面板数据熵值法-Python
Posted 热爱Python的小菜鸟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面板数据熵值法-Python相关的知识,希望对你有一定的参考价值。
面板数据数据熵值法公式-基于Python
一、理论基础
本文通过王晓红等(2021)中所使用到的面板数据熵值法公式,来讲解如何对面板数据使用熵值法及Python代码的实现,具体过程如下:

二、代码实现
import pandas as pd
import numpy as np
import os
#熵值法
def Entory(path0,forwrd_indicator,inverse_indicator):
df=pd.DataFrame()#创建空的DataFrame
df1=pd.DataFrame()#创建空的DataFrame
#对面板数据进行处理
data=pd.read_excel(path0,sheet_name=None,index_col=0)#用于获取sheet_name的准备工作
Sheet_name=list(data.keys())#data.keys():用于获取所有的sheet_name
for i in Sheet_name:#遍历sheet_name。
df2=pd.read_excel(path0,sheet_name=i,index_col=0)#读取原始数据,即逐个读取sheet
df3=pd.DataFrame(df2.to_numpy().reshape(-1, 1, order='F'))#将读取出的每个sheet转为一列数据
df=pd.concat([df,df3],axis=1)#将每列数据合并成一个DataFrame
x1=df2.shape[1]#获取每个sheet表里的列数
x2=df2.shape[0]#获取每个sheet表里的行数
y=df2.index#获取每个sheet表里的行索引(行名)
z=list(df2.columns)
df.columns=[i for i in Sheet_name]#重命名列索引(列名)
df.insert(0,"城市",list(y)*x1)#插入城市列
df.insert(1,"年份",sorted(z*x2))#插入时间列
df=df.set_index(["城市","年份"])
#熵值法
#正、负向指标处理
df4=df.copy()
forwrd_indicator=[i for i in forwrd_indicator]
inverse_indicator=[i for i in inverse_indicator]
if forwrd_indicator:
inverse_indicator=list(set(forwrd_indicator) ^ set(Sheet_name))
else:
forwrd_indicator=list(set(inverse_indicator) ^ set(Sheet_name))
print("正向指标forwrd_indicator:\\n",forwrd_indicator)
print("\\n")
print("逆向指标inverse_indicator:\\n",inverse_indicator)
print("\\n")
if forwrd_indicator or inverse_indicator:
df4[forwrd_indicator]=(df4[forwrd_indicator]-df4[forwrd_indicator].min())/(df4[forwrd_indicator].max()-df4[forwrd_indicator].min())
df4[inverse_indicator]=(df4[inverse_indicator].max()-df4[inverse_indicator])/(df4[inverse_indicator].max()-df4[inverse_indicator].min())
df4=df4.apply(lambda x:x+0.01)#为避免 ln0 的影响,进行数据平移,可根据个人需求自行修改数值
df5=df4/df4.apply(lambda x:x.sum())#计算各个数据在对应列中所占比重
k=np.power(np.log(df5.shape[0]),-1)#计算k
p=df5/df5.apply(lambda x:x.sum())
P=(p*p.apply(np.log)).sum()#上面求熵值的公式中k的后面那一部分
entory=-k*P#计算各列的熵值
D=1-entory#计算各指标熵值的差异系数
W=D/D.sum()#计算各指标权重
# print("权重:\\n",W)
print("\\n")
#结果汇总
df1=pd.concat([df1,pd.DataFrame("max":[i for i in df.max().values],#未开始熵值法前数据中每一列的最大值
"min":[i for i in df.min().values],#未开始熵值法前数据中每一列的最小值
"range":[i for i in df.max().values-df.min().values],#未开始熵值法前数据中每一列的极差
"sum":[i for i in df4.sum().values],#标准化+数据平移后,各个数据在对应列的权重按列求和
"k":[-k,0],
"sum2":[i for i in P],#计算信息熵时,公式里k后面的那一部分
"ENT":[i for i in entory],#各列(各指标)的熵值
"D":[i for i in D],#各列(各指标)的熵值
"W":[i for i in W])],axis=1)#各列(各指标)的权重
df1=df1.T
df1.columns=[i for i in list(df.columns)]
print(df1)
print("\\n")
#将数据和结果写入Excel表格
excel_to_path=os.path.join(os.path.split(path0)[0],"熵值法.xlsx")
with pd.ExcelWriter(path=excel_to_path) as writer:
df.to_excel(writer, sheet_name='面板数据')
df1.to_excel(writer, sheet_name='权重')
print("结果已保存到路径下".format(excel_to_path))
path0=r"C:\\Users\\HP\\Desktop\\python.xlsx"#目标文件路径(自己填)
forwrd_indicator=["用水量","人均GDP增长率"]#正向指标。正负向指标填一个即可,为方便,可以填少的那个(自己填)
inverse_indicator=[]#负向指标
Entory(path0,forwrd_indicator,inverse_indicator)#不用管
三、实例
在本例中,求用水量与GDP增长率这两个指标所占的比重。
数据格式如下图所示:
注:每个指标单独放在一个sheet表里
-
数据来源:中国统计年鉴
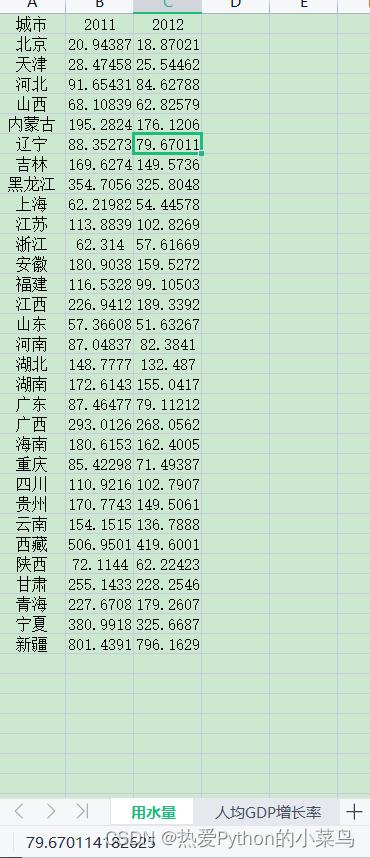
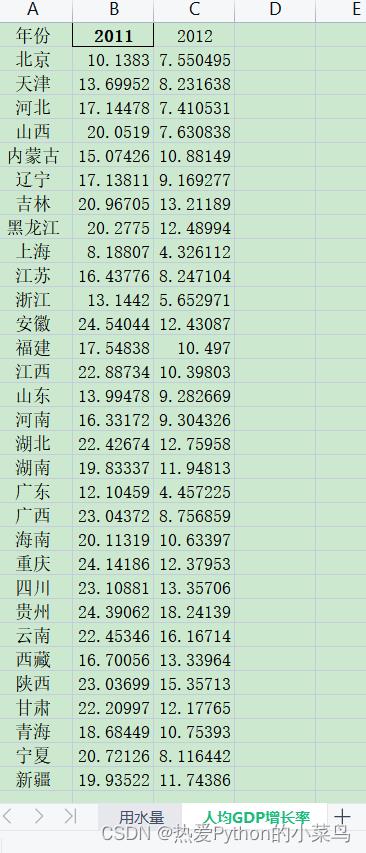
-
代码实现过程
此步骤见第二步 -
结果
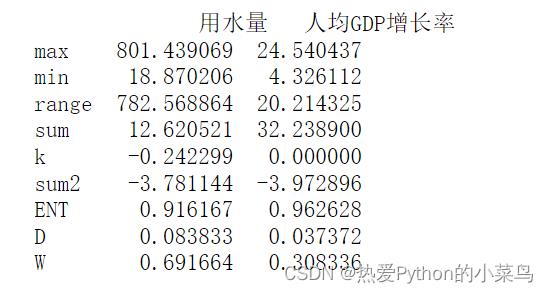
其中,最后一行W为各指标的权重,其余各行说明详见代码实现部分
四、结果验证
为验证结果的正确性,此处使用spssau进行验证,结果如下图所示:

比较二者的结果,可认为本文所提供的代码具有一定的合理性。
五、说明
在计算信息熵时(如下图所示),由于我们对数据采用的是极差标准化方法,使得标准化后的数据的取值范围在[0,1]之间,也就是说该方法会使得部分数据取到0,而在计算信息熵时(如下图所示),ln0是无效的。而在相关文献中关于P的处理,有以下两种:一种是对标准化后的数据进行平移(本文中采取该方法),另一种则是令P*lnP=0。因此,对于这两种方法所求出来的权重之间的差异如何,本文在此利用上文中的数据对第二种方法进行计算。
第二种方法的处理方式:将下列代码删除即可
df4=df4.apply(lambda x:x+0.01)#为避免 ln0 的影响,进行数据平移,可根据个人需求自行修改数值
结果对比:

由上述结果来看,不同方法求出的权重的确不同,但两者相差大概在0.01左右。因此可根据自己的需求自行选择。
注:本人能力有限,文中错漏之处在所难免,请各位多多包涵。
以上是关于面板数据熵值法-Python的主要内容,如果未能解决你的问题,请参考以下文章