多重嵌套循环时,看代码的人估计就要崩溃了。
当然咯,for循环就是一个封装了迭代(Iterator)的语法糖,这种遍历模式其实也就是外部迭代。
何谓外部迭代,简单点就是显式地进行迭代操作,比如通过Iterator进行迭代,它的过程就是显式调用Iterator对象的hasNext和next方法完成迭代。
那现在我们通过Stream将其变成内部迭代呢:
Stream<Integer> origins = Stream.of(1, 2, 3, 4, 5);
//求和
int sum = origins.reduce(0, (m, n) -> m + n);所谓的内部迭代,顾名思义,遍历会在集合内部完成,程序猿不需要再去显示的控制循环,也不再需要关心遍历元素的顺序,我们只需要care对元素的操作即可。
以上是关于java8中的Stream的主要内容,如果未能解决你的问题,请参考以下文章