Flink——Exactly-Once
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink——Exactly-Once相关的知识,希望对你有一定的参考价值。
参考技术AApache Flink是目前市场最受关注的流计算处理引擎,相较于Spark Streaming的依托Spark Core实现的微批处理模型,Flink是一个纯粹的流处理引擎,其基于操作符的连续流模型,可以达到微秒级别的延迟。
Flink实现了流批一体化模式,实现按照事件处理和无序处理两种形式,基于内存计算。强大高效的反压机制和内存管理,基于轻量级分布式快照checkpoint机制,从而自动实现了Exactly-Once一致性语义。
1. 数据源端
支持可靠的数据源(如kafka), 数据可重读
Apache Flink内置FlinkKafkaConsumer010类,不依赖于 kafka 内置的消费组offset管理,在内部自行记录和维护 consumer 的offset。
2. Flink消费端
轻量级快照机制: 一致性checkpoint检查点
Flink采用了一种轻量级快照机制(检查点checkpoint)来保障Exactly-Once的一致性语义。所谓的一致检查点,即在某个时间点上所有任务状态的一份拷贝(快照)。该时间点是所有任务刚好处理完一个相同数据的时间。
间隔时间自动执行分布式一致性检查点(Checkpoints)程序,异步插入barrier检查点分界线,内存状态自动存储为cp进程文件。保证数据Exactly Oncey精确一次处理。
(1) 从source(Input)端开始,JobManager会向每个source(Input)发送检查点barrier消息,启动检查点。在保证所有的source(Input)数据都处理完成后,Flink开始保存具体的一致性检查点checkpoints,并在过程中启用barrier检查点分界线。
(2) 接收数据和barrier消息,两个过程异步进行。在所有的source(Input)数据都处理完成后,开始将自己的检查点(checkpoints)保存到状态后(StateBackend)中,并通知JobManager将Barrier分发到下游
(3) barrier向下游传递时,会进行barrier对齐确认。待barrier都到齐后才进行checkpoints检查点保存。
(4) 重复以上操作,直到整个流程完成。
3. 输出端
与上文Spark的输出端Exactly-Once一致性上实现类似,除了目标源需要满足一定条件以外,Flink内置的二阶段提交机制也变相实现了事务一致性。**支持幂等写入、事务写入机制(二阶段提交) **
这一块和上文Spark的幂写入特性内容一致,即相同Key/ID 更新写入,数据不变。借助支持主键唯一性约束的存储系统,实现幂等性写入数据,此处将不再继续赘述。
Flink在处理完source端数据接收和operator算子计算过程,待过程中所有的checkpoint都完成后,准备发送数据到sink端,此时启动事务。其中存在两种方式: (1) WAL预写日志: 将计算结果先写入到日志缓存(状态后端/WAL)中,等checkpoint确认完成后一次性写入到sink。(2) 二阶段提交: 对于每个checkpoint创建事务,先预提交数据到sink中,然后等所有的checkpoint全部完成后再真正提交请求到sink, 并把状态改为已确认。
整体思想: 为checkpoint创建事务,等到所有的checkpoint全部真正的完成后,才把计算结果写入到sink中。
21.Flink-高级特性-新特性-Exactly-Once数据一致性语义分类如何实现局部的Exactly-Once分布式快照/Checkpoint
21.Flink-高级特性-新特性-End-to-End Exactly-Once
21.1.数据一致性语义分类
21.2.数据一致性语义详解
21.2.1.At-most-once-最多一次
21.2.2.At-least-once-至少一次
21.2.3.Exactly-once-精确一次
21.2.4.End-To-End Exactly-Once
21.2.5.如何实现局部的Exactly-Once
21.2.5.1.去重
21.2.5.2.幂等
21.2.5.3.分布式快照/Checkpoint — Flink使用的是这个
21.2.5.4.总结
21.2.6.如何实现End-To-End Exactly-Once
21.2.6.1.两阶段提交
21.2.7.代码演示
21.Flink-高级特性-新特性-End-to-End Exactly-Once
21.1.数据一致性语义分类
流处理引擎通常为应用程序提供了三种数据处理语义:
At most once最多一次 有可能丢失。
At least once至少一次 有可能重复处理。
Exactly once精确一次 恰好只被正确处理一次。
End-To-End Exactly Once端到端的精准一次,指的是从Source-Transformation-Sink都可以保证Exactly Once
如下是对这些不同处理语义的宽松定义(一致性由弱到强):
At most once < At least once < Exactly once < End to End Exactly once
Flink能够做到End-To-End Exactly Once.
21.2.数据一致性语义详解
21.2.1.At-most-once-最多一次
有可能会有数据丢失
这本质上是简单的恢复方式,也就是直接从失败处的下个数据开始恢复程序,之前的失败数据处理就不管了。可以保证数据或事件最多由应用程序中的所有算子处理一次。这意味着如果数据在被流应用程序完全处理之前发生丢失,则不会进行其它重试或者重新发送。

21.2.2.At-least-once-至少一次
应用程序中的所有算子都保证数据或事件至少被处理一次。这通常意味着如果事件在流应用程序完全处理之前丢失,则将从源头重放或重新传输事件。然而,由于事件是可以被重传的,因此一个事件有时会被处理多次(至少一次),至于有没有重复数据,不会关心,所以这种场景需要人工干预自己处理重复数据。
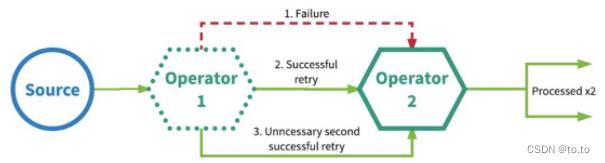
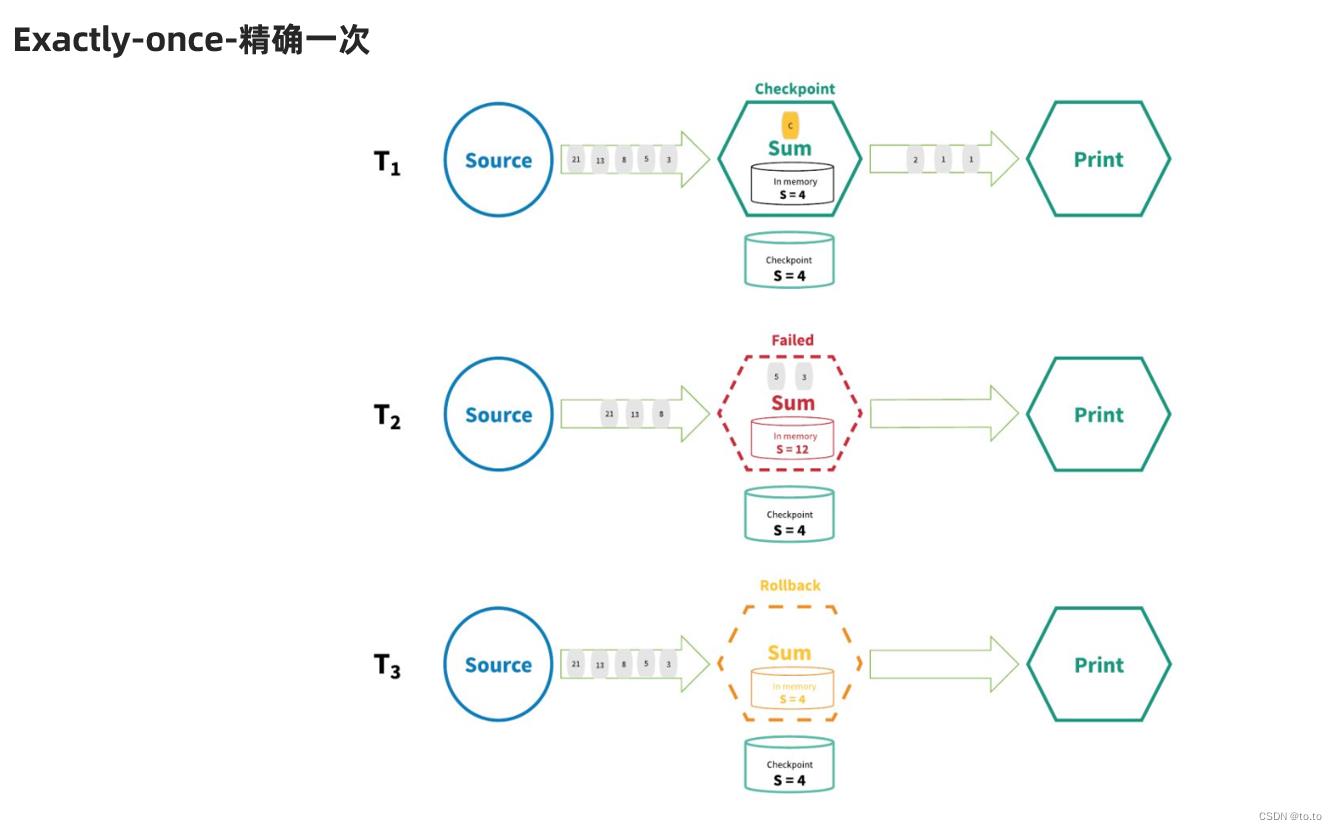
21.2.3.Exactly-once-精确一次
注意:
Exactly-Once 更准确的理解 应该是:
数据只会被正确的处理一次!
而不是说数据只被处理一次,有可能多次,但只有最后一次是正确的,成功的!
21.2.4.End-To-End Exactly-Once
表示从Source到Transformation到Sink都能保证Exactly-Once!

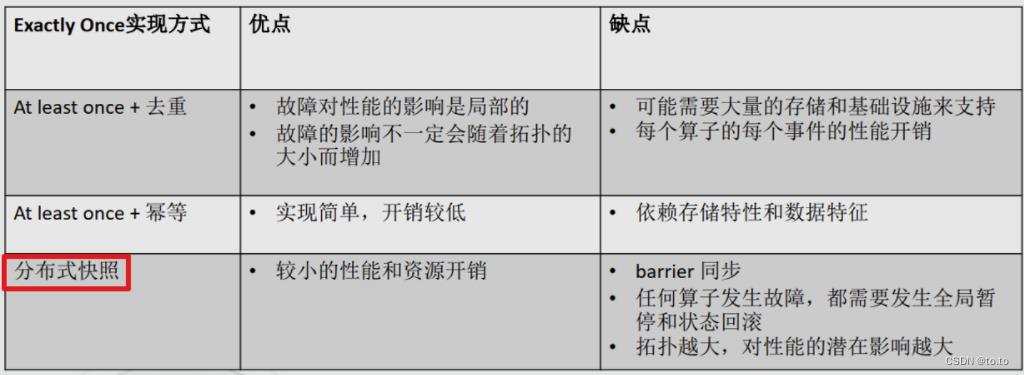
21.2.5.如何实现局部的Exactly-Once
可以使用:
21.2.5.1.去重
At least once + 去重
每个算子维护一个事务日志,跟踪已处理的事件
重放失败事件,在事件进入下各算子之前,移除重复事件
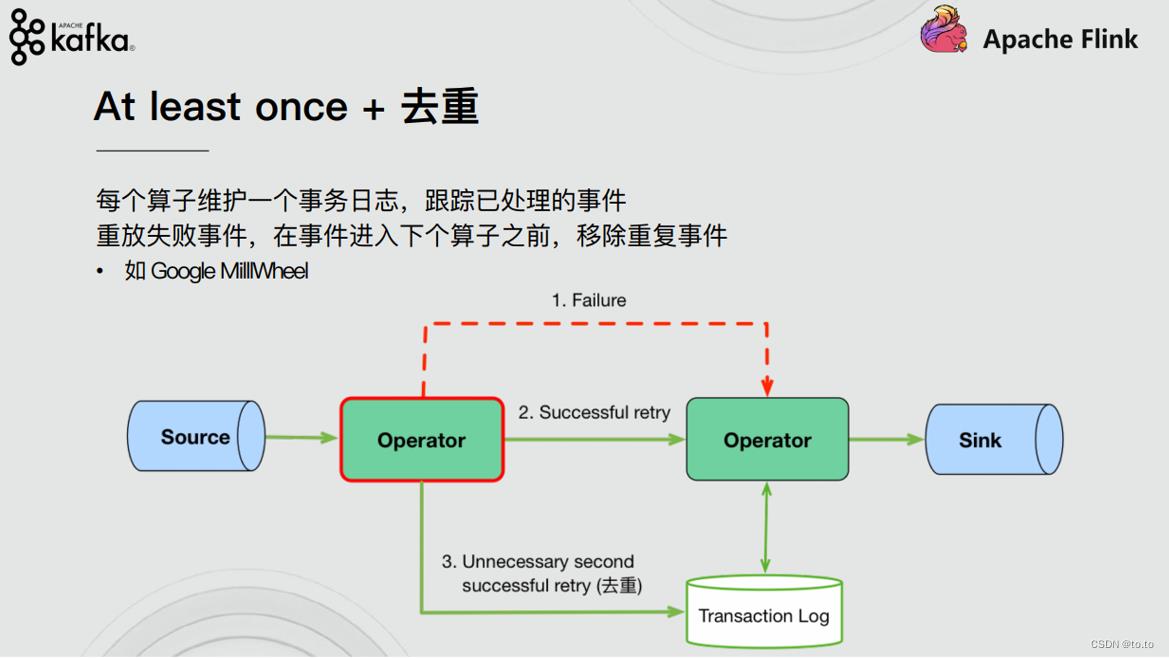
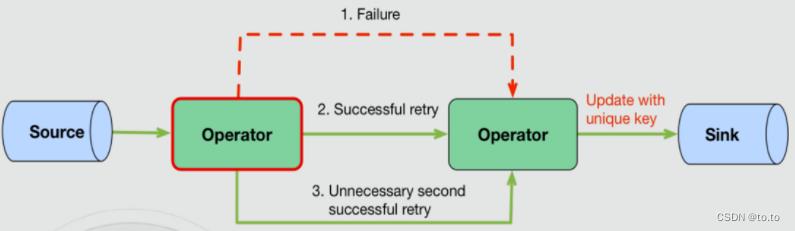
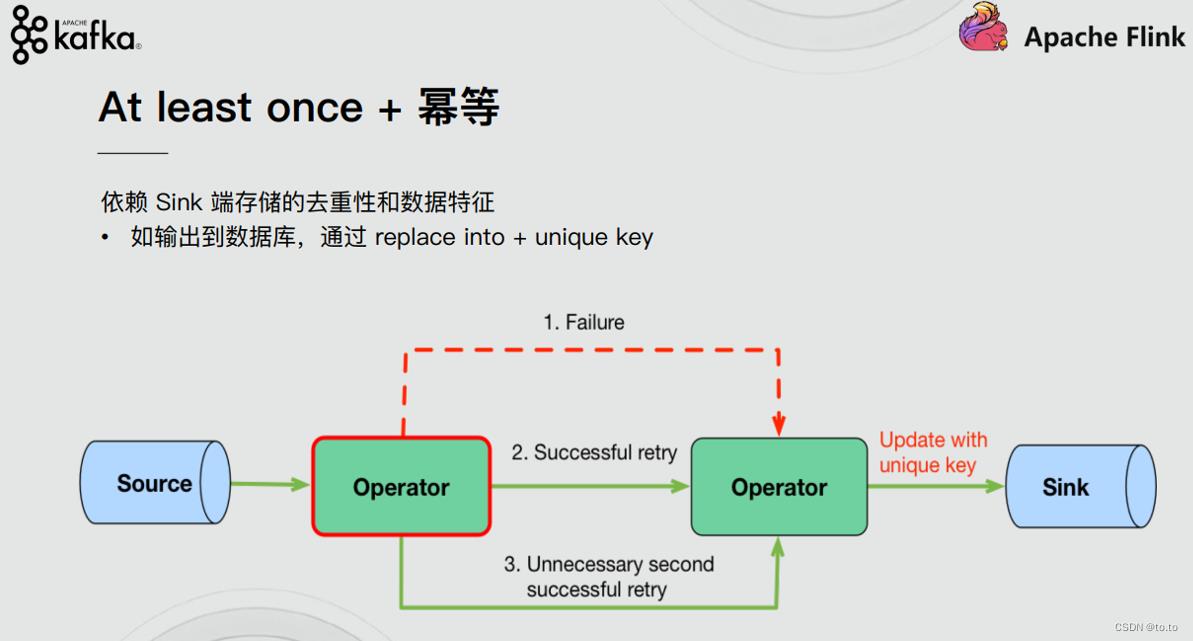
21.2.5.2.幂等
At least once + 幂等
依赖Sink端存储的去重性和数据特征
- 如输出到数据库,通过replace into + unique key
21.2.5.3.分布式快照/Checkpoint — Flink使用的是这个
Chandy-Lamport分布式快照算法
- 引入barrier,把input stream分为preshot records和postshot records。
- Operator收到所有上游barrier的时候做一个snapshot,继续往下处理。
- 当所有Sink Operator都完成了Snapshot,这一轮Snapshot就完成了。
21.2.5.4.总结
21.2.6.如何实现End-To-End Exactly-Once

Source: 如Kafka的offset 支持数据的replay/重放/重新传输
Transformation: 借助于Checkpoint
Sink: Checkpoint + 两阶段事务提交
21.2.6.1.两阶段提交
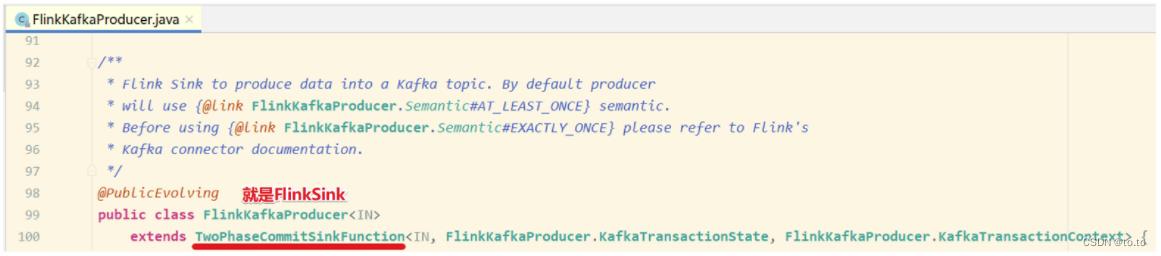
两阶段提交-API
在Flink中的Two-Phase-Commit-2PC两阶段提交的实现方法被封装到了TwoPhaseCommitSinkFunction这个抽象类中,只需要实现其中的beginTransaction、preCommit、commit、abort四个方法就可以实现”精确一次”的处理语义。
如FlinkKafkaProducer就实现了该类并实现了这些方法。

1.beginTransaction,在开启事务之前,我们在目标文件系统的临时目录中创建一个临时文件,后面在处理数据时将数据写入此文件。
2.preCommit,在预提交阶段,刷写(flush)文件,然后关闭文件,之后就不能写入到文件了,我们还将为属于下一个检查点的任何后续写入启动新事务
3.commit,在提交阶段,我们将预提交的文件原子性移动到真正的目标目录中,请注意,这会增加输出数据可见性的延迟;
4.abort,在中止阶段,我们删除临时文件。
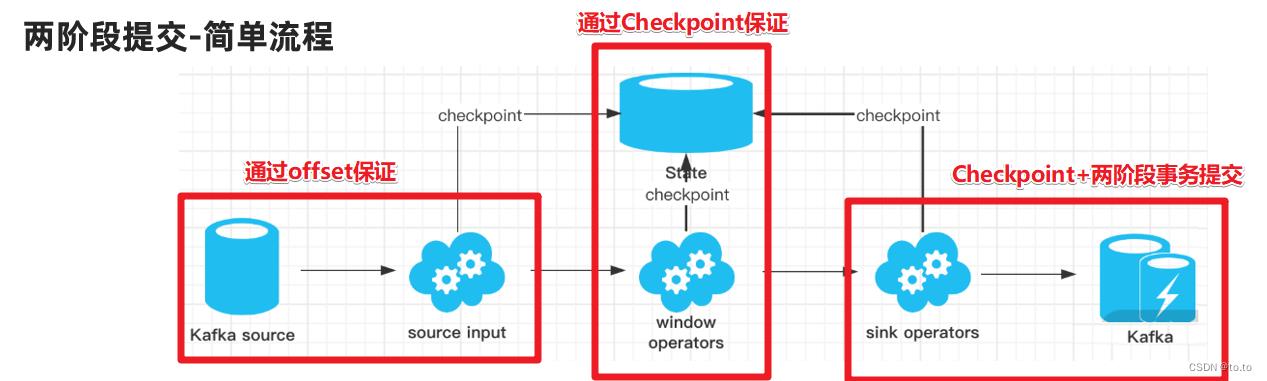
1.SourceOperator从Kafka消费消息/数据并记录offset
2.TransformationOperator对数据进行处理转换并做Checkpoint
3.SinkOperator将结果写入到Kafka
注意:在sink的时候会执行两阶段提交:
1.开启事务
2.各个Operator执行barrier的Checkpoint,成功则进行预测提交。
3.所有Operator执行完预提交则执行真正的提交。
4.如果有任何一个预提交失败则回滚到最近的Checkpoint。
21.2.7.代码演示
Flink Source -->
Flink-Transformation做WordCount–>
结果存储到kafka主题-flink-kafka2
//1.创建主题
/export/server/kafka/bin/kafka-topics.sh --zookeeper node1:2181 --create --replication-factor 2 --partitions 3 --topic flink_kafka1
/export/server/kafka/bin/kafka-topics.sh --zookeeper node1:2181 --create --replication-factor 2 --partitions 3 --topic flink_kafka2
//2.开启控制台生产者
/export/server/kafka/bin/kafka-console-producer.sh --broker-list node1:9092 --topic flink_kafka1
//3.开启控制台消费者
/export/server/kafka/bin/kafka-console-consumer.sh --bootstrap-server node1:9092 --topic flink_kafka2
import org.apache.commons.lang.SystemUtils;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.streaming.connectors.kafka.internals.KeyedSerializationSchemaWrapper;
import org.apache.flink.util.Collector;
import java.util.Properties;
import java.util.Random;
import java.util.concurrent.TimeUnit;
/**
* Desc 演示Flink的EndToEnd_Exactly_Once
* 需求:
* kafka主题flink-kafka1 --->Flink Source -->Flink-Transformation做WordCount-->结果存储到kafka主题-flink-kafka2
*
* @author tuzuoquan
* @date 2022/6/20 19:27
*/
public class Flink_Kafka_EndToEnd_Exactly_Once
public static void main(String[] args) throws Exception
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//开启Checkpoint
//===========类型1:必须参数=============
//设置Checkpoint的时间间隔为1000ms做一次Checkpoint/其实就是每隔1000ms发一次Barrier!
env.enableCheckpointing(1000);
if (SystemUtils.IS_OS_WINDOWS)
env.setStateBackend(new FsStateBackend("file:///D:/ckp"));
else
env.setStateBackend(new FsStateBackend("hdfs://node1:8020/flink-checkpoint/checkpoint"));
//===========类型2:建议参数===========
//设置两个Checkpoint 之间最少等待时间,如设置Checkpoint之间最少是要等 500ms(为了避免每隔1000ms做一次Checkpoint的时候,前一次太慢和后一次重叠到一起去了)
//如:高速公路上,每隔1s关口放行一辆车,但是规定了两车之前的最小车距为500m
//默认是0
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
//设置如果在做Checkpoint过程中出现错误,是否让整体任务失败:true是 false不是
//env.getCheckpointConfig().setFailOnCheckpointingErrors(false);//默认是true
//默认值为0,表示不容忍任何检查点失败
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(10);
//设置是否清理检查点,表示Cancel时是否需要保留当前的Checkpoint,默认Checkpoint会在作业被Cancel时被删除
//ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION:true,当作业被取消时,删除外部的checkpoint(默认值)
//ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:false,当作业被取消时,保留外部的checkpoint
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//===========类型3:直接使用默认的即可===============
//设置checkpoint的执行模式为EXACTLY_ONCE(默认)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//设置checkpoint的超时时间,如果 Checkpoint在 60s内尚未完成说明该次Checkpoint失败,则丢弃。
//默认10分钟
env.getCheckpointConfig().setCheckpointTimeout(60000);
//设置同一时间有多少个checkpoint可以同时执行
//默认为1
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
//TODO ===配置重启策略:
//1.配置了Checkpoint的情况下不做任务配置:默认是无限重启并自动恢复,可以解决小问题,但是可能会隐藏真正的bug
//2.单独配置无重启策略
//env.setRestartStrategy(RestartStrategies.noRestart());
//3.固定延迟重启--开发中常用
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // 最多重启3次数
Time.of(5, TimeUnit.SECONDS) // 重启时间间隔
));
//上面的设置表示:如果job失败,重启3次, 每次间隔5s
//4.失败率重启--开发中偶尔使用
/*env.setRestartStrategy(RestartStrategies.failureRateRestart(
3, // 每个测量阶段内最大失败次数
Time.of(1, TimeUnit.MINUTES), //失败率测量的时间间隔
Time.of(3, TimeUnit.SECONDS) // 两次连续重启的时间间隔
));*/
//上面的设置表示:如果1分钟内job失败不超过三次,自动重启,每次重启间隔3s (如果1分钟内程序失败达到3次,则程序退出)
//TODO 1.source-主题:flink-kafka1
//准备kafka连接参数
Properties props1 = new Properties();
//集群地址
props1.setProperty("bootstrap.servers", "node1:9092");
//消费者组id
props1.setProperty("group.id", "flink");
//latest有offset记录从记录位置开始消费,没有记录从最新的/最后的消息开始消费
//earliest有offset记录从记录位置开始消费,没有记录从最早的/最开始的消息开始消费
props1.setProperty("auto.offset.reset", "latest");
//会开启一个后台线程每隔5s检测一下Kafka的分区情况,实现动态分区检测
props1.setProperty("flink.partition-discovery.interval-millis", "5000");
//自动提交(提交到默认主题,后续学习了Checkpoint后随着Checkpoint存储在Checkpoint和默认主题中)
//props1.setProperty("enable.auto.commit", "true");
//props1.setProperty("auto.commit.interval.ms", "2000");//自动提交的时间间隔
//使用连接参数创建FlinkKafkaConsumer/kafkaSource
//FlinkKafkaConsumer里面已经实现了offset的Checkpoint维护!
FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<String>("flink_kafka1", new SimpleStringSchema(), props1);
// 默认就是true
// 在做Checkpoint的时候提交offset到Checkpoint(为容错)和默认主题(为了外部工具获取)中
kafkaSource.setCommitOffsetsOnCheckpoints(true);
// 使用kafkaSource
DataStream<String> kafkaDS = env.addSource(kafkaSource);
//TODO 2.transformation-做WordCount
SingleOutputStreamOperator<String> result = kafkaDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>()
private Random ran = new Random();
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception
String[] arr = value.split(" ");
for (String word : arr)
int num = ran.nextInt(5);
if(num > 3)
System.out.println("随机异常产生了");
throw new Exception("随机异常产生了");
out.collect(Tuple2.of(word, 1));
).keyBy(t -> t.f0)
.sum(1)
.map(new MapFunction<Tuple2<String, Integer>, String>()
@Override
public String map(Tuple2<String, Integer> value) throws Exception
return value.f0 + ":" + value.f1;
);
//TODO 3.sink-主题:flink-kafka2
Properties props2 = new Properties();
props2.setProperty("bootstrap.servers", "node1:9092");
props2.setProperty("transaction.timeout.ms", "5000");
FlinkKafkaProducer<String> kafkaSink = new FlinkKafkaProducer<>(
"flink_kafka2", // target topic
new KeyedSerializationSchemaWrapper(new SimpleStringSchema()),// serialization schema
props2,// producer config
FlinkKafkaProducer.Semantic.EXACTLY_ONCE); // fault-tolerance
result.addSink(kafkaSink);
//TODO 4.execute
env.execute();
以上是关于Flink——Exactly-Once的主要内容,如果未能解决你的问题,请参考以下文章