Flink保证exactly-once机制介绍:checkpoint及TwoPhaseCommitSinkFunction
Posted 宝哥大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink保证exactly-once机制介绍:checkpoint及TwoPhaseCommitSinkFunction相关的知识,希望对你有一定的参考价值。
文章目录
一、前言
我们知道exactly-once,大多知道有checkpoint,但是在Flink1.4之后,又新增了端到端的exactly-once。也就是输入和输出是对应的,没有丢失和重复。
1.1、Flink-1.4之前的exactly-once实现
Flink的基本思路就是将状态定时地checkpiont到hdfs中去,当发生failure的时候恢复上一次的状态,然后将输出update到外部。这里需要注意的是输入流的offset也是状态的一部分,因此一旦发生failure就能从最后一次状态恢复,从而保证输出的结果是exactly once。
1.2、Flink-1.4之后的exactly-once实现
2017年12月,apache flink 1.4.0发布。其中有一个里程碑式的功能:两步提交的sink function(TwoPhaseCommitSinkFunction,relevant Jira here)。TwoPhaseCommitSinkFunction 就是把最后写入存储的逻辑分为两部提交,这样就有可能构建一个从数据源到数据输出的一个端到端的exactly-once语义的flink应用。当然,TwoPhaseCommitSinkFunction的数据输出包括apache kafka 0.11以上的版本。flink提供了一个抽象的TwoPhaseCommitSinkFunction类,来让开发者用更少的代码来实现端到端的exactly-once语义。
Flink的 checkpoint在保证exactly-once是内部应用exactly-once,不需要重复计算等
Flink是通过两步提交协议来保证从数据源到数据输出的exactly-once语义(外部)
接下来,我们通过一个例子来解释如果应用TwoPhaseCommitSinkFunction来实现一个exactly-once的sink。
二、Exactly-once Tow Phase Commit
下面我们来看看flink消费并写入kafka的例子是如何通过两部提交来保证exactly-once语义的。
注意: 因为只有kafka 从0.11开始支持事物操作,若要使用flink端到端exactly-once语义需要flink的sink的kafka是0.11版本以上的。 同时 DELL/EMC的 Pravega 也支持使用flink来保证端到端的exactly-once语义。
这个例子包括以下几个步骤:
- 从
kafka读取数据 - 一个聚合窗操作
- 向kafka写入数据
为了保证exactly-once,所有写入kafka的操作必须是事务的。在两次checkpiont之间要批量提交数据,这样在任务失败后就可以将没有提交的数据回滚。
然而一个简单的提交和回滚,对于一个分布式的流式数据处理系统来说是远远不够的。下面我们来看看flink是如何解决这个问题的。
Flink官方推荐所有需要保证exactly once的Sink逻辑都继承该抽象类。它定义了如下4个抽象方法,需要子类实现。
// 开始一个事务,返回事务信息的句柄。
protected abstract TXN beginTransaction() throws Exception;
// 预提交(即提交请求)阶段的逻辑。
protected abstract void preCommit(TXN transaction) throws Exception;
// 正式提交阶段的逻辑。
protected abstract void commit(TXN transaction);
// 取消事务。
protected abstract void abort(TXN transaction);
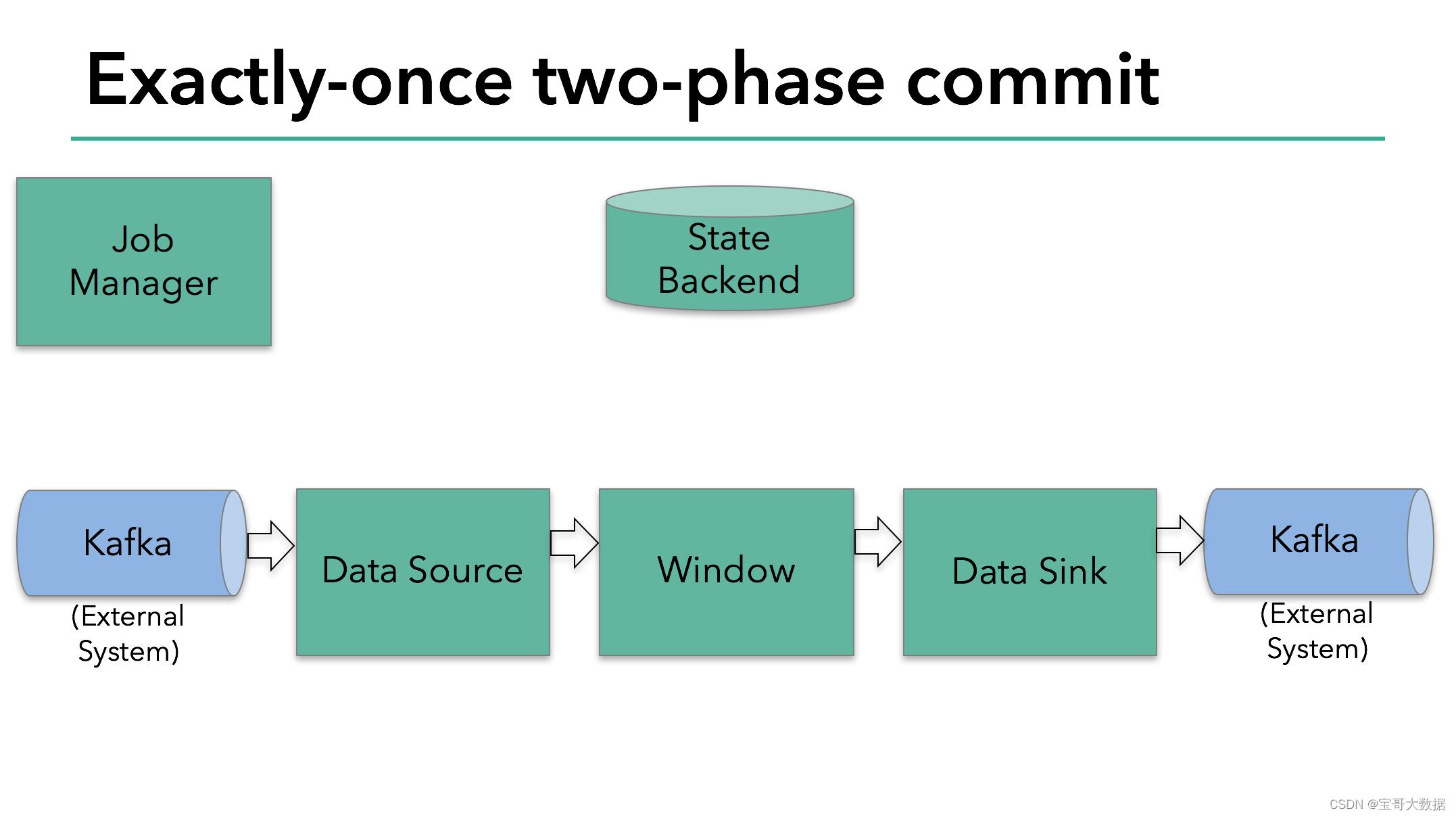
2.1、预提交 (preCommit)
首先我们看下 preCommit 代码实现。
@Override
protected void preCommit(FlinkKafkaProducer.KafkaTransactionState transaction)
throws FlinkKafkaException
switch (semantic)
case EXACTLY_ONCE:
case AT_LEAST_ONCE:
flush(transaction); // 实际上是代理了KafkaProducer.flush()方法。
break;
// .....
preCommit在TwoPhaseCommitSinkFunction#snapshotState()中调用
public void snapshotState(FunctionSnapshotContext context) throws Exception
long checkpointId = context.getCheckpointId();
//预提交,如果语义为EXACTLY_ONCE,执行flush操作
preCommit(currentTransactionHolder.handle);
//pendingCommitTransactions插入当次检查点对应的currentTransactionHolder,包含事务生产者的实例(对于EXACTLY_ONCE模式)
pendingCommitTransactions.put(checkpointId, currentTransactionHolder);
//这里又初始化了一次包含事务生产者的实例(对于EXACTLY_ONCE模式),并赋给currentTransactionHolder
currentTransactionHolder = beginTransactionInternal();
//清空state
state.clear();
//
state.add(new State<>(
this.currentTransactionHolder,
new ArrayList<>(pendingCommitTransactions.values()),
userContext));
TwoPhaseCommitSinkFunction也继承了CheckpointedFunction接口,所以2PC是与检查点机制一同发挥作用的。
每当需要做checkpoint时,JobManager就在数据流中打入一个屏障(barrier),作为检查点的界限。屏障随着算子链向下游传递,每到达一个算子都会触发将状态快照写入状态后端(state BackEnd)的动作。当屏障到达Kafka sink后,触发preCommit(实际上是KafkaProducer.flush())方法刷写消息数据,但还未真正提交。接下来还是需要通过检查点来触发提交阶段。
2.1.1、插入检查点
flink的jobmanager会在数据流中插入一个检查点的标记(这个标记可以用来区别这次checkpoint的数据和下次checkpoint的数据)。
这个标记会在整个dag中传递。每个dag中的算子遇到这个标记就会触发这个算子状态的快照。(图2)

2.1.2、触发将状态快照写入状态后端
读取kafka的算子,在遇到检查点标记时会存储kafka的offset。之后,会把这个检查点标记传到下一个算子。
接下来就到了flink的内存操作算子。这些内部算子就不用考虑两步提交协议了,因为他们的状态会随着flink整体的状态来更新或者回滚。
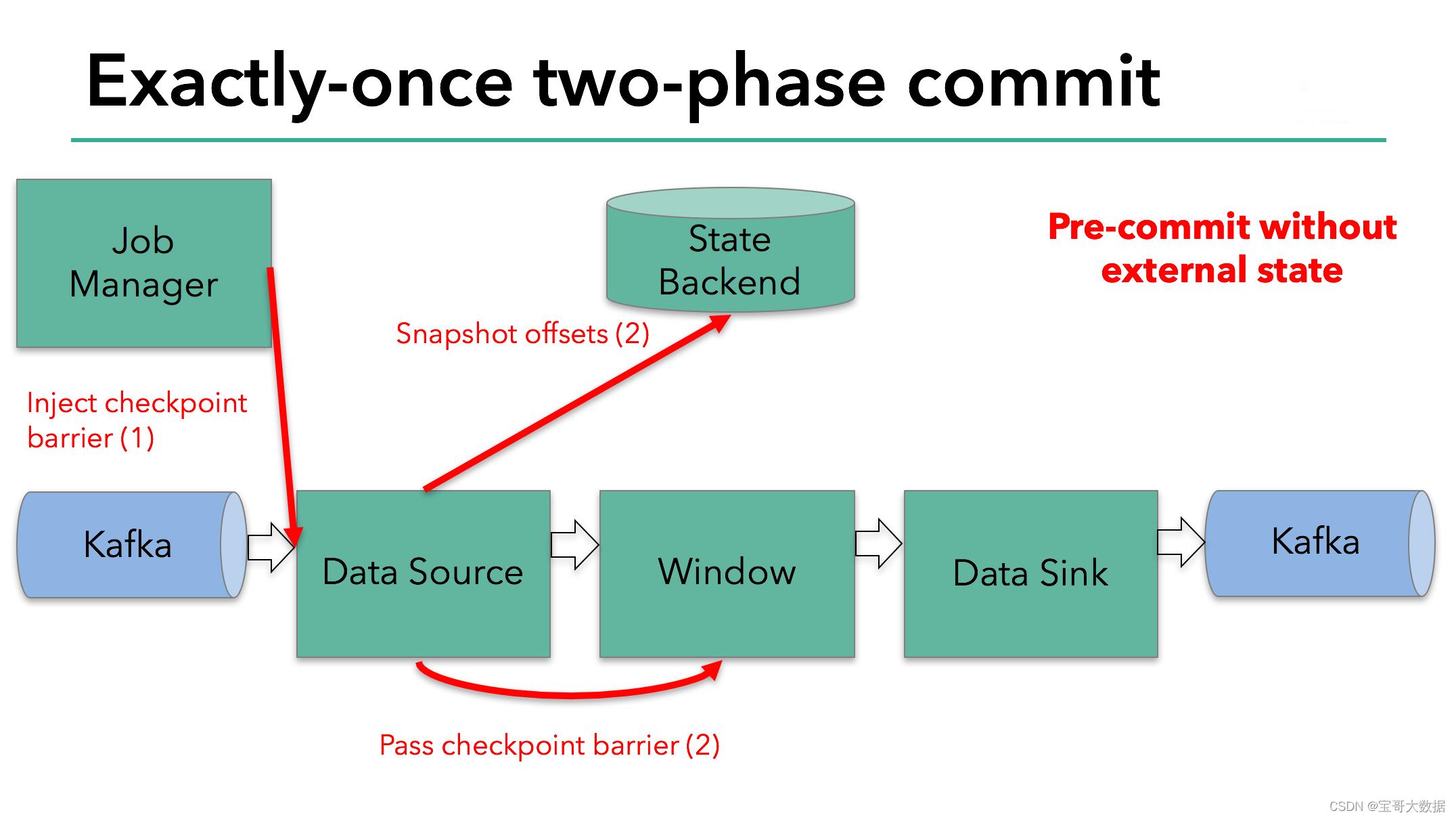
2.1.3、和外部系统,两步提交协议来保证数据不丢失不重复
到了和外部系统打交道的时候,就需要两步提交协议来保证数据不丢失不重复了。在预提交这个步骤下,所有向kafka提交的数据都是预提交。

一旦开启了checkpoint功能,JobManager就在数据流中源源不断地打入屏障(barrier),作为检查点的界限。屏障随着算子链向下游传递,每到达一个算子都会触发将状态快照写入状态后端的动作。当屏障到达Kafka sink后,通过KafkaProducer.flush()方法刷写消息数据,但还未真正提交。
接下来还是需要通过检查点来触发提交阶段
2.2、提交阶段
@Override
protected void commit(FlinkKafkaProducer.KafkaTransactionState transaction)
if (transaction.isTransactional())
try
// 实际上是代理了KafkaProducer.commitTransaction()方法,正式向Kafka提交事务。
transaction.producer.commitTransaction();
finally
recycleTransactionalProducer(transaction.producer);
该方法的调用点位于TwoPhaseCommitSinkFunction.notifyCheckpointComplete()方法中。顾名思义,当所有检查点都成功完成之后,会回调这个方法。
该方法每次从正在等待提交的事务句柄中取出一个,校验它的检查点ID,并调用commit()方法提交之。
public final void notifyCheckpointComplete(long checkpointId) throws Exception
// 可能出现以下几种情况
// (1) 从最近的检查点触发并完成的事务恰好只有一个。 这应该很常见,在这种情况下只需提交该事务即可。
// (2) 由于上一次checkpoint被跳过导致这里有多个正在进行的事务,这是一种罕见的情况,但可能在以下情况下发生:
// - 上一次checkpoint未能持久化metadata(存储系统临时中断)但可以保留一个连续的检查点(此处通知的检查点)
// - 其他task未能在上一次checkpoint持久化他们的状态,但未触发失败,因为他们可以保持其状态并将其成功保存在连续的检查点中(此处通知的检查点)
// 在这两种情况下,前一个检查点都不会达到提交状态,但此检查点总是希望包含前一个检查点,并覆盖自上一个成功检查点以来的所有更改。因此,我们需要提交所有待提交的事务。
// (3) 多个事务处于待提交状态,但检查点完成通知与最新的不相关。这是可能的,因为通知消息可能会延迟(在极端情况下,直到触发下一个检查点之后到达)并且可能会有并发的重叠检查点(新的检查点在上一个完全完成之前启动)。
// ==> 永远不会有我们这里没有待提交事务的情况
//待提交的事务版本和事务句柄
Iterator<Map.Entry<Long, TransactionHolder<TXN>>> pendingTransactionIterator = pendingCommitTransactions.entrySet().iterator();
Throwable firstError = null;
while (pendingTransactionIterator.hasNext())
Map.Entry<Long, TransactionHolder<TXN>> entry = pendingTransactionIterator.next();
Long pendingTransactionCheckpointId = entry.getKey();
TransactionHolder<TXN> pendingTransaction = entry.getValue();
if (pendingTransactionCheckpointId > checkpointId)
continue;
try
//提交事务(最终调用commitTransaction)
commit(pendingTransaction.handle);
catch (Throwable t) //...
pendingTransactionIterator.remove();
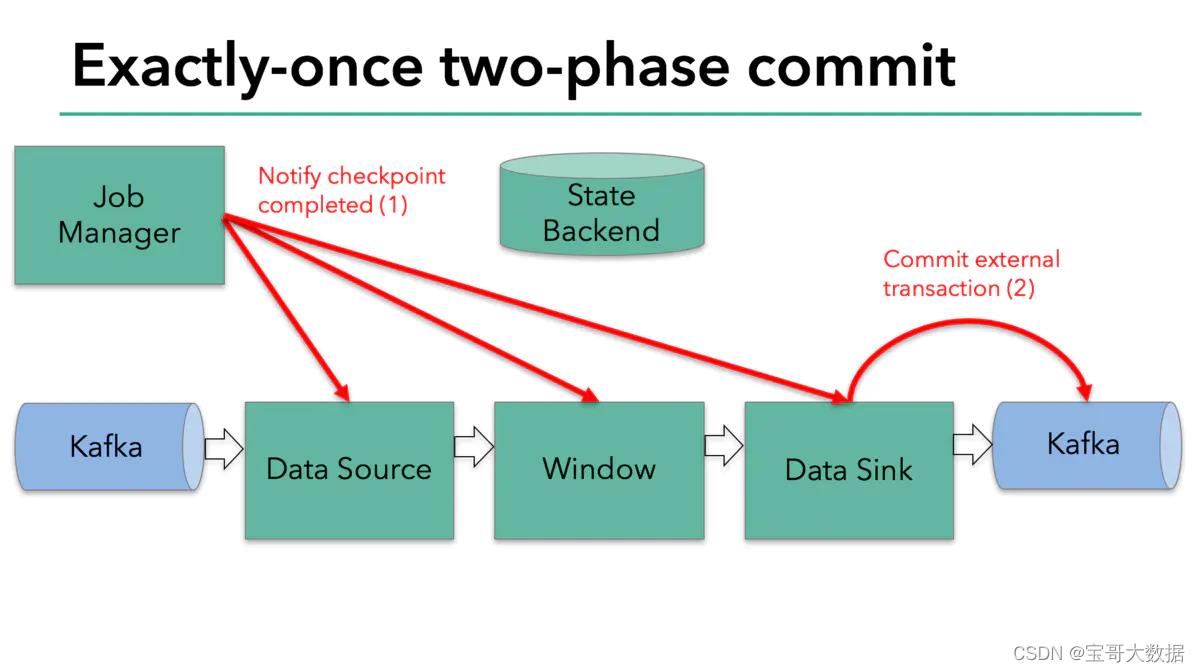
2.3、回滚
只有在所有检查点都成功完成这个前提下,写入才会成功。这符合2PC的流程,其中JobManager为协调者,各个算子为参与者(不过只有sink一个参与者会执行提交)。一旦有检查点失败,notifyCheckpointComplete()方法就不会执行。
如果重试也不成功的话,最终会调用abort()方法回滚事务。
2.4、总结一下flink的两步提交
当所有算子都完成他们的快照时,进行正式提交操作
当任意子任务在预提交阶段失败时,其他任务立即停止,并回滚到上一次成功快照的状态。
在预提交状态成功后,外部系统需要完美支持正式提交之前的操作。如果有提交失败发生,整个flink应用会进入失败状态并重启,重启后将会继续从上次状态来尝试进行提交操作。
参考
https://www.aboutyun.com/forum.php?mod=viewthread&tid=27395
https://dandelioncloud.cn/article/details/1441622512370266113
https://flink.apache.org/features/2018/03/01/end-to-end-exactly-once-apache-flink.html
以上是关于Flink保证exactly-once机制介绍:checkpoint及TwoPhaseCommitSinkFunction的主要内容,如果未能解决你的问题,请参考以下文章