熵值法原理及python实现 附指标编制案例
Posted 侯小啾
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了熵值法原理及python实现 附指标编制案例相关的知识,希望对你有一定的参考价值。
文章目录
熵值法也称熵权法,是学术研究,及实际应用中的一种常用且有效的编制指标的方法。

1.简单理解 信息熵
机器学习中的决策树算法是对信息熵的一种典型的应用。
在信息论中,使用 熵 (Entropy)来描述随机变量分布的不确定性。
假设对随机变量X,其可能的取值有
x
1
,
x
2
,
.
.
.
,
x
n
x_1,x_2,...,x_n
x1,x2,...,xn。即有n种可能发生的结果。其对应发生的概率依次为
p
1
,
p
2
,
.
.
.
,
p
n
p_1,p_2,...,p_n
p1,p2,...,pn,则事件
p
i
p_i
pi对应的信息熵为:
H ( X ) = H ( p ) = ∑ i = 1 n p i log 1 p i = − ∑ i = 1 n p i log p i H(X)=H(p)=\\sum_i=1^np_i\\log \\frac1p_i=-\\sum_i=1^np_i\\log p_i H(X)=H(p)=∑i=1npilogpi1=−∑i=1npilogpi
信息熵中log的底数通常为2,理论上可以使用不同的底数。
如何理解信息熵呢,假设已知今天是周日,则对于“明天是周几”这件事,只有一种可能的结果:是周一,且p=1。则“明天是周几”的信息熵 H ( X ) H(X) H(X)为 − 1 × log 1 = 0 -1×\\log 1=0 −1×log1=0,取信息熵的最小值0。表示“明天是周几”这个话题的不确定性很低,明天周几很确定。
再比如抛一枚硬币,则结果为正面和反面的概率都是0.5。则信息熵为 l o g 2 log2 log2,相比“明天周几”这件事的信息熵稍大些了。
假设某事情有100中可能的结果,每种结果发生的概率为0.01。则 H ( X ) = l o g 100 H(X)=log100 H(X)=log100,对于等概率均匀分布的事件,不确定的结果种类越多,则熵越大。
2.编制指标 (学术情景应用)
迁移到编制指标的情形,通过下边一个简单的示例理解熵权法在学术研究中的应用。
以陈浩,刘媛华的论文《数字经济促进制造业高质量发展了吗?——基于省级面板数据和机器学习模型的实证分析》
中部分内容展示为例:
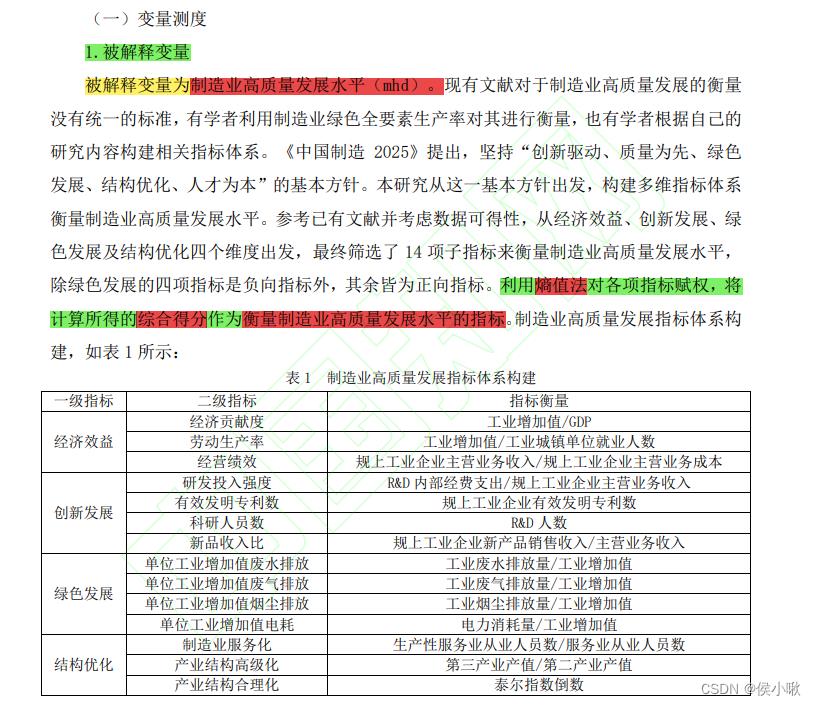
对于离散型的随机变量,某指标在样本中出现的频率即可视为概率P,进而求出每个指标的熵值。
而对于上图中的连续型的随机变量,则在处理思想上与离散型随机变量有所不同。
通常可以先对数据做标准化处理,假设X指标中的第i个样本的标准化处理结果为
Z
i
Z_i
Zi:
(注意对正向指标和负)
则指标X中的第i个样本的权重为:
P
i
=
P_i =
Pi=
Z
i
∑
i
=
1
n
Z
i
\\fracZ_i\\sum_i=1^nZ_i
∑i=1nZiZi
上边说到,指标的熵值计算公式为:
H
(
p
)
=
∑
i
=
1
n
p
i
log
1
p
i
=
−
∑
i
=
1
n
p
i
log
p
i
H(p)=\\sum_i=1^np_i\\log \\frac1p_i=-\\sum_i=1^np_i\\log p_i
H(p)=∑i=1npilogpi1=−∑i=1npilogpi
为了方便求变异系数,这里计算熵值的时候常常在该公式的基础上再乘以一个常数K,即
H
(
p
)
=
−
K
∑
i
=
1
n
p
i
log
p
i
H(p)=-K\\sum_i=1^np_i\\log p_i
H(p)=−K∑i=1npilogpi
其中 K = K= K= 1 l n ( n ) \\frac1ln(n) ln(n)1,n是样本的个数。易知,乘以常数后计算出的熵值,通常范围都是在区间[0,1]内的。
举个例子,假设一共有十个样本,且十个样本的连续型X指标数值非常相近,甚至完全一致。
对数的底数取10,则每个样本的权重都有接近或等于1/10。
通过公式
H
(
p
)
=
−
K
∑
i
=
1
n
p
i
log
p
i
H(p)=-K\\sum_i=1^np_i\\log p_i
H(p)=−K∑i=1npilogpi计算出的熵值则为1,
然后引入一个新的指标“差异系数”来刻画数据之间的差异性大小(即使用1减去熵值得到所谓“差异系数”,不要跟变异系数混淆),
第j个指标的差异系数
d
j
=
1
−
H
j
d_j=1-H_j
dj=1−Hj(H_j为第j个指标的熵值)
计算可知差异系数为0。则说明该指标在数值上不存在任何差异(雀食如此)。
随着数据本身数值上的差距的提升,指标的熵值会逐步减小,差异系数逐渐增大。这样说相信很容易理解了。
指标的熵值越小(差异系数越大),则该指标在最终要编制的指标中所占的权重则越大。
具体的权重计算公式为:
ω
j
=
d
j
∑
j
=
1
m
\\omega_j=\\fracd_j\\sum_j=1^m
ωj=∑j=1mdj
即某指标差异系数占所有指标差异系数和的比重。
上图的情景中,作者首先对二级指标进行衡量,然后使用熵权法,求出每个二级指标的熵值,进而求出权重,分别计算出四个一级指标;
然后再对四个一级指标再次使用熵权法计算权重,进而得到最终指标:制造业高质量发展水平。
3.python实现
3.1 数据准备
为方便读者测试,这边手动生成一段数据作为示例。
将指标1,指标2,指标3,指标4,合并编制为一个“综合指标”。
import pandas as pd
import numpy as np
# 1. 初始数据 假设指标4是负向指标,其余三个为正向指标
df1 = pd.DataFrame('指标1': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'指标2': [2, 4, 6, 8, 10, 2, 4, 6, 8, 10],
'指标3': [1, 2, 1, 3, 2, 1, 3, 2, 3, 1],
'指标4': [3, 1, 2, 3, 5, 8, 7, 8, 8, 9]
)
print(df1)
数据为DataFrame格式,效果展示如下:

3.2 数据预处理
然后是数据预处理部分,这里定义一个泛用性较强的标准化处理函数,
该函数对于正向指标和负向指标(越大越好的指标和越小越好的指标),可以分别进行不同的处理。
(处理逻辑通过代码可以很容易看出)
同时该函数也可以兼容只进行其中一种处理的情景。
# 2.数据预处理 定义标准化处理函数
def Standardization(data,cols1=None, cols2=None):
"""
:param data:目标数据
:param cols1: 需要处理的正向指标列名列表,类型为列表或None [col1, col2, col3]
:param cols2: 需要处理的负向指标列名列表,类型为列表或None [col1, col2, col3]
:return: 输出处理结果
"""
if cols1 == None and cols2 == None:
return data
elif cols1 != None and cols2 == None:
return (data[cols1] - data[cols1].min())/(data[cols1].max()-data[cols1].min())
elif cols1 == None and cols2 != None:
return (data[cols2].max - data[cols2])以上是关于熵值法原理及python实现 附指标编制案例的主要内容,如果未能解决你的问题,请参考以下文章