Kafka3.x核心速查手册三服务端原理篇-1Zookeeper整体数据
Posted roykingw
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka3.x核心速查手册三服务端原理篇-1Zookeeper整体数据相关的知识,希望对你有一定的参考价值。
这一部分主要是理解Kafka的服务端重要原理。但是Kafak为了保证高吞吐,高性能,很多具体实现都是相当复杂的。如果直接跳进去学习研究,很快就会晕头转向。所以,找一个简单清晰的主线就显得尤为重要。这一部分主要是从存储的角度来理解Kafka的Broker运行机制。这对于上一章节建立的简单模型,是一个很好的细节补充。
Kafka依赖很多的存储数据,但是,总体上是有划分的。Kafka会将每个服务的不同之处,也就是状态信息,保存到Zookeeper中。通过Zookeeper中的数据,指导每个Kafka进行与其他Kafka节点不同的业务逻辑。而将状态信息抽离后,剩下的数据,就可以直接存在Kafka本地,所有Kafka服务都以相同的逻辑运行。这种状态信息分离的设计,让Kafka有非常好的集群扩展性。
1、zookeeper整体数据
Kafka将状态信息保存在Zookeeper中,这些状态信息记录了每个Kafka的Broker服务与另外的Broker服务有什么不同。通过这些差异化的功能,共同体现出集群化的业务能力。这些数据,需要在集群中各个Broker之间达成共识,因此,需要存储在一个所有集群都能共同访问的第三方存储中。
这些共识数据需要保持强一致性,这样才能保证各个Broker的分工是同步、清晰的。而基于CP实现的Zookeeper就是最好的选择。
Raft协议是跟Zookeeper的PAXOS协议类似的一种分布式的共识协议,其核心也是通过多数同意的决策方式保证数据的整体强一致性。Kraft集群基于Raft协议进行了适配和改良,将原本存在Zookeeper上的状态数据,改为通过Kraft协议,保存到Kafka的多个Controller节点本身。
Kafka在Zookeeper上管理了哪些数据呢?这个问题可以先了解一下Kafka的整体集群状态结构,然后再去Zookeeper上验证。
Kafka的整体集群结构如下图。其中红色字体标识出了重要的状态信息。
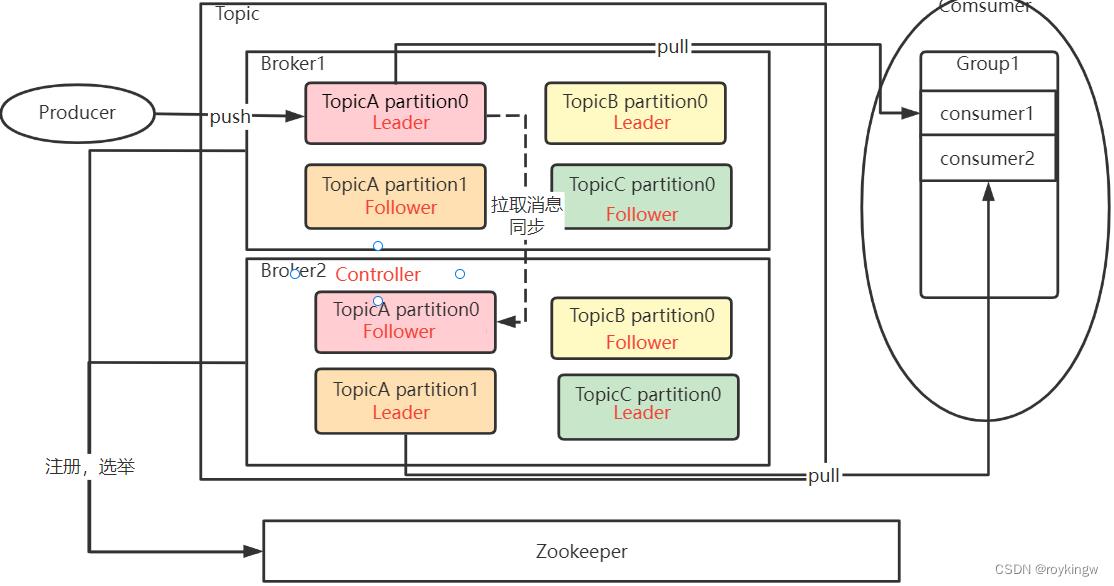
Kafka的集群中,最为主要的状态信息有两个。一个是在多个Broker中,需要选举出一个Broker,担任Controller角色。由Controller角色来管理整个集群中的分区和副本状态。另一个是在同一个Topic下的多个Partition中,需要选举出一个Leader角色。由Leader角色的Partition来负责与客户端进行数据交互。
这些状态信息都被Kafka集群注册到了Zookeeper中。Zookeeper数据整体如下图:

其中,重点需要关注的是/controller目录和/brokers目录。比如/brokers/ids下,会记录集群中的所有BrokerId,/topics目录下,会记录当前Kafka的Topic相关的Partition分区等信息。下面就从这些Zookeeper的基础数据开始,来逐步梳理Kafka的Broker端的重要流程。
以上是关于Kafka3.x核心速查手册三服务端原理篇-1Zookeeper整体数据的主要内容,如果未能解决你的问题,请参考以下文章
Kafka3.x核心速查手册三服务端原理篇-2Broker选举机制
Kafka3.x核心速查手册三服务端原理篇-3Broker故障恢复机制
Kafka3.x核心速查手册三服务端原理篇-3Broker故障恢复机制
Kafka3.x核心速查手册三服务端原理篇-3Broker故障恢复机制