机器学习11—原型聚类之学习向量量化(LVQ)
Posted 存在~~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习11—原型聚类之学习向量量化(LVQ)相关的知识,希望对你有一定的参考价值。
学习向量量化(LVQ)
前言
周志华的《机器学习》介绍学习向量量化(LVQ)中可以知道,LVQ也是基于原型的聚类算法,与K-Means不同的是,LVQ使用样本真实类标记辅助聚类,首先LVQ根据样本的类标记,从各类中分别随机选出一个样本作为该类簇的原型,从而组成了一个原型特征向量组,接着从样本集中随机挑选一个样本,计算其与原型向量组中每个向量的距离,并选取距离最小的原型向量所在的类簇作为它的划分结果,再与真实类标比较。
LVQ算法的流程如下所示:

大致过程就是:
- 统计样本的类别,假设一共有q类,初始化为原型向量的标记为t1,t2,……,tq。从样本中随机选取q个样本点位原型向量p1, p2 ,……, pq。初始化一个学习率a,a 取值范围(0,1)。
- 从样本集中随机选取一个样本(x, y),计算该样本与q个原型向量的距离(欧几里得距离),找到与样本距离最小的那个原型向量p,判断样本的标记y与原型向量的标记t是不是一致。若一致则更新为p’ = p + a*(x-p),否则更新为p’ = p - a*(x - p)。
- 重复第2步直到满足停止条件。(如达到最大迭代次数)
- 返回q个原型向量。
一、学习向量量化(LVQ)简单实现二分类
- 数据的生成
这里用比较小的样本数据data,共有13个样本,每个样本采集的特征为:密度,含糖率,是否好瓜。其中是否好瓜的标签为:Y和N。
import re
import math
import numpy as np
import pylab as pl #pylab模块多用折线图和曲线图上
# import matplotlib.pyplot as plt
data = \\
"""1,0.697,0.46,Y,
2,0.774,0.376,Y,
3,0.634,0.264,Y,
4,0.608,0.318,Y,
5,0.556,0.215,Y,
6,0.403,0.237,Y,
7,0.481,0.149,Y,
8,0.437,0.211,Y,
9,0.666,0.091,N,
10,0.639,0.161,N,
11,0.657,0.198,N,
12,0.593,0.042,N,
13,0.719,0.103,N"""
# data
- 数据的预处理
# 数据简单处理
a = re.split(',', data.strip(" "))# 数据划分
dataset = [] # dataset:数据集
for i in range(int(len(a)/4)):
temp = tuple(a[i * 4: i * 4 + 4])
dataset.append(watermelon(temp))
- 计算距离
# 计算欧几里得距离,a,b分别为两个元组
def dist(a, b):
return math.sqrt(math.pow(a[0]-b[0], 2)+math.pow(a[1]-b[1], 2))
- 算法模型的建立
# 算法模型
def LVQ(dataset, a, max_iter):
# 统计样本一共有多少个分类
T = list(set(i.good for i in dataset))
print('样本分类总数', T)
# 随机产生原型向量
P = [(i.density, i.sweet,i.good) for i in np.random.choice(dataset, 2)]
print('原型向量', P)
while max_iter>0:
# 从样本集dataset中随机选取一个样本X
X = np.random.choice(dataset, 1)[0]
#print(i for i in P)
#index = np.argmin(dist((X.density, X.sweet), (i[0], i[1])) for i in P)
# 找出P中与X距离最近的原型向量P[index]
m = []
for i in range(len(P)):
m.append(dist((X.density, X.sweet),(P[i][0],P[i][1])))
index = np.argmin(m)
#print('m为',m)
#print ('index为',index)
# 获得原型向量的标签t,并判断t是否与随机样本的标签相等
t = P[index][2]
#print('t为',t)
if t == X.good:
P[index] = ((1 - a) * P[index][0] + a * X.density, (1 - a) * P[index][1] + a * X.sweet,t )
else:
P[index] = ((1 + a) * P[index][0] - a * X.density, (1 + a) * P[index][1] - a * X.sweet,t )
max_iter -= 1
return P

- pl画图
# 画图
def draw(C, P):
colValue = ['r', 'y', 'g', 'b', 'c', 'k', 'm']
for i in range(len(C)):
coo_X = [] # x坐标列表
coo_Y = [] # y坐标列表
for j in range(len(C[i])):
coo_X.append(C[i][j].density)
coo_Y.append(C[i][j].sweet)
pl.scatter(coo_X, coo_Y, marker='x', color=colValue[i%len(colValue)], label=i)
# 展示原型向量
P_x = []
P_y = []
for i in range(len(P)):
P_x.append(P[i][0])
P_y.append(P[i][1])
pl.scatter(P[i][0], P[i][1], marker='o', color=colValue[i%len(colValue)], label="vector")
pl.legend(loc='upper right')
pl.show()
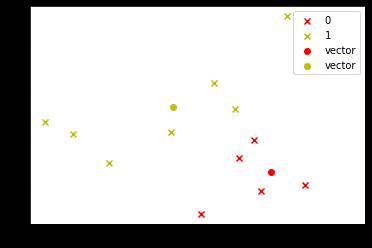
- 学习向量量化(LVQ)输出原型向量
def train_show(dataset, P):
C = [[] for i in P]
for i in dataset:
C[i.good == 'Y'].append(i)
return C
P = LVQ(dataset, 0.1, 2000)
C = train_show(dataset, P)
draw(C, P)
print('P为',P)
# print('C为',C)
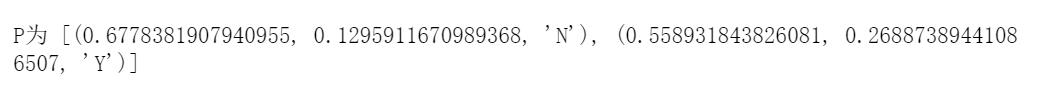
- LVQ(dataset, a, max_iter)中:dataset是样本集、a是样本和原型向量的距离、max_iter最大迭代次数。
二、、学习向量量化(LVQ)实现三分类
- 数据集生成
from sklearn import datasets
import matplotlib.pyplot as plt
import numpy as np
X=datasets.make_blobs(n_samples=1000,centers=3) #1000个样本点分为3类
# X
- 初始化原型向量
P=np.zeros((q,col)) #原型向量
for i in range(q): #初始化原型向量
index=np.where(sample[1]==Label[i])[0]
choose=np.random.randint(0,len(index),1)
P[i,:]=sample[0][index[choose],:]
- 训练主体
for i in range(1000): #训练
choose=np.random.randint(0,row,1) #随机选取一个样本
dis=np.linalg.norm(sample[0][choose,:]-P,axis=1) #计算与原型向量的距离
y=dis.tolist().index(min(dis)) #获取距离最近的原型向量下标
if Label[y]==sample[1][choose]: #更新原型向量
P[y,:]=P[y,:]+eta*(sample[0][choose,:]-P[y,:])
else:
P[y,:]=P[y,:]-eta*(sample[0][choose,:]-P[y,:])
- 分类标记
IDX=[] #分类标记
for i in sample[0]: #以距离最近的标记为样本的类别
D=np.linalg.norm(i-P,axis=1)
y=D.tolist().index(min(D))
IDX.append(Label[y])
plot(IDX,sample[0],max(Label)+1,P)
return P
- 画图
def plot(a,X,k,p): #绘画板块
m=k
for j in range(m):
index=[i for i,v in enumerate(a) if v==j]
x=[]
y=[]
for k in index:
x.append(X[k][0])
y.append(X[k][1])
plt.scatter(x,y)
plt.scatter(p[:,0],p[:,1],marker='x')
plt.show()
- 完整代码
from sklearn import datasets
import matplotlib.pyplot as plt
import numpy as np
X=datasets.make_blobs(n_samples=1000,centers=3) #1000个样本点分为3类
def lvq(sample,q,Label,eta):
if q!=len(Label):
return 0
row,col=np.shape(sample[0]) #获取样本集的规格
P=np.zeros((q,col)) #原型向量
for i in range(q): #初始化原型向量
index=np.where(sample[1]==Label[i])[0]
choose=np.random.randint(0,len(index),1)
P[i,:]=sample[0][index[choose],:]
for i in range(1000): #训练
choose=np.random.randint(0,row,1) #随机选取一个样本
dis=np.linalg.norm(sample[0][choose,:]-P,axis=1) #计算与原型向量的距离
y=dis.tolist().index(min(dis)) #获取距离最近的原型向量下标
if Label[y]==sample[1][choose]: #更新原型向量
P[y,:]=P[y,:]+eta*(sample[0][choose,:]-P[y,:])
else:
P[y,:]=P[y,:]-eta*(sample[0][choose,:]-P[y,:])
IDX=[] #分类标记
for i in sample[0]: #以距离最近的标记为样本的类别
D=np.linalg.norm(i-P,axis=1)
y=D.tolist().index(min(D))
IDX.append(Label[y])
plot(IDX,sample[0],max(Label)+1,P)
return P
def plot(a,X,k,p): #绘画板块
m=k
for j in range(m):
index=[i for i,v in enumerate(a) if v==j]
x=[]
y=[]
for k in index:
x.append(X[k][0])
y.append(X[k][1])
plt.scatter(x,y)
plt.scatter(p[:,0],p[:,1],marker='x')
plt.show()
测试代码:lvq(X,5,[0,1,0,1,2],0.5)
输出为:


总结
K-Nearest Neighbors 的一个缺点是你需要保留整个训练数据集。然而学习向量量化算法(或简称 LVQ)是一种人工神经网络算法,它允许你选择要挂起的训练实例数量并准确了解这些实例的外观。
LVQ 的表示是码本向量的集合。这些是在开始时随机选择的,并适合在学习算法的多次迭代中最好地总结训练数据集 (每次运行结果都不同,从而通过多次迭代来获得自己想要的结果)。学习后,码本向量可以像 K-Nearest Neighbors 一样用于进行预测。通过计算每个码本向量与新数据实例之间的距离,找到最相似的邻居(最佳匹配码本向量)。然后返回最佳匹配单元的类值或(回归情况下的实际值)作为预测。如果你重新调整数据以具有相同的范围,例如在 0 和 1 之间,则可以获得最佳结果。
以上是关于机器学习11—原型聚类之学习向量量化(LVQ)的主要内容,如果未能解决你的问题,请参考以下文章
java 用于映射数据集的简单学习矢量量化(LVQ)神经网络