scikit-learn学习之K最近邻算法(KNN)
Posted 搜索与推荐Wiki
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了scikit-learn学习之K最近邻算法(KNN)相关的知识,希望对你有一定的参考价值。
======================================================================
本系列博客主要参考 Scikit-Learn 官方网站上的每一个算法进行,并进行部分翻译,如有错误,请大家指正
======================================================================
决策树的算法分析与Python代码实现请参考之前的一篇博客:K最近邻Python实现 接下来我主要演示怎么使用Scikit-Learn完成K最近邻算法的调用
Scikit-Learn中 sklearn.neighbors的函数包括(点击查看来源URL)
sklearn.neighbors: Nearest Neighbors
The sklearn.neighbors module implements the k-nearest neighbors algorithm.
User guide: See the Nearest Neighbors section for further details.
neighbors.NearestNeighbors([n_neighbors, ...]) | Unsupervised learner for implementing neighbor searches. |
neighbors.KNeighborsClassifier([...]) | Classifier implementing the k-nearest neighbors vote. |
neighbors.RadiusNeighborsClassifier([...]) | Classifier implementing a vote among neighbors within a given radius |
neighbors.KNeighborsRegressor([n_neighbors, ...]) | Regression based on k-nearest neighbors. |
neighbors.RadiusNeighborsRegressor([radius, ...]) | Regression based on neighbors within a fixed radius. |
neighbors.NearestCentroid([metric, ...]) | Nearest centroid classifier. |
neighbors.BallTree | BallTree for fast generalized N-point problems |
neighbors.KDTree | KDTree for fast generalized N-point problems |
neighbors.LSHForest([n_estimators, radius, ...]) | Performs approximate nearest neighbor search using LSH forest. |
neighbors.DistanceMetric | DistanceMetric class |
neighbors.KernelDensity([bandwidth, ...]) | Kernel Density Estimation |
neighbors.kneighbors_graph(X, n_neighbors[, ...]) | Computes the (weighted) graph of k-Neighbors for points in X |
neighbors.radius_neighbors_graph(X, radius) | Computes the (weighted) graph of Neighbors for points in X |
首先看一个简单的小例子:
Finding the Nearest Neighbors
sklearn.neighbors.NearestNeighbors具体说明查看:URL 在这只是将用到的加以注释
#coding:utf-8
'''
Created on 2016/4/24
@author: Gamer Think
'''
#导入NearestNeighbor包 和 numpy
from sklearn.neighbors import NearestNeighbors
import numpy as np
#定义一个数组
X = np.array([[-1,-1],
[-2,-1],
[-3,-2],
[1,1],
[2,1],
[3,2]
])
"""
NearestNeighbors用到的参数解释
n_neighbors=5,默认值为5,表示查询k个最近邻的数目
algorithm='auto',指定用于计算最近邻的算法,auto表示试图采用最适合的算法计算最近邻
fit(X)表示用X来训练算法
"""
nbrs = NearestNeighbors(n_neighbors=3, algorithm="ball_tree").fit(X)
#返回距离每个点k个最近的点和距离指数,indices可以理解为表示点的下标,distances为距离
distances, indices = nbrs.kneighbors(X)
print indices
print distances输出结果为:
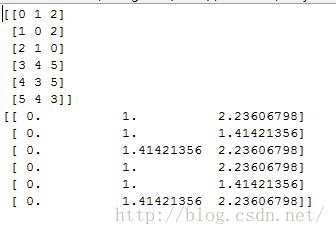
执行
#输出的是求解n个最近邻点后的矩阵图,1表示是最近点,0表示不是最近点
print nbrs.kneighbors_graph(X).toarray()
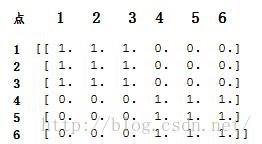
KDTree and BallTree Classes
#测试 KDTree
'''
leaf_size:切换到蛮力的点数。改变leaf_size不会影响查询结果,
但能显著影响查询和存储所需的存储构造树的速度。
需要存储树的规模约n_samples / leaf_size内存量。
为指定的leaf_size,叶节点是保证满足leaf_size <= n_points < = 2 * leaf_size,
除了在的情况下,n_samples < leaf_size。
metric:用于树的距离度量。默认'minkowski与P = 2(即欧氏度量)。
看到一个可用的度量的距离度量类的文档。
kd_tree.valid_metrics列举这是有效的基础指标。
'''
from sklearn.neighbors import KDTree
import numpy as np
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
kdt = KDTree(X,leaf_size=30,metric="euclidean")
print kdt.query(X, k=3, return_distance=False)
#测试 BallTree
from sklearn.neighbors import BallTree
import numpy as np
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
bt = BallTree(X,leaf_size=30,metric="euclidean")
print bt.query(X, k=3, return_distance=False)
其输出结果均为:

这是在小数据集的情况下并不能看到他们的差别,当数据集变大时,这种差别便显而易见了
使用scikit-learn的KNN算法进行分类的一个实例,使用数据集依旧是iris(鸢尾花)数据集
<span style="font-size:18px;">#coding:utf-8
'''
Created on 2016年4月24日
@author: Gamer Think
'''
from sklearn.datasets import load_iris
from sklearn import neighbors
import sklearn
#查看iris数据集
iris = load_iris()
print iris
knn = neighbors.KNeighborsClassifier()
#训练数据集
knn.fit(iris.data, iris.target)
#预测
predict = knn.predict([[0.1,0.2,0.3,0.4]])
print predict
print iris.target_names[predict]</span>预测结果为:
[0] #第0类
['setosa'] #第0类对应花的名字
使用python实现的KNN算法进行分类的一个实例,使用数据集依旧是iris(鸢尾花)数据集,只不过将其保存在iris.txt文件中
<span style="font-size:18px;"> #-*- coding: UTF-8 -*-
'''
Created on 2016/4/24
@author: Administrator
'''
import csv #用于处理csv文件
import random #用于随机数
import math
import operator #
from sklearn import neighbors
#加载数据集
def loadDataset(filename,split,trainingSet=[],testSet = []):
with open(filename,"rb") as csvfile:
lines = csv.reader(csvfile)
dataset = list(lines)
for x in range(len(dataset)-1):
for y in range(4):
dataset[x][y] = float(dataset[x][y])
if random.random()<split:
trainingSet.append(dataset[x])
else:
testSet.append(dataset[y])
#计算距离
def euclideanDistance(instance1,instance2,length):
distance = 0
for x in range(length):
distance = pow((instance1[x] - instance2[x]),2)
return math.sqrt(distance)
#返回K个最近邻
def getNeighbors(trainingSet,testInstance,k):
distances = []
length = len(testInstance) -1
#计算每一个测试实例到训练集实例的距离
for x in range(len(trainingSet)):
dist = euclideanDistance(testInstance, trainingSet[x], length)
distances.append((trainingSet[x],dist))
#对所有的距离进行排序
distances.sort(key=operator.itemgetter(1))
neighbors = []
#返回k个最近邻
for x in range(k):
neighbors.append(distances[x][0])
return neighbors
#对k个近邻进行合并,返回value最大的key
def getResponse(neighbors):
classVotes =
for x in range(len(neighbors)):
response = neighbors[x][-1]
if response in classVotes:
classVotes[response]+=1
else:
classVotes[response] = 1
#排序
sortedVotes = sorted(classVotes.iteritems(),key = operator.itemgetter(1),reverse =True)
return sortedVotes[0][0]
#计算准确率
def getAccuracy(testSet,predictions):
correct = 0
for x in range(len(testSet)):
if testSet[x][-1] == predictions[x]:
correct+=1
return (correct/float(len(testSet))) * 100.0
def main():
trainingSet = [] #训练数据集
testSet = [] #测试数据集
split = 0.67 #分割的比例
loadDataset(r"iris.txt", split, trainingSet, testSet)
print "Train set :" + repr(len(trainingSet))
print "Test set :" + repr(len(testSet))
predictions = []
k = 3
for x in range(len(testSet)):
neighbors = getNeighbors(trainingSet, testSet[x], k)
result = getResponse(neighbors)
predictions.append(result)
print ">predicted = " + repr(result) + ",actual = " + repr(testSet[x][-1])
accuracy = getAccuracy(testSet, predictions)
print "Accuracy:" + repr(accuracy) + "%"
if __name__ =="__main__":
main() </span>
附iris.txt文件的内容
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
4.7,3.2,1.3,0.2,Iris-setosa
4.6,3.1,1.5,0.2,Iris-setosa
5.0,3.6,1.4,0.2,Iris-setosa
5.4,3.9,1.7,0.4,Iris-setosa
4.6,3.4,1.4,0.3,Iris-setosa
5.0,3.4,1.5,0.2,Iris-setosa
4.4,2.9,1.4,0.2,Iris-setosa
4.9,3.1,1.5,0.1,Iris-setosa
5.4,3.7,1.5,0.2,Iris-setosa
4.8,3.4,1.6,0.2,Iris-setosa
4.8,3.0,1.4,0.1,Iris-setosa
4.3,3.0,1.1,0.1,Iris-setosa
5.8,4.0,1.2,0.2,Iris-setosa
5.7,4.4,1.5,0.4,Iris-setosa
5.4,3.9,1.3,0.4,Iris-setosa
5.1,3.5,1.4,0.3,Iris-setosa
5.7,3.8,1.7,0.3,Iris-setosa
5.1,3.8,1.5,0.3,Iris-setosa
5.4,3.4,1.7,0.2,Iris-setosa
5.1,3.7,1.5,0.4,Iris-setosa
4.6,3.6,1.0,0.2,Iris-setosa
5.1,3.3,1.7,0.5,Iris-setosa
4.8,3.4,1.9,0.2,Iris-setosa
5.0,3.0,1.6,0.2,Iris-setosa
5.0,3.4,1.6,0.4,Iris-setosa
5.2,3.5,1.5,0.2,Iris-setosa
5.2,3.4,1.4,0.2,Iris-setosa
4.7,3.2,1.6,0.2,Iris-setosa
4.8,3.1,1.6,0.2,Iris-setosa
5.4,3.4,1.5,0.4,Iris-setosa
5.2,4.1,1.5,0.1,Iris-setosa
5.5,4.2,1.4,0.2,Iris-setosa
4.9,3.1,1.5,0.1,Iris-setosa
5.0,3.2,1.2,0.2,Iris-setosa
5.5,3.5,1.3,0.2,Iris-setosa
4.9,3.1,1.5,0.1,Iris-setosa
4.4,3.0,1.3,0.2,Iris-setosa
5.1,3.4,1.5,0.2,Iris-setosa
5.0,3.5,1.3,0.3,Iris-setosa
4.5,2.3,1.3,0.3,Iris-setosa
4.4,3.2,1.3,0.2,Iris-setosa
5.0,3.5,1.6,0.6,Iris-setosa
5.1,3.8,1.9,0.4,Iris-setosa
4.8,3.0,1.4,0.3,Iris-setosa
5.1,3.8,1.6,0.2,Iris-setosa
4.6,3.2,1.4,0.2,Iris-setosa
5.3,3.7,1.5,0.2,Iris-setosa
5.0,3.3,1.4,0.2,Iris-setosa
7.0,3.2,4.7,1.4,Iris-versicolor
6.4,3.2,4.5,1.5,Iris-versicolor
6.9,3.1,4.9,1.5,Iris-versicolor
5.5,2.3,4.0,1.3,Iris-versicolor
6.5,2.8,4.6,1.5,Iris-versicolor
5.7,2.8,4.5,1.3,Iris-versicolor
6.3,3.3,4.7,1.6,Iris-versicolor
4.9,2.4,3.3,1.0,Iris-versicolor
6.6,2.9,4.6,1.3,Iris-versicolor
5.2,2.7,3.9,1.4,Iris-versicolor
5.0,2.0,3.5,1.0,Iris-versicolor
5.9,3.0,4.2,1.5,Iris-versicolor
6.0,2.2,4.0,1.0,Iris-versicolor
6.1,2.9,4.7,1.4,Iris-versicolor
5.6,2.9,3.6,1.3,Iris-versicolor
6.7,3.1,4.4,1.4,Iris-versicolor
5.6,3.0,4.5,1.5,Iris-versicolor
5.8,2.7,4.1,1.0,Iris-versicolor
6.2,2.2,4.5,1.5,Iris-versicolor
5.6,2.5,3.9,1.1,Iris-versicolor
5.9,3.2,4.8,1.8,Iris-versicolor
6.1,2.8,4.0,1.3,Iris-versicolor
6.3,2.5,4.9,1.5,Iris-versicolor
6.1,2.8,4.7,1.2,Iris-versicolor
6.4,2.9,4.3,1.3,Iris-versicolor
6.6,3.0,4.4,1.4,Iris-versicolor
6.8,2.8,4.8,1.4,Iris-versicolor
6.7,3.0,5.0,1.7,Iris-versicolor
6.0,2.9,4.5,1.5,Iris-versicolor
5.7,2.6,3.5,1.0,Iris-versicolor
5.5,2.4,3.8,1.1,Iris-versicolor
5.5,2.4,3.7,1.0,Iris-versicolor
5.8,2.7,3.9,1.2,Iris-versicolor
6.0,2.7,5.1,1.6,Iris-versicolor
5.4,3.0,4.5,1.5,Iris-versicolor
6.0,3.4,4.5,1.6,Iris-versicolor
6.7,3.1,4.7,1.5,Iris-versicolor
6.3,2.3,4.4,1.3,Iris-versicolor?
5.6,3.0,4.1,1.3,Iris-versicolor
5.5,2.5,4.0,1.3,Iris-versicolor
5.5,2.6,4.4,1.2,Iris-versicolor
6.1,3.0,4.6,1.4,Iris-versicolor
5.8,2.6,4.0,1.2,Iris-versicolor
5.0,2.3,3.3,1.0,Iris-versicolor
5.6,2.7,4.2,1.3,Iris-versicolor
5.7,3.0,4.2,1.2,Iris-versicolor
5.7,2.9,4.2,1.3,Iris-versicolor
6.2,2.9,4.3,1.3,Iris-versicolor
5.1,2.5,3.0,1.1,Iris-versicolor
5.7,2.8,4.1,1.3,Iris-versicolor
6.3,3.3,6.0,2.5,Iris-virginica
5.8,2.7,5.1,1.9,Iris-virginica
7.1,3.0,5.9,2.1,Iris-virginica
6.3,2.9,5.6,1.8,Iris-virginica
6.5,3.0,5.8,2.2,Iris-virginica
7.6,3.0,6.6,2.1,Iris-virginica
4.9,2.5,4.5,1.7,Iris-virginica
7.3,2.9,6.3,1.8,Iris-virginica
6.7,2.5,5.8,1.8,Iris-virginica
7.2,3.6,6.1,2.5,Iris-virginica
6.5,3.2,5.1,2.0,Iris-virginica
6.4,2.7,5.3,1.9,Iris-virginica
6.8,3.0,5.5,2.1,Iris-virginica
5.7,2.5,5.0,2.0,Iris-virginica
5.8,2.8,5.1,2.4,Iris-virginica
6.4,3.2,5.3,2.3,Iris-virginica
6.5,3.0,5.5,1.8,Iris-virginica
7.7,3.8,6.7,2.2,Iris-virginica
7.7,2.6,6.9,2.3,Iris-virginica
6.0,2.2,5.0,1.5,Iris-virginica
6.9,3.2,5.7,2.3,Iris-virginica
5.6,2.8,4.9,2.0,Iris-virginica
7.7,2.8,6.7,2.0,Iris-virginica
6.3,2.7,4.9,1.8,Iris-virginica
6.7,3.3,5.7,2.1,Iris-virginica
7.2,3.2,6.0,1.8,Iris-virginica
6.2,2.8,4.8,1.8,Iris-virginica
6.1,3.0,4.9,1.8,Iris-virginica
6.4,2.8,5.6,2.1,Iris-virginica
7.2,3.0,5.8,1.6,Iris-virginica
7.4,2.8,6.1,1.9,Iris-virginica
7.9,3.8,6.4,2.0,Iris-virginica

扫一扫 关注微信公众号!号主 专注于搜索和推荐系统,尝试使用算法去更好的服务于用户,包括但不局限于机器学习,深度学习,强化学习,自然语言理解,知识图谱,还不定时分享技术,资料,思考等文章!
【技术服务】,详情点击查看:https://mp.weixin.qq.com/s/PtX9ukKRBmazAWARprGIAg

以上是关于scikit-learn学习之K最近邻算法(KNN)的主要内容,如果未能解决你的问题,请参考以下文章