多传感器融合综述---FOV与BEV
Posted Hermit_Rabbit
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多传感器融合综述---FOV与BEV相关的知识,希望对你有一定的参考价值。
0. 简介
在阅读了许多多传感器工作后,这里作者对多传感器融合的方法做出总结。本文将从单传感器讲起,并一步步去向多传感器方向总结。之前的《多传感器融合详解》博客从算法层面介绍了多传感器的分类以及数据传输的能力,而《多传感器融合感知 --传感器外参标定及在线标定学习》博客则是从标定层面向读者介绍了如何对多传感器进行先一步的标定处理。而这篇文章将从方法层面总括多传感器的分类以及作者对多传感器的理解与思考。
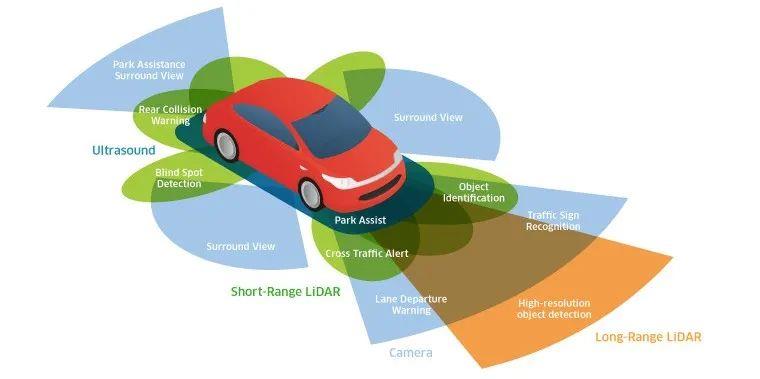
1. FOV视角
FOV作为一种最接近人类的视角,拥有悠久的历史,如今的2D\\3D object detection皆从FOV视角做起。在深度学习方面,FOV相较于最近几年才流行的BEV方法来说,其拥有更快的相应速度(BEV大多数都是在使用Transformer)以及更多的数据集。但是,FOV的信息也有一些缺点:遮挡问题,尺度问题(不同的物体在不同深度下尺度不同)、难以与其他模态融合、融合损失高(Lidar Radar等适合于BEV视角)等。
1.1 FOV—物体识别2D
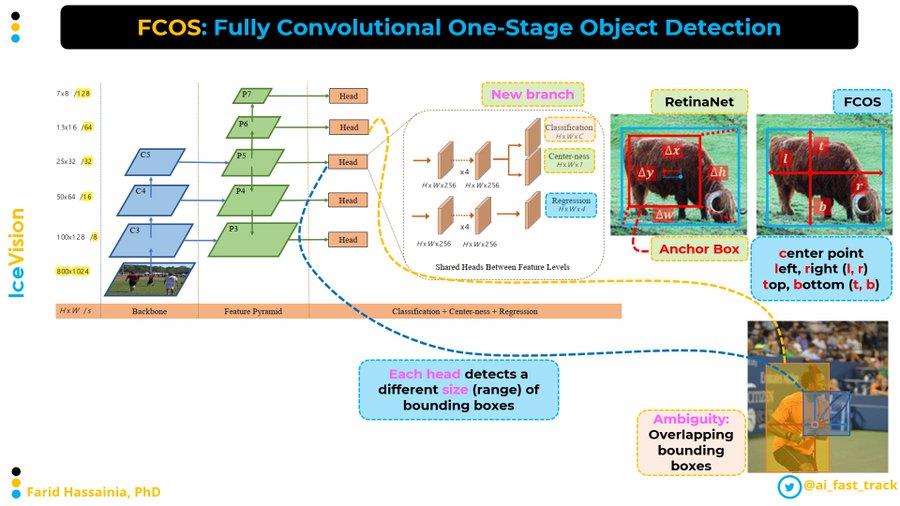
这里不过多介绍,基本前几年主流的物体识别算法都是在FOV视角下完成的。其识别算法又主要分为one-stage, two-stage, anchor-based, anchor-free这几种。这里我们给出一个近几年anchor-free的开创性工作的文章FCOS。这个模型是第一个不基于anchor,但可以和基于anchor的单阶段或双阶段目标检测模型比较。FCOS重新定义目标检测,基于每个像素的检测;它使用多级预测来提高召回率并解决重叠边界框导致的歧义.它提出了“center-ness”分支,有助于抑制检测到的低质量边界框,并大幅提高整体性能.它避免了复杂的计算,例如并集交叉(IoU),FCOS 方法也用于 VFNet、YOLOX 和其他一些模型。
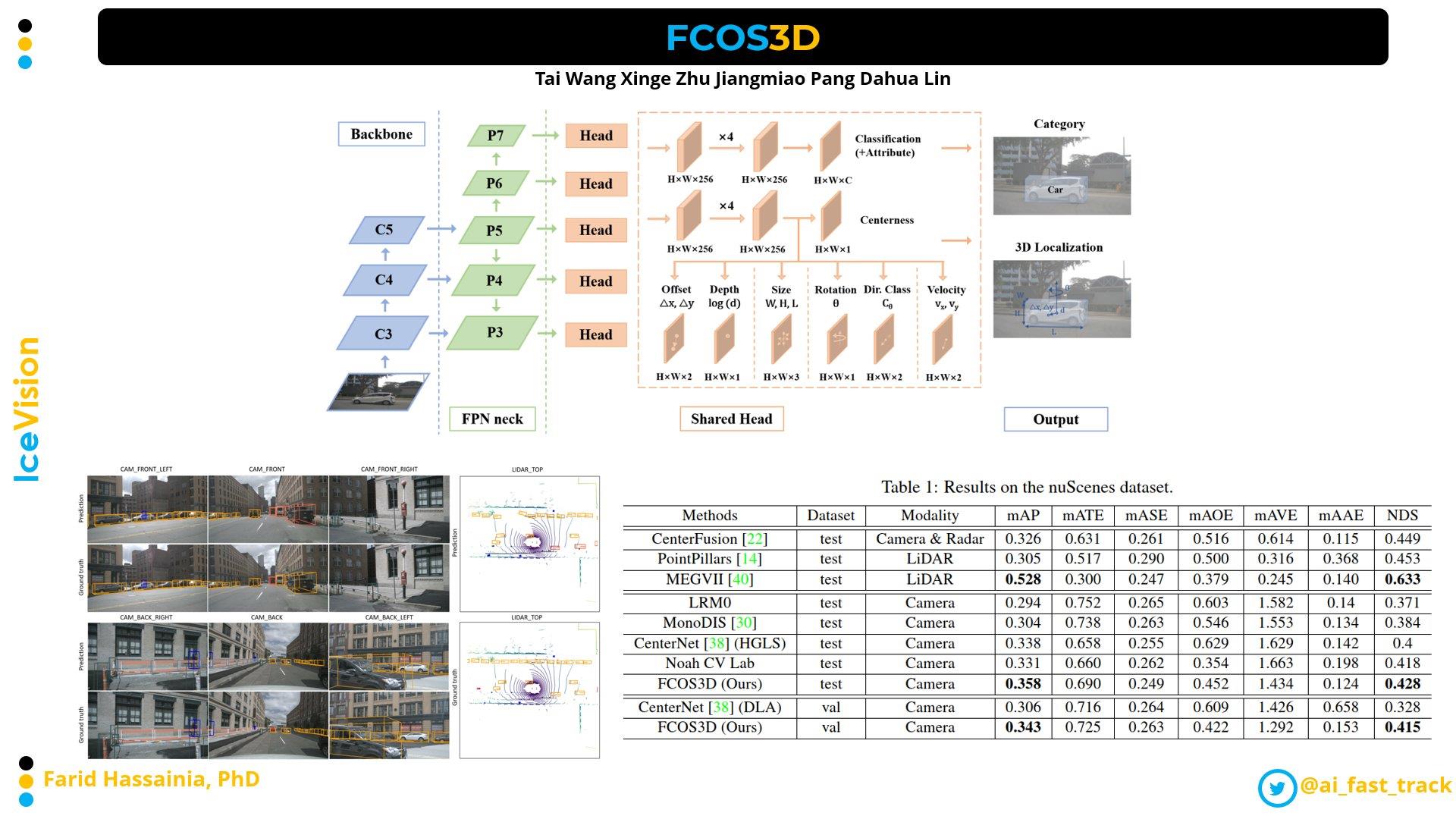
1.2 FOV—物体识别3D
这里我们给出一个FCOS3D的方法。论文作者在FCOS基础上,对Reg分支进行部分修改,使其能够回归centerpoint的同时,加入其他指标:中心偏移、深度、3D bbox大小等,实现了将2D检测器用于3D检测器的跨越。除此之外,包括YOLO3D等工作,将传统的2D detector经过简单修改直接用于3D检测的方法。
1.3 FOV—深度估计
由于深度学习的快速发展,最近几年也出现了深度估计的工作,其中比较有名的就是Pseudo-LiDAR。对于立体或单眼图像,首先预测深度图(从视差图到深度图),然后在激光雷达坐标系中将其向后投影到三维点云中。称为伪激光雷达,并像处理激光雷达一样处理它——任何基于激光雷达的检测算法都可以应用。

使用深度估计的工作解决方法主要分为三种方法:
- 训练专门的backbone编码深度信息,但是这种方法并不准确
- 将深度信息处理成pseudo-lidar作为点云信息
- 是通过BEV方式学习BEV特征到图像的映射,避免直接预测深度信息带来的误差损失。
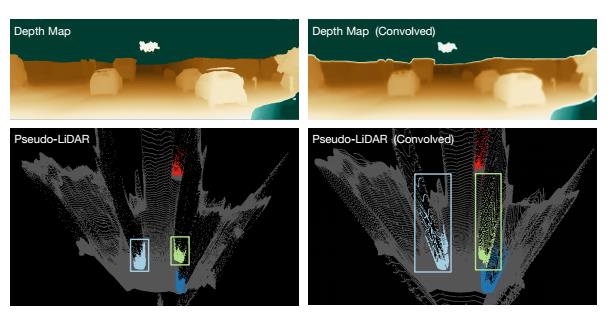
文中作者做了一个实验,下图中左边一列是原始的深度图和其对应的pseudo-lidar。对原始深度图采用卷积操作后得到了右上角的深度图,然后将其生成pseudo-lidar(右下角)。可以看见,经过卷积后的深度图产生很大的深度变形。
1.4 FOV—激光相机融合
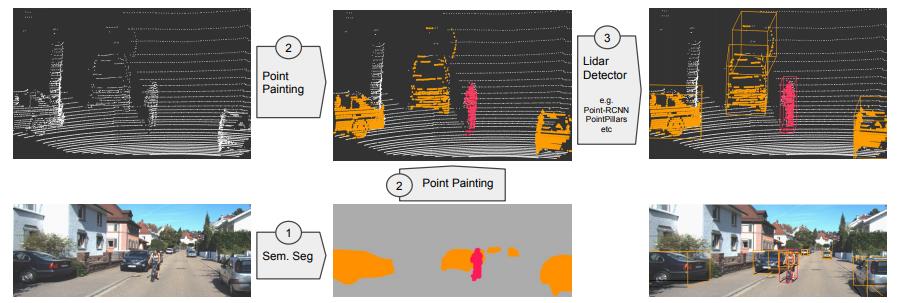
PointPainting:图像辅助点云检测,并行。作者认为,FOV to BEV方法深度信息不准确会导致融合效果不佳,在FOV检测上纯点云检测的稀疏性导致了点云的误识别问题和分类效果不佳问题,为解决纯激光雷达点云存在的纹理信息缺少等问题,以PointPainting为首的融合方法将图像分割结果融入点云图像,丰富点云语义,提高了检测性能。
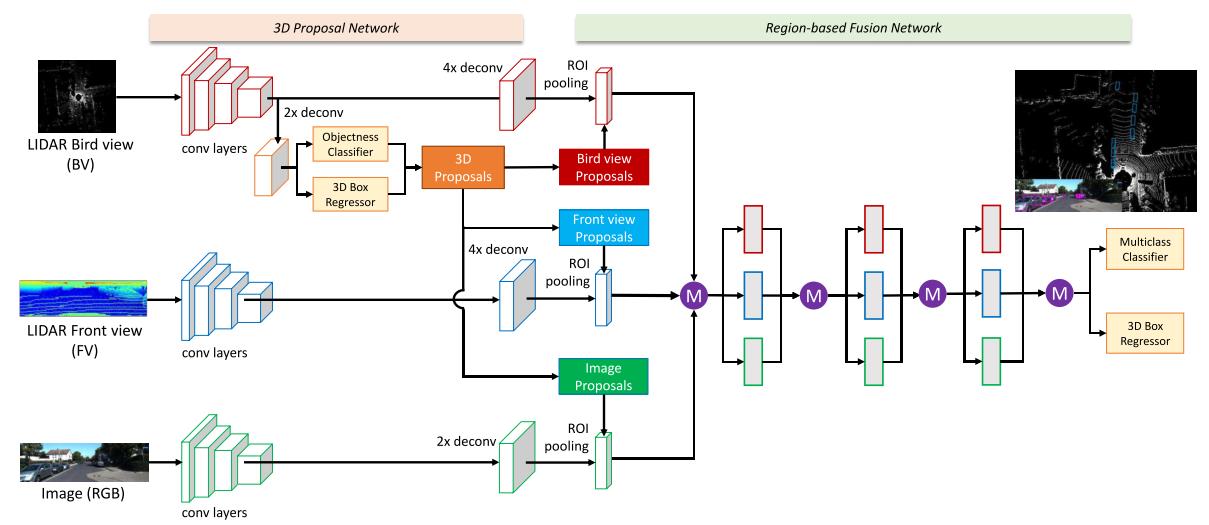
MV3D:lidar辅助图像,并行。文中作者认为,雷达点云主要存在以下问题:1)稀疏性(2)无序性(3)冗余性,这里使用点云和图像作为输入。点云的处理格式分为两种:第一种是构建俯视图(BV),构建方式是将点云栅格化,形成三维栅格,每一个栅格是该栅格内的雷达点最高的高度,每一层栅格作为一个channel,然后再加上反射率(intensity)和密度(density)的信息;第二种是构建前视图(FV),将雷达点云投影到柱坐标系内,也有文章叫做range view,然后栅格化,形成柱坐标系内的二维栅格,构建高度、反射率和密度的channel。
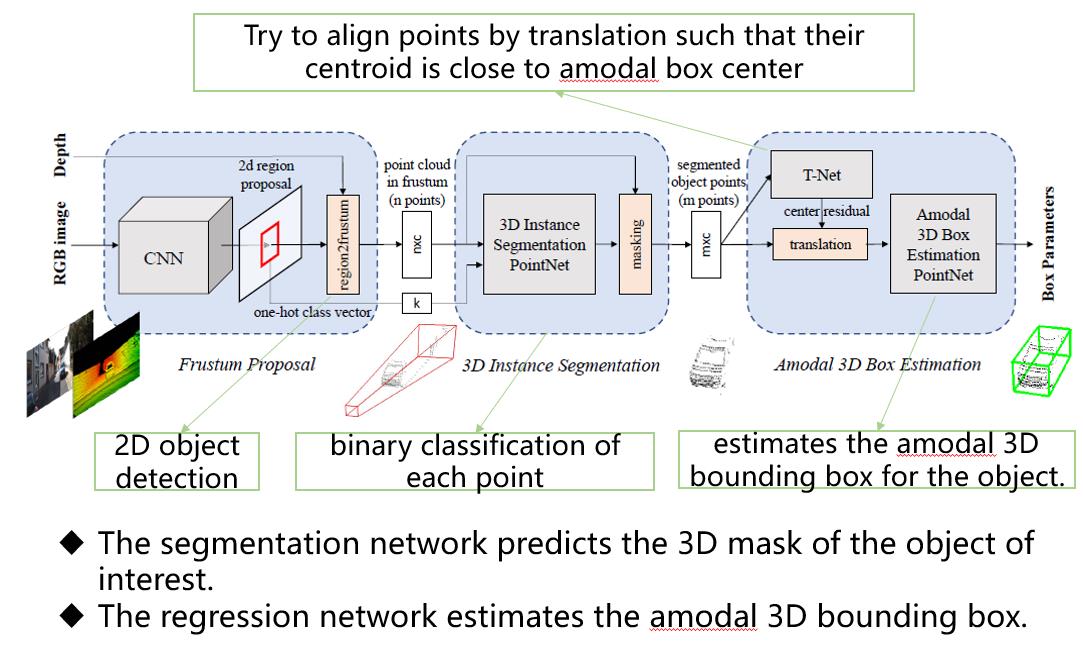
F-PointNet:图像辅助雷达,串行。文中在 RGB 图像上运行的 2D detector,产生的2D bbox用于界定3D视锥包含前景目标点云。然后基于这些视锥区域中的 3D 点云(centerfusion的灵感来源于此),使用PointNet++ 网络实现 3D实例分割并随后实现3D 边界框估计。
2. BEV视角
BEV是鸟瞰图(Bird’s Eye View)的简称,也被称为上帝视角,是一种用于描述感知世界的视角或坐标系(3D),BEV也用于代指在计算机视觉领域内的一种端到端的、由神经网络将视觉信息,从图像空间转换到BEV空间的技术。这里提供一个上海人工智能实验室2022年6月22日的直播分享—《BEV感知:下一代自动驾驶感知算法新范式》
BEV感知:下一代自动驾驶感知算法新范式
BEV特征具有以下优点:1. 能够支持多传感器融合,方便下游多任务共享feature。2. 不同物体在BEV视角下没有变形问题,能够使模型集中于解决分类问题。3. 能够融合多个视角解决遮挡问题和物体重叠问题。但是,BEV特征也有一些问题,例如grid的大小影响检测的细粒度,并且存在大量背景的存储冗余,因为BEV存储了全局的语义信息。

2.1 BEV一般使用在哪里
虽然理论上BEV可以应用在前、中、后融合过程中,不过因为前融合实现难度大,一般很少将BEV应用在前融合,偶尔也会用在后融合上,更多会应用在介于数据级融合和目标级融合之间的特征级融合,即中融合上。
所谓前融合,是指把各传感器的数据采集后,经过数据同步后,对这些原始数据进行融合。其优势是可以从整体上来处理信息,让数据更早做融合,从而让数据更有关联性。不过其挑战也很明显,因为视觉数据和激光雷达点云数据是异构数据,其坐标系不同,在进行融合时,只能在图像空间里把点云放进去,给图像提供深度信息,或者在点云坐标系里,通过给点云染色或做特征渲染,而让点云具有更丰富的语义信息。
所谓中融合,就是先将各个传感器通过神经网络模型提取中间层特征(即有效特征),再对多种传感器的有效主要特征进行融合,从而更有可能得到最佳推理。对有效特征在BEV空间进行融合,一来数据损失少,二来算力消耗也较少(相对于前融合),所以一般在BEV空间进行中融合比较多。
所谓后融合,是指各传感器针对目标物体单独进行深度学习模型推理,从而各自输出带有传感器自身属性的结果,并在决策层进行融合。其优势是不同的传感器都独立进行目标识别,解耦性好,且各传感器可以互为冗余备份。不过后融合也有缺点,当各自传感器经过目标识别再进行融合时,中间损失了很多有效信息,影响了感知精度,而且最终的融合算法,仍然是一种基于规则的方法,要根据先验知识来设定传感器的置信度,局限性很明显。
…详情请参照古月居
以上是关于多传感器融合综述---FOV与BEV的主要内容,如果未能解决你的问题,请参考以下文章
图像融合基于matlab GUI图像融合含Matlab源码 2183期
图像融合基于matlab增强随机游走算法多焦点图像融合含Matlab源码 1975期