Kubernetes 学习总结(33)—— Kubernetes 是如何重塑虚拟机的
Posted 科技D人生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kubernetes 学习总结(33)—— Kubernetes 是如何重塑虚拟机的相关的知识,希望对你有一定的参考价值。
前言
Kubernetes 大规模使用过的都说简单,没有用过清一色的都是使用复杂、概念晦涩难懂,因此即使是那些具有一定服务器端知识的人也可能会感到困惑。让我在这里尝试一些不同的东西。与其解释一个不熟悉的问题(如何在 Kubernetes 中运行 Web 服务?)和另一个(你只需要一个清单,三个 sidecar 和一堆 gobbledygook),我将尝试揭示 Kubernetes 技术发展趋势。如果您已经知道如何使用虚拟机运行服务,希望您会发现最终并没有太大区别。如果您对大规模运营服务完全不熟悉,那么跟随技术的发展可能会帮助您了解当代方法。像往常一样,这篇文章并不全面。相反,它试图总结我的个人经历以及计算机多年来虚拟化是如何形成的。
如何使用虚拟机部署服务
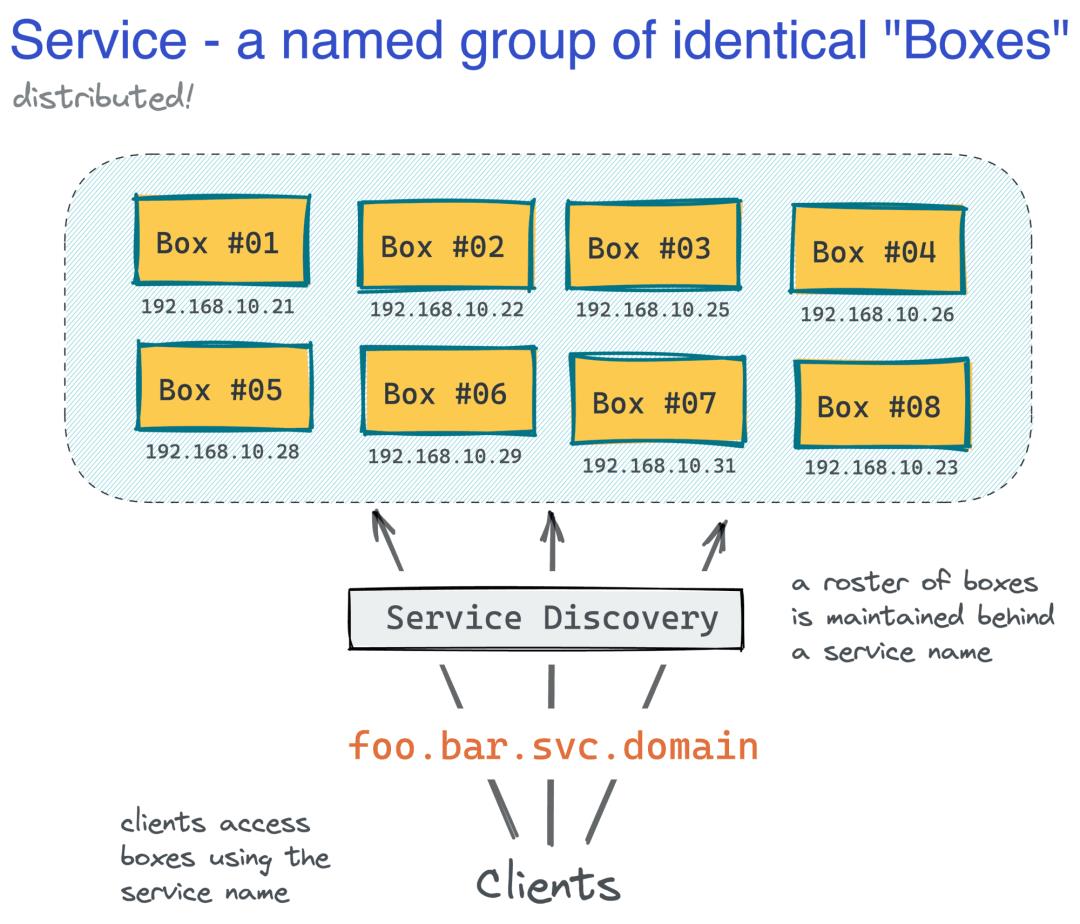
早在 2010 年,当我刚刚开始我的软件工程师职业生涯时,使用虚拟机(或有时是裸机)部署应用程序非常普遍。你需要一个临时的 Linux 虚拟机,将 nginx 或 Apache 反向代理放在它前面,然后在它旁边运行一堆守护进程和 cronjobs。这样的机器将代表服务的单个实例,打个比方,就类似于一个盒子,而服务本身将只是分布在网络上的一组命名的相同机器。根据您的业务规模,您可能只有几个、几十个、几百个甚至几千个盒子分布在为生产流量提供服务的多个盒子中。
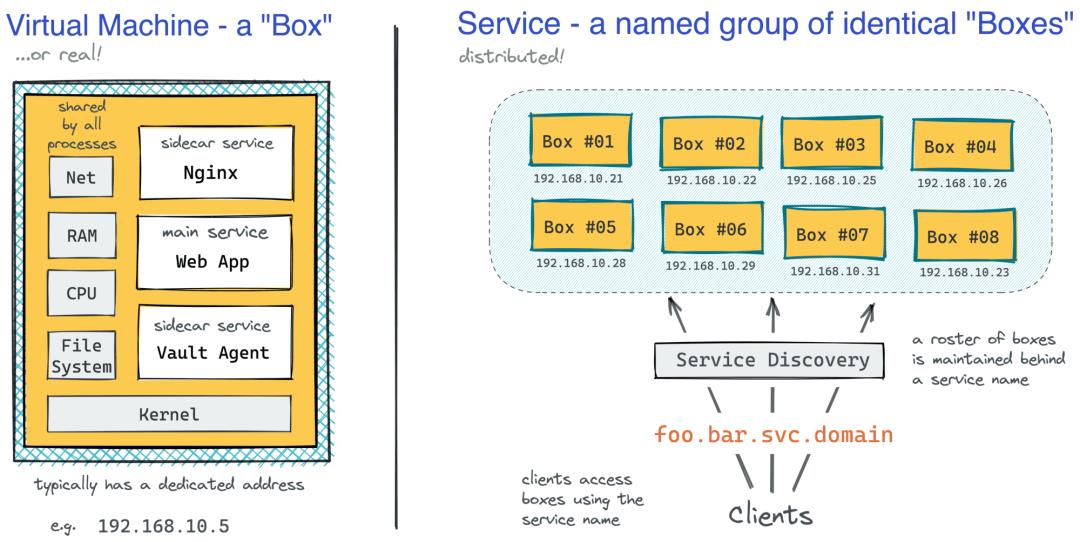
使用虚拟机部署服务带来的挑战
通常,机器群的大小将定义配置(安装操作系统和软件包)、扩展(产生相同的盒子)、服务发现(将一组盒子隐藏在一个名称后面)和部署(运送新版本的代码)的方式到盒子)完成了。如果你是一个只有几个类似宠物的盒子的公司,您可能会发现自己很少半手动地配置新盒子。这通常意味着总线系数低(由于缺乏自动化)、安全状况差(由于缺乏定期补丁更新)以及可能更长的灾难恢复。从好的方面来说,管理成本会非常低,因为不需要扩展,您的部署会很简单(只需几个盒子来交付代码),而且服务发现会很简单(由于相当静态地址池)。
对于拥有大量盒子的公司来说,现实情况会有所不同。大量机器通常会导致更频繁地需要配置新盒子(更多的盒子意味着更多的破损)。你会投资自动化(投资回报率会很高),最终得到许多牛一样的盒子。作为不断重新创建盒子的副产品,您将增加总线因素并改善安全状况(将自动更新和安装补丁)。在它的反面,会存在低效的扩展(由于每日/每年的流量分布不均匀),过于复杂的部署(很难将代码快速交付到许多机器上),以及脆弱的服务发现(您是否尝试过大规模运行consul或zookeeper?)会导致更高的运营成本。
Amazon Elastic Compute Cloud (EC2) 等早期云产品允许更快地启动(和关闭)机器;使用packer制作并使用cloud-init自定义的机器镜像,使配置稍微容易一些;puppet和ansible等自动化工具支持应用基础架构更改并大规模交付新版本的软件。但是,仍有很大的改进空间。
Docker 容器解决了什么问题
在过去,拥有不同的生产和开发环境是很常见的。这将导致应用程序可能在您安装的 Debian 机器上本地运行,但由于缺少依赖项而无法在生产中的 vanilla CentOS 上启动。相反,在本地安装应用程序的依赖项可能会遇到一些麻烦,但由于资源需求高,为每个服务运行预配置的虚拟机进行开发将是不可行的。即使在生产中,虚拟机的庞大也是一个问题。每个服务拥有一个虚拟机可能会导致低于最佳资源利用率和/或相当大的存储和计算开销,但是将多个服务放在一个盒子中可能会使它们发生资源抢占冲突。世界显然需要一个更轻量级的盒子。
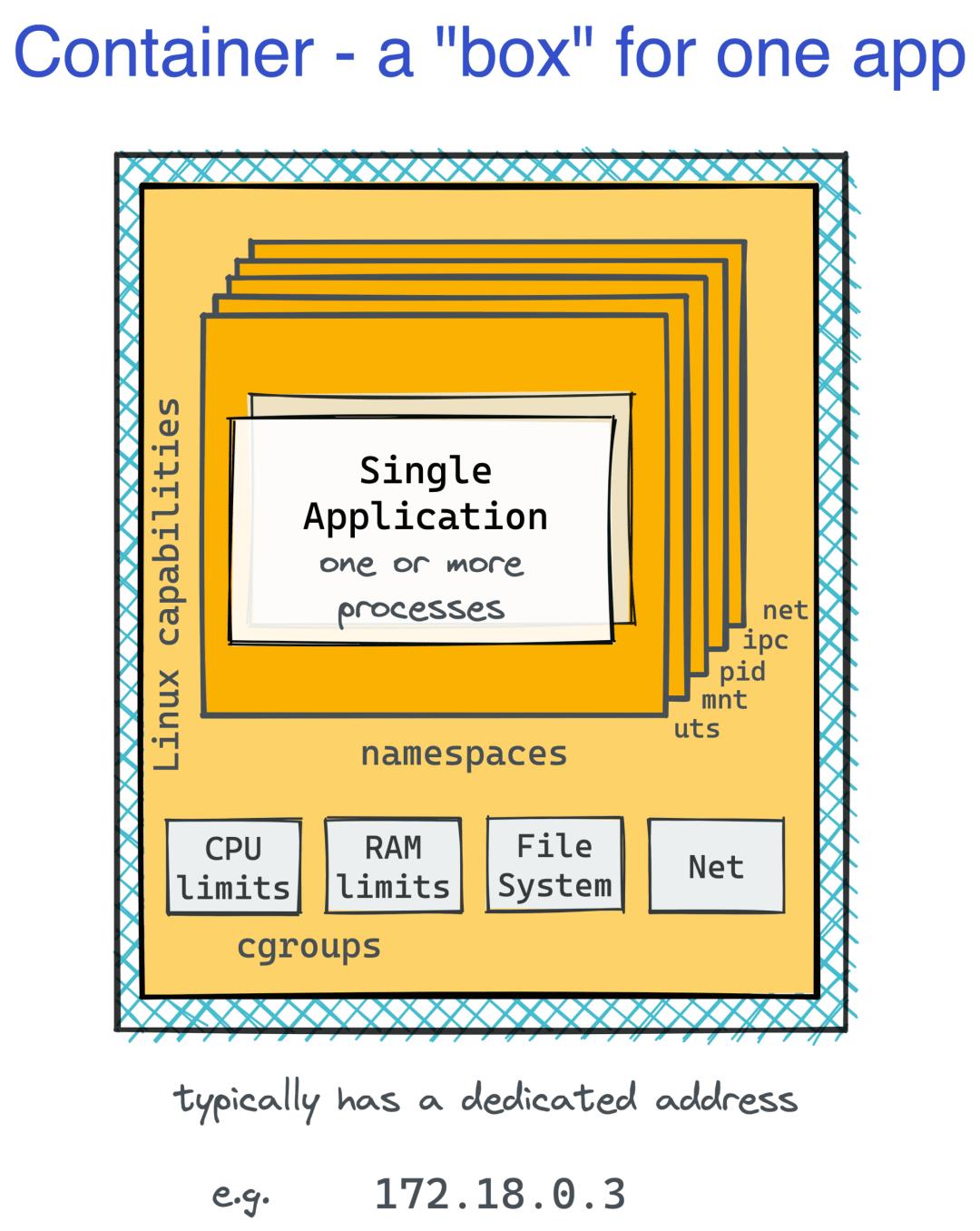
这就是容器的用武之地。就像允许将裸机服务器分割成几台更小(更便宜)的机器的虚拟机一样,容器将一个 Linux 机器分割成数十个甚至数百个独立的环境。在一个容器中,您可能会觉得您拥有自己的虚拟机,以及您最喜欢的 Linux 发行版。好吧,至少乍一看。从外部看,容器只是在主机操作系统上运行并共享其内核的常规进程。打包应用程序及其所有依赖项(包括特定版本的操作系统用户空间和库)的能力,将其作为容器镜像发送,并在安装了 Docker(或类似工具)的任何位置的标准化执行环境中运行,极大地提高了工作负载的可重复性.
由于容器边界的轻量级实现,计算开销显著降低,允许单个生产服务器运行可能属于多个(微)服务的数十个不同容器。当然,这可能以降低安全性为代价。由于不可变和共享的镜像层,镜像存储和分发也变得更加高效。在某种程度上,容器也改变了供应的方式。使用(粗心编写的)Dockerfiles 和ko和Jib之类的(神奇的)工具,责任极大地转移到了开发人员身上,简化了生产 VM 的要求——从开发人员的角度来看,你只需要一个 Docker-(或更高版本的 OCI-)兼容应用程序的运行时,因此您不会再因为要求安装某个版本的 Linux 或系统包而惹恼您的运维朋友。
最重要的是,容器加速了运行服务的替代方式的开发。现在有 17 种方法可以在 AWS 上运行容器https://www.lastweekinaws.com/blog/the-17-ways-to-run-containers-on-aws/,其中大部分是完全无服务器的,在足够简单的情况下,您可以使用 Lambda 或 Fargate 并从牛一样的盒子中受益!
容器不能解决什么问题
容器被证明是一个非常方便的开发工具。构建容器镜像也比构建 VM 更简单、更快捷。再加上如何有效分离团队之间职责的老组织问题,导致典型企业的平均服务数量显著增加,每个服务的盒子数量也有类似的增加。Docker 普及的容器形式实际上具有很强的欺骗性。乍一看,每个服务实例都有一个便宜的专用 VM。但是,如果这样的实例需要sidecar(例如在您的 Web 应用程序前面运行的本地反向代理来终止 TLS 连接或加载秘密和/或预热缓存的守护程序),您会立即感觉到疼痛,这就是容器与虚拟机的本质区别。
Docker 容器被刻意设计为只包含一个应用程序。一个容器——一个 Nginx;一个容器 - 一个 Python Web 服务器;一个容器 - 一个守护进程。容器的生命周期将绑定到该应用程序的生命周期。并且特别不鼓励将像systemd这样的 init 进程作为顶级入口点运行。因此,要从本文开头的图表重新创建一个 VM-box,您需要拥有三个具有共享网络堆栈的协调容器-box(嗯,至少localhost需要相同)。要运行该服务的两个实例,您需要三个三个一组的六个容器!
从扩展的角度来看,这意味着我们需要一起扩展(和缩减)一些容器。部署也需要同步进行。新版本的 Web 应用程序容器可能会开始使用新的端口号,并与旧版本的反向代理容器不兼容。我们显然在这里错过了一个抽象,它与容器一样轻量级,但与原始 VM 盒子一样富有表现力。此外,容器本身也没有提供任何将盒子分组为服务的方法。但他们促成了箱子人数的增加!Docker 竞相用它的 Swarm 产品解决这些问题,但另一个系统赢了……
Kubernetes 解决了这一切……还是没有?
Kubernetes 设计师显然没有发明新的运行容器的方法,而是决定重新创建良好的旧的基于 VM 的服务架构,但使用容器作为构建块。好吧,至少这是我的看法。但对我来说,作为以前有 VM 经验的人,一旦我了解了新术语并弄清楚了类似的概念,许多最初的 Kubernetes 想法就会开始看起来很熟悉。
Kubernetes Pod 是新的虚拟机
让我们从 Pod 抽象开始。Pod 是您可以在 Kubernetes 中运行的最小的东西。最简单的 Pod 定义如下所示:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:1.20.1
ports:
- containerPort: 80
乍一看,上面的清单只是说明要运行什么镜像(以及如何命名)。但是请注意containers属性是一个列表!现在,回到那个nginx + web app例子,在 Kubernetes 中,您可以简单地将反向代理和应用程序本身放在一个盒子中,而不是为 Web 应用程序容器运行额外的 Pod:
apiVersion: v1
kind: Pod
metadata:
name: foo-instance-1
spec:
containers:
- name: nginx # <-- sidecar container
image: nginx:1.20.1
ports:
- containerPort: 80
- name: app # <-- main container
image: app:0.3.2
然而,Pod 不仅仅是一组容器。Pod 中容器之间的隔离边界被削弱。就像在 VM 上运行的常规进程一样,Pod 中的容器可以通过localhost或使用传统的 IPC 方式自由通信。同时,每个容器仍然有一个独立的根文件系统,以保持打包应用程序及其依赖项的好处。对我来说,这看起来像是在尝试同时利用 VM 和容器世界的最佳部分:
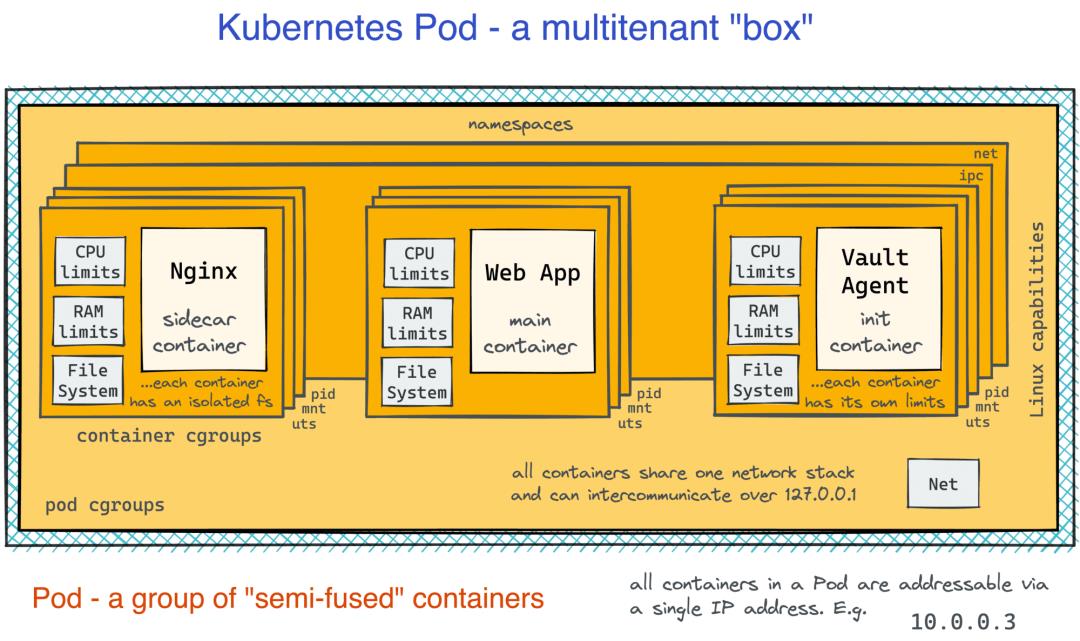
扩展和部署 Pod 很简单
现在,当我们得到新的盒子时,我们如何运行多个它们来组成一个服务?换句话说,如何在 Kubernetes 中进行扩展和部署?事实证明,它非常简单,至少在基本场景中是这样。Kubernetes 引入了一个方便的抽象,称为 Deployment。最小的 Deployment 定义由名称和 Pod 模板组成,但指定所需的 Pod 副本数量也很常见:
apiVersion: apps/v1
kind: Deployment
metadata:
name: foo-deployment-1
labels:
app: foo
spec:
replicas: 10
selector:
matchLabels:
app: foo
template:
metadata:
labels:
app: foo
spec:
<...Pod definition comes here>
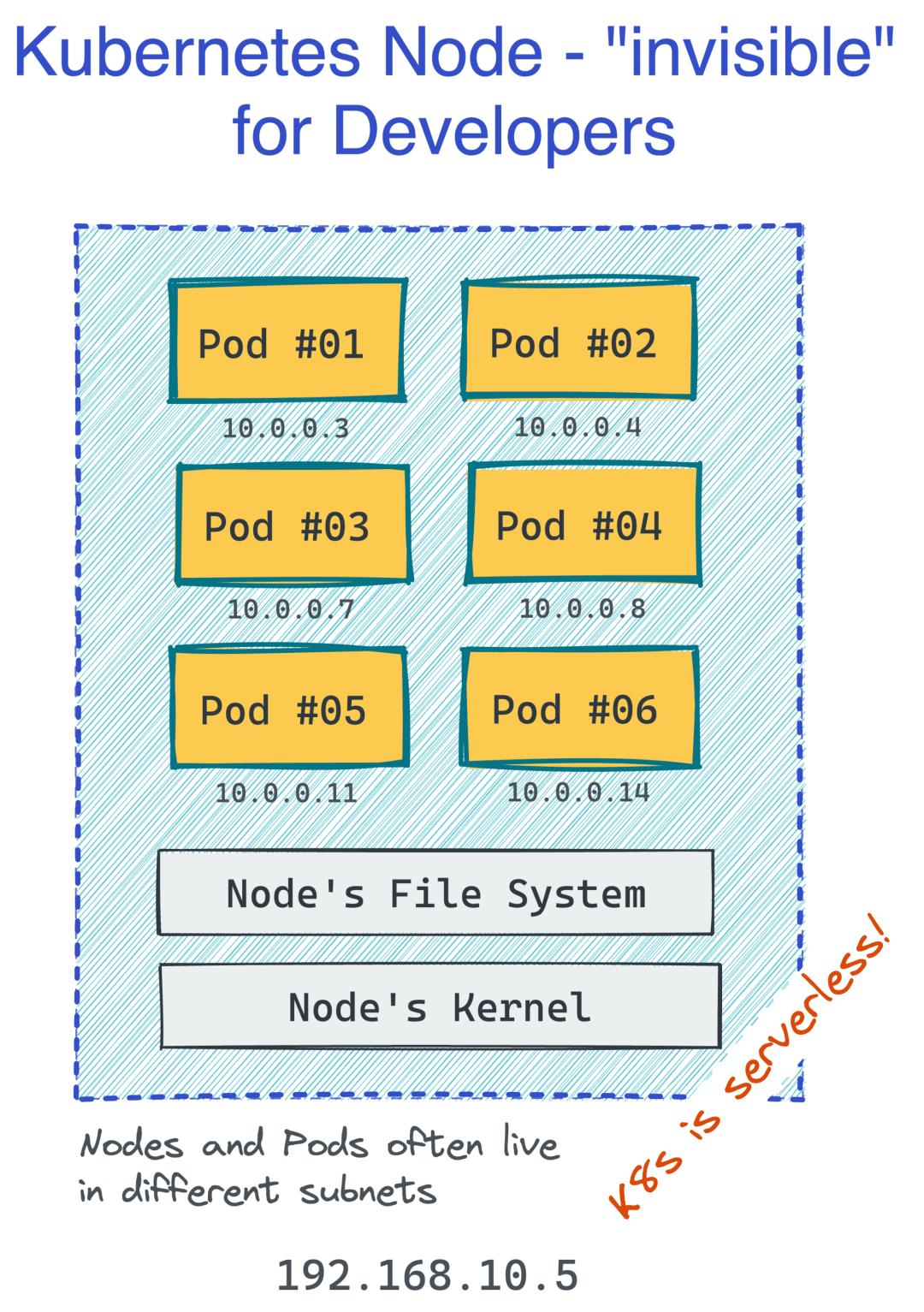
Kubernetes 的伟大之处在于作为开发人员,您并不关心服务器(或 Kubernetes 术语中的节点)。您根据 Pod 组进行思考和操作,它们会自动调动(和重新分布)到集群节点:
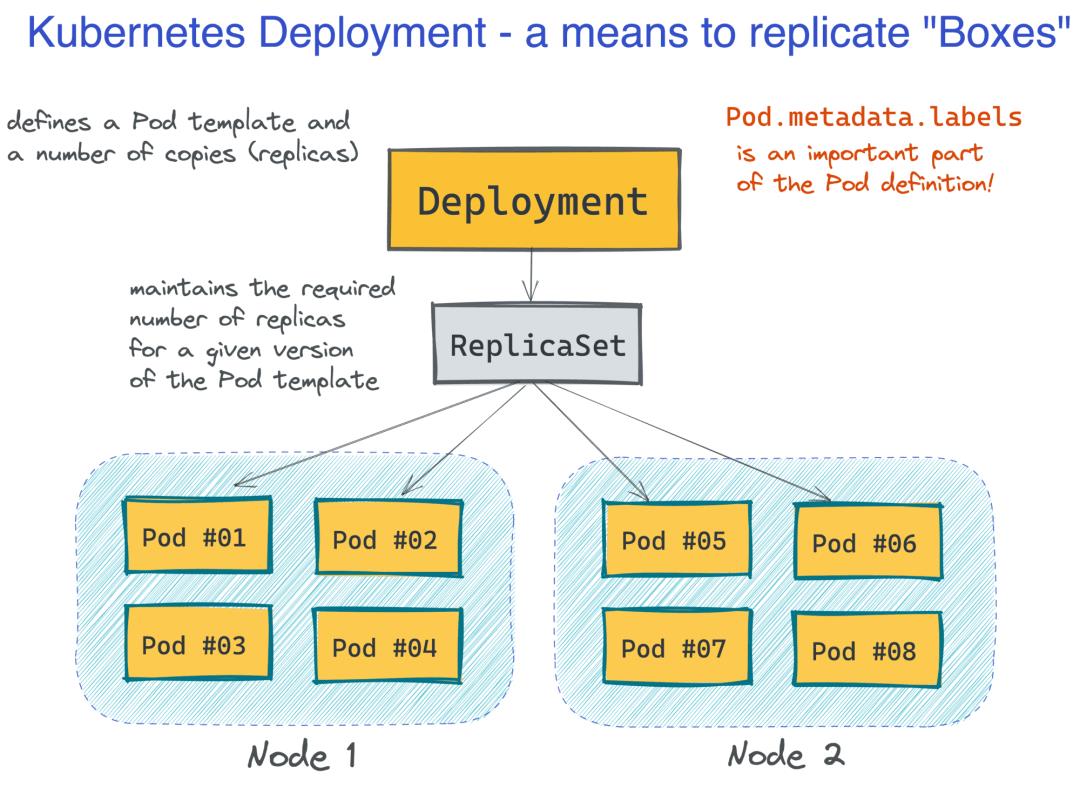
这使得 Kubernetes 更像是一种无服务器技术。但同时,Pod 的外观和行为与过去熟悉的 VM 非常相似(除了您不需要管理它们),因此您可以在熟悉的抽象中设计和推理您的应用程序:
内置服务发现
Kubernetes Service - 一组命名的 Pod。Kubernetes 设计人员肯定知道,仅仅创建 N 个盒子的副本并将其称为服务是不够的。客户端应该能够使用单个(可能是逻辑的)名称访问服务,并且服务发现系统应该能够将该名称转换为特定的 IP 地址(类似于我们理解的负载均衡器,服务于特定的实例) )。
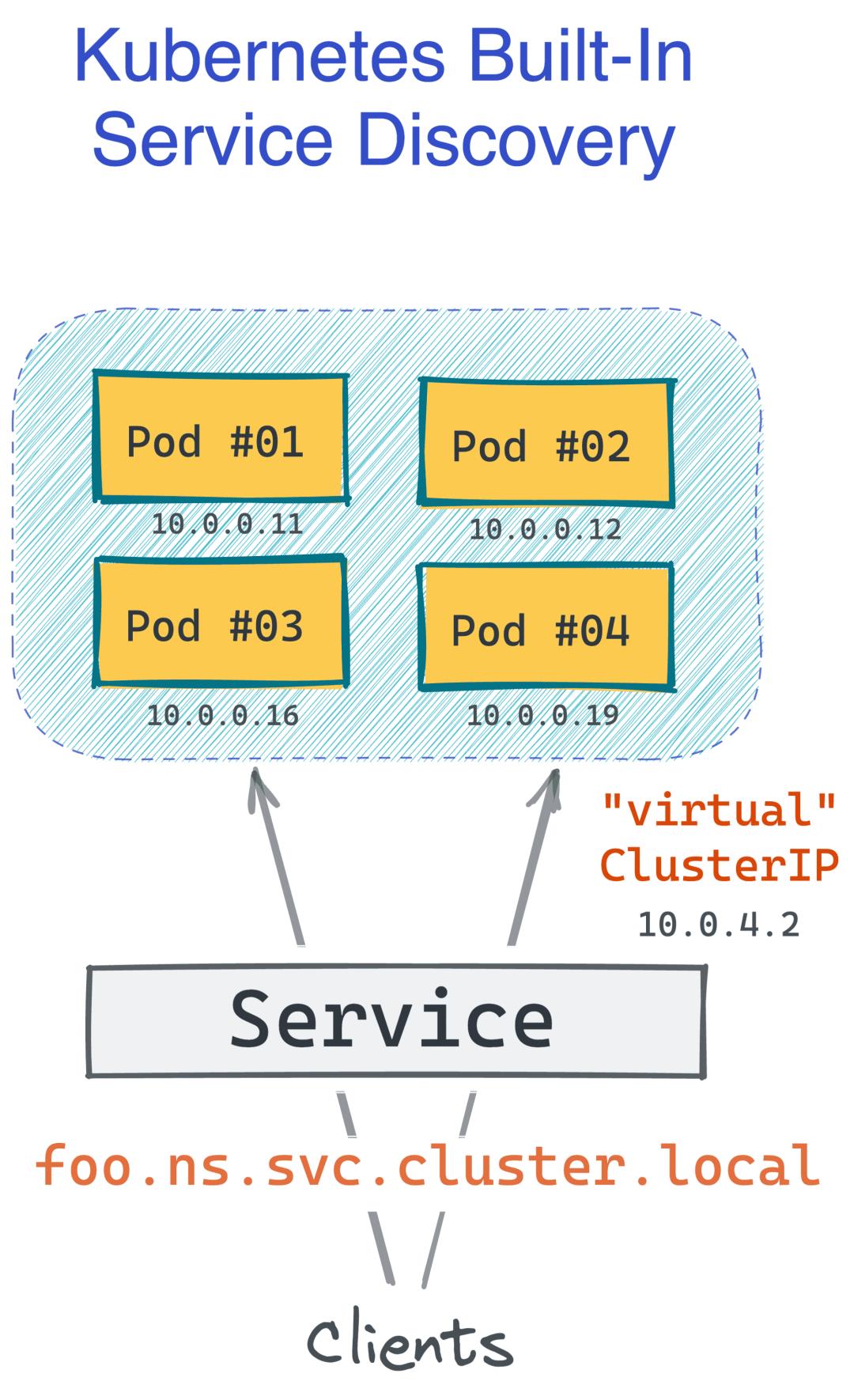
过去,您需要一个单独的(并且要求非常高的)解决方案。但是,Kubernetes 内置了这个功能,而且默认实现还不错!它还可以使用Linkerd或Istio等服务网格进行扩展,使其更加强大。将一组 Pod 转换为服务唯一需要做的就是创建一个 Service 对象(不是真正的创建服务,只是一个网络层面的抽象)。下面是一个简单的 Kubernetes Service 定义:
apiVersion: v1
kind: Service
metadata:
name: foo
spec:
selector:
app: foo
ports:
- protocol: TCP
port: 80
上面的清单允许app=foo使用defaultDNS 名称(如foo.default.svc.cluster.local. 而且这一切都没有在集群中安装任何额外的软件!请注意 Service 定义在任何地方都没有提到 Deployment。就像 Deployment 本身一样,它根据 Pod 和标签运行,这使它非常强大!例如,Kubernetes 中良好的蓝/绿或金丝雀部署可以通过让两个 Deployment 对象在单个 Service 选择具有公共标签的 Pod 后运行不同版本的应用程序镜像来实现:
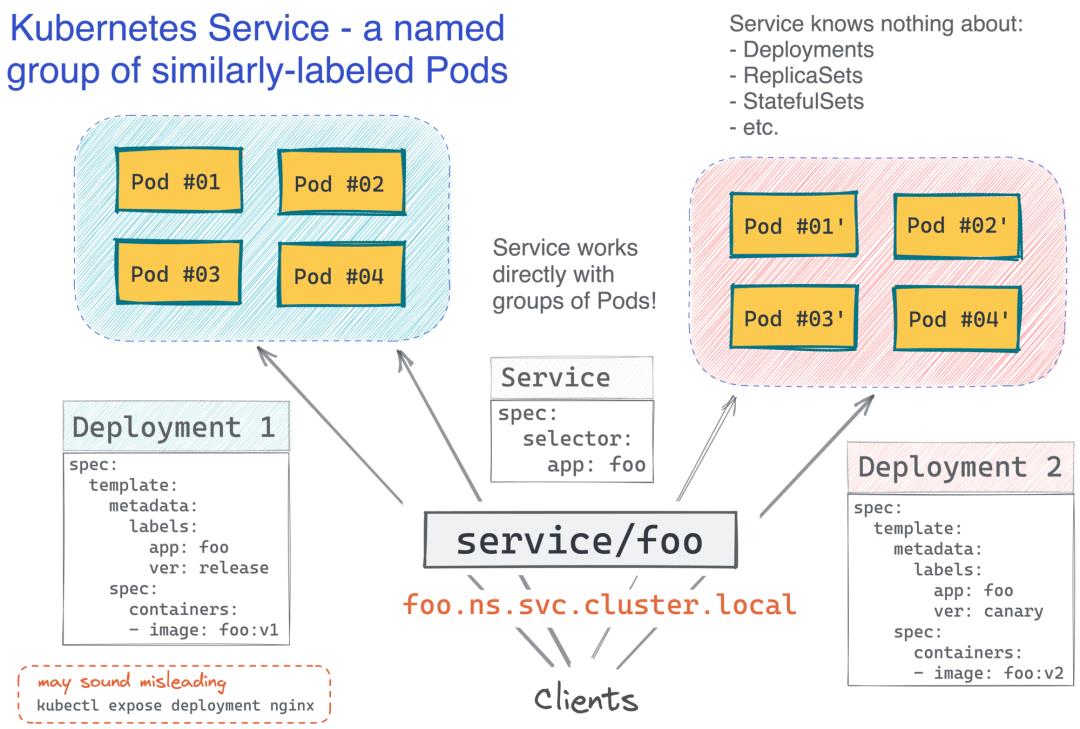
现在,最有趣的部分 - 你注意到 Kubernetes 服务与我们旧的基于 VM 的服务没有什么区别了吗?
Kubernetes 即服务
那么,Kubernetes 是不是就像 VM 一样,但更简单?嗯,是的,但也不是。因为他跟虚拟机存在本质上的差别,套用Kelsey Hightower的话,我们应该区分驾驶汽车的复杂性和修理汽车的复杂性。我们中的许多人会开车,但很少有人擅长修理发动机。幸运的是,有专门的商店!这同样适用于 Kubernetes。使用 EKS 或 GKE 等托管 Kubernetes 产品运行服务确实很相似,但比使用 VM 简单得多。但如果你必须维护 Kubernetes 集群背后的实际服务器,那就完全不同了……,所以仅仅使用 Kubernetes 和维护 Kubernetes 是两码事。
总结
为了改善在 VM 上运行服务的体验,容器改变了我们打包软件的方式,大大降低了对服务器配置的要求,并启用了替代方法来部署我们的工作负载。但就其本身而言,容器并没有成为大规模运行服务的解决方案。顶部仍然需要额外的编排层。Kubernetes 作为容器原生编排系统之一,使用容器作为基本构建块重新创建了过去熟悉的架构模式。Kubernetes 还通过提供用于扩展、部署和服务发现的内置方法来解决传统方案的痛点。
以上是关于Kubernetes 学习总结(33)—— Kubernetes 是如何重塑虚拟机的的主要内容,如果未能解决你的问题,请参考以下文章
Kubernetes 学习总结(33)—— Kubernetes 是如何重塑虚拟机的