计算机体系结构的新黄金时代
Posted 范桂飓
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了计算机体系结构的新黄金时代相关的知识,希望对你有一定的参考价值。
前言
图灵奖得主 David Patterson 与 John Hennessy 认为,未来将是计算机体系结构的黄金十年。最新一期的 ACM 通讯上刊登了两人合著的论文《计算机体系结构的新黄金时代》。

计算机体系结构的新黄金时代(A New Golden Age for computer Architecture)
不能牢记过去的人,必定重蹈覆辙。
—— George Santayana,1905 年
软件通过称为指令集架构(ISA)的词汇表与硬件实现交互。在 20 世纪 60 年代初,IBM 共推出了四个彼此不兼容的计算机系列,每个计算机系列都有自己的 ISA、软件堆栈和输入/输出系统,分别针对小型企业、大型企业,科研单位和实时运算。 IBM 的工程师们,包括 ACM 图灵奖获奖者 Fred Brooks 在内,都认为能够创建一套新的 ISA,将这四套 ISA 有效统一起来。
这需要一套技术解决方案,让计算 8 位数据路径的廉价计算机和计算 64 位数据路径的昂贵计算机可以共享一个 ISA。数据路径(data path)是处理器的 “肌肉”,因为这部分负责执行算法,但相对容易 “加宽” 或 “缩小”。当时和现在计算机设计人员共同面临的最大挑战是处理器的 “大脑”,即控制硬件。受软件编程的启发,计算机先驱人物、图灵奖获得者莫里斯·威尔克斯提出了简化控制流程的思路。控制部分被指定为一个二维数组,他称之为 “控制存储”。数组的每一列对应一条控制线,每一行都是微指令,写微指令的操作称为微编程。控制存储包含使用微指令编写的 ISA 解释器,因此执行一个传统指令需要多个微指令完成。控制存储通过内存实现,这比使用逻辑门的成本要低得多。
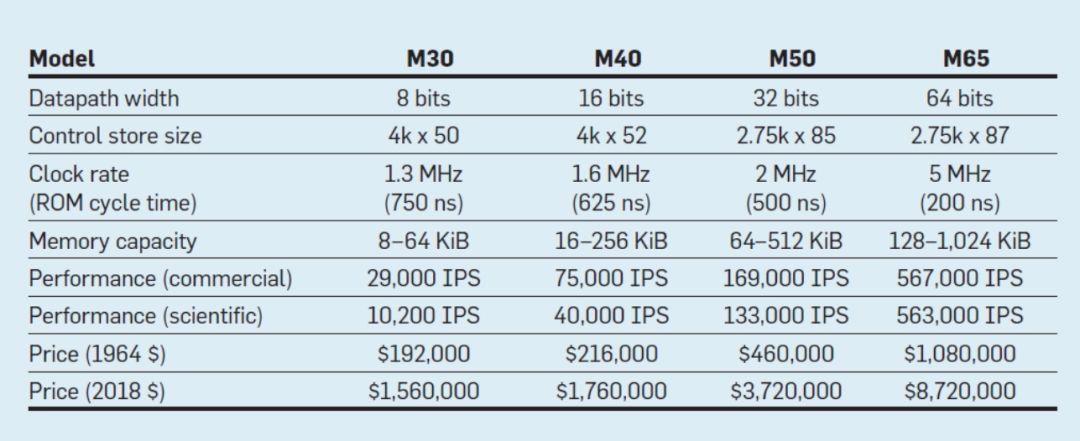
此表列出了 IBM 于 1964 年 4 月 7 日发布的新 360 System 的四种型号的指令集。四种型号之间。数据路径相差 8 倍,内存容量相差 16 倍,时钟速率相差近 4 倍,而性能相差 50 倍,其中最昂贵的机型 M65 具有最大空间的控制存储,因为更复杂的数据路径需要使用更多的控制线。由于硬件更简单,成本最低的机型 M30 的控制存储空间最小,但由于它们需要更多的时钟周期来执行 360 System 的指令,因此需要有更多的微指令。
通过微程序设计,IBM 认为新的 ISA 将能够彻底改变计算行业,赢得未来。 IBM 统治了当时的计算机市场,55 年前诞生的 IBM 大型机,其后代产品现在每年仍能为 IBM 带来 100 亿美元的收入。
现在看来,尽管市场对技术问题做出的评判还不够完善,但由于硬件系统架构与商用计算机之间的密切联系,市场最终成为计算机架构创新的是否成功的关键性因素,这些创新往往需要工程人员方面的大量投入。
集成电路,CISC,432,8086,IBM PC。当计算机开始使用集成电路时,摩尔定律意味着控制存储可能变得更大。更大的内存可以运行更复杂的 ISA。1977 年,数字设备公司(Digital Equipment)发布的 VAX-11/780 机型的控制存储大小达到 5120 word×96 bit,而其之前的型号仅为 256 word×56 bit。
一些制造商选择让选定的客户添加名为 “可写控制存储”(WCS)的自定义功能来进行微程序设计。最著名 WCS 计算机是 Alto,这是图灵奖获得者 Chuck Thacker 和 Butler Lampson 以及他们的同事们于 1973 年为 Xerox Palo Alto 研究中心设计制造的。它是第一台个人计算机,使用第一台位映射显示器和第一个以太局域网。用于支持新显示器和网络的设备控制器是存储在 4096 word×32 bit WCS 中的微程序。
微处理器在 20 世纪 70 年代仍处于 8 位时代(如英特尔的 8080 处理器),主要采用汇编语言编程。各家企业的设计师会不断加入新的指令来超越竞争对手,通过汇编语言展示他们的优势。
戈登·摩尔认为英特尔的下一代指令集架构将能够延续英特尔的生命,他聘请了大批聪明的计算机科学博士,并将他们送到波特兰的一个新工厂,以打造下一个伟大的指令集架构。英特尔最初推出 8800 处理器是一个雄心勃勃的计算机架构项目,适用于任何时代,它具有 32 位寻址能力、面向对象的体系结构,可变位的长指令,以及用当时新的编程语言 Ada 编写的自己的操作系统。
- 图1 IBM 360 系列机型的参数,IPS 意为 “每秒操作数”
这个雄心勃勃的项目迟迟不能退出,这迫使英特尔紧急改变计划,于 1979 年推出一款 16 位微处理器。英特尔为新团队提供了 52 周的时间来开发新的 “8086” 指令集,并设计和构建芯片。由于时间紧迫,设计 ISA 部分仅仅花了 3 周时间,主要是将 8 位寄存器和 8080 的指令集扩展到了 16 位。团队最终按计划完成了 8086 的设计,但产品发布后几乎没有大张旗鼓的宣传。
英特尔很走运,当时 IBM 正在开发一款旨在与 Apple II 竞争的个人计算机,正需要 16 位微处理器。 IBM 一度对摩托罗拉的 68000 型感兴趣,它拥有类似于 IBM 360 的指令集架构,但与 IBM 激进的方案相比显得落后。IBM 转而使用英特尔 8086 的 8 位总线版本处理器。IBM 于 1981 年 8 月 12 日宣布推出该机型,预计到 1986 年能够卖出 25 万台,结果最终在全球卖出了 1 亿台,未来前景一片光明。
英特尔的 8800 项目更名为 iAPX-432,最终于 1981 年发布,但它需要多个芯片,并且存在严重的性能问题。该项目在 1986 年终止,此前一年,英特尔将寄存器从 16 位扩展到 32 位,在 80386 芯片中扩展了 8086 指令集架构。摩尔的预测是正确的,这个指令集确实和英特尔一直存续下来,但市场却选择了紧急赶工的产品 8086,而不是英特尔寄予厚望的 iAPX-432,这对摩托罗拉 68000 和 iAPX-432 的架构师来讲,都是个现实的教训,市场永远是没有耐心的。
从复杂指令集计算机到精简指令集计算机。20 世纪 80 年代初期,对使用大型控制存储中的大型微程序的复杂指令集计算机(CISC)的相关问题进行过几项调查。Unix 的广泛应用,证明连操作系统都可以使用高级语言,所以关键问题就是:“编译器会产生什么指令?” 而不是 “程序员使用什么汇编语言?” 软硬件交互手段的显著进步,为架构创新创造了机会。
图灵奖获得者 John Cocke 和他的同事为小型计算机开发了更简单的指令集架构和编译器。作为一项实验,他们重新定位了研究编译器,只使用简单的寄存器-寄存器操作和 IBM 360 指令集加载存储数据传输,避免了使用更复杂的指令。他们发现,使用简单子集的程序运行速度提高了三倍。 Emer 和 Clark 发现,20% 的 VAX 指令需要 60% 的微代码,仅占执行时间的 0.2%。Patterson 发现,如果微处理器制造商要遵循大型计算机的 CISC 指令集设计,就需要一种方法来修复微代码错误。
Patterson 就此问题写了一篇论文,但被《计算机》期刊拒稿。审稿人认为,构建具有 ISA 的微处理器是一个糟糕的想法,因为这需要在现场进行修复。这让人怀疑,CISC 指令集对微处理器的价值究竟有多大。具有讽刺意味的是,现代 CISC 微处理器确实包含微代码修复机制,但这篇论文被拒的主要结果是,激励了他开始研究面向微处理器的精简指令集,即复杂度较低的指令集架构,以及使用精简指令集的计算机(RISC)。
这些观点的产生,以及由汇编语言向高级语言的转变,为 CISC 向 RISC 的过渡创造了条件。首先,RISC 指令经过简化,因此不再需要微代码解释器。 RISC 指令通常与微指令一样简单,硬件能够直接执行。其次,以前用于 CISC 指令集的微代码解释器的快速存储器被重新用作 RISC 指令的高速缓存。(缓存是一个小而快速的内存,用于缓冲最近执行的指令,因为这类指令很快就会被再次调用。)第三,基于 Gregory Chaitin 的图着色方案的寄存器分配器,使编译器能够更简易、高效地使用寄存器,最后,摩尔定律意味着在 20 世纪 80 年代能够诞生有足够数量的晶体管的芯片,可以容纳一个完整的 32 位数据路径、指令集和数据高速缓存。
在今天的 “后 PC 时代”,x86 芯片的出货量自 2011 年达到峰值以来,每年下降近 10%,而采用 RISC 处理器的芯片出货量则飙升至 200 亿。
下图分别为 1982 年和 1983 年在加州大学伯克利分校和斯坦福大学开发的 RISC-I8 和 MIPS12 微处理器,体现出了 RISC 的优点。这些芯片最终于 1984 年在 IEEE 国际固态电路会议上发表。这是一个了不起的时刻,伯克利和斯坦福的一些研究生也可以构建微处理器了,可以说比行业内的产品更优秀。
- 图2 由加州大学伯克利分校开发的 RISC-I8 和斯坦福大学开发的 MIPS12 微处理器

这些由学术机构开发的芯片,激励了许多企业开始发力 RISC 微处理器,并成为此后 15 年中发展最快的领域。其原因是处理器的性能公式:
时间 / 程序 = 操作数 / 程序 x(时钟周期)/ 指令 x 时间 /(时钟周期)
DEC 公司的工程师后来表明,更复杂的 CISC 指令集每个程序执行的操作数大约为 RISC 的 75% 执行大约 75%,不过在类似的技术下,CISC 每个指令执行时间约为五到六个时钟周期,使 RISC 微处理器的运算速度是 CISC 的大约 4 倍。
20 世纪 80 年代时,这些内容还没有进入计算机体系结构的书中,所以我们在 1989 年编写《计算机架构:定量方法》( Computer Architecture: AQuantitative Approach)一书。本书的主题是使用测量和基准测试来对计算机架构进行量化评估,而不是更多地依赖于架构师的直觉和经验,就像过去一样。我们使用的定量方法也得益于图灵奖得主高德纳(Donald Knuth)关于算法的著作内容的启发。
VLIW,EPIC,Itanium 指令集架构的下一次创新试图同时惠及 RISC 和 CISC,即超长指令字(VLIW)和显式并行指令计算机(EPIC)的诞生。这两项发明由英特尔和惠普共同命名的,在每条指令中使用捆绑在一起的多个独立操作的宽指令。VLIW 和 EPIC 的拥护者认为,如果用一条指令可以指定六个独立的操作 —— 两次数据传输,两次整数操作和两次浮点操作,编译器技术可以有效地将这些操作分配到六个指令槽中,硬件架构就可以变得更简单。与 RISC 方法一样,VLIW 和 EPIC 的目的是将工作负载从硬件转移到编译器上。
英特尔和惠普合作设计了一款基于 EPIC 理念的 64 位处理器 Itanium,想用其取代 32 位 x86 处理器并对其抱了很高的期望,但实际情况与他们的早期预期并不相符。虽然 EPIC 方法适用于高度结构化的浮点程序,但在可预测性较低的缓存或的分支整数程序上很难实现高性能。正如高德纳后来所指出的那样:“Itanium 的设想非常棒,但事实证明满足这种设想的编译器基本上不可能写出来。” 开发人员注意到 Itanium 的迟钝和性能不佳,将用命途多舛的游轮 “Titanic” 其重命名为 “Itanic”。不过,市场再次失去了耐心,最终 64 位版本的 x86 成为 32 位 x86 的继承者,没有轮到 Itanium。
不过一个好消息是,VLIW 在较窄的应用程序与小程序上,包括数字信号处理任务中留有一席之地。
PC 和后 PC 时代的 RISC vs. CISC
AMD 和英特尔利用 500 人的设计团队和先进的半导体技术,缩小了 x86 和 RISC 之间的性能差距。同样,受到流水线化简单指令 vs. 复杂指令的性能优势的启发,指令解码器在运行中将复杂的 x86 指令转换成类似 RISC 的内部微指令。AMD 和英特尔随后将 RISC 微指令的执行流程化。RISC 的设计人员为了性能所提出的任何想法,例如隔离指令和数据缓存、片上二级缓存、deep pipelines 以及同时获取和执行多条指令等,都可以集成到 x86 中。在 2011 年 PC 时代的巅峰时期,AMD 和英特尔每年大约出货 3.5 亿台 x86 微处理器。PC 行业的高产量和低利润率也意味着价格低于 RISC 计算机。
考虑到全球每年售出数亿台个人电脑,PC 软件成为了一个巨大的市场。尽管 Unix 市场的软件供应商会为不同的商业 RISC ISA (Alpha、HP-PA、MIPS、Power 和 SPARC) 提供不同的软件版本,但 PC 市场只有一个 ISA,因此软件开发人员发布的 “压缩打包” 软件只能与 x86 ISA 兼容。更大的软件基础、相似的性能和更低的价格使得 x86 在 2000 年之前同时统治了台式机和小型服务器市场。
Apple 公司在 2007 年推出了 iPhone,开创了后 PC 时代。智能手机公司不再购买微处理器,而是使用其他公司的设计 (包括 ARM 的 RISC 处理器),在芯片上构建自己的系统 (SoC)。移动设备的设计者不仅重视性能,而且重视晶格面积和能源效率,这对 CISC ISA 不利。此外,物联网的到来大大增加了处理器的数量,以及在晶格大小、功率、成本和性能方面所需的权衡。这种趋势增加了设计时间和成本的重要性,进一步不利于 CISC 处理器。在今天的后 PC 时代,x86 的出货量自 2011 年达到峰值以来每年下降近 10%,而采用 RISC 处理器的芯片的出货量则飙升至 200 亿。今天,99% 的 32 位和 64 位处理器都是 RISC。
总结上面的历史回顾,我们可以说市场已经解决了 RISC-CISC 的争论;CISC 赢得了 PC 时代的后期阶段,但 RISC 正在赢得整个后 PC 时代。几十年来,没有出现新的 CISC ISA。令我们吃惊的是,今天在通用处理器的最佳 ISA 原则方面的共识仍然是 RISC,尽管距离它们的推出已经过去 35 年了。
处理器架构当前的挑战
虽然上一节的重点是指令集体系结构 (ISA) 的设计,但大多数计算机架构师并不设计新的 ISA,而是在当前的实现技术中实现现有的 ISA。自 20 世纪 70 年代末以来,技术的选择一直是基于金属氧化物半导体 (MOS) 的集成电路,首先是 n 型金属氧化物半导体 (nMOS),然后是互补金属氧化物半导体 (CMOS)。MOS 技术惊人的改进速度 (Gordon Moore 的预测中已经提到这一点) 已经成为驱动因素,使架构师能够设计更积极的方法来实现给定 ISA 的性能。摩尔在 1965 年的最初预测要求晶体管密度每年翻一番;1975 年,他对其进行了修订,预计每两年翻一番。这最终被称为摩尔定律。由于晶体管密度呈二次增长,而速度呈线性增长,架构师们使用了更多的晶体管来提高性能。
摩尔定律和 Dennard Scaling 的终结
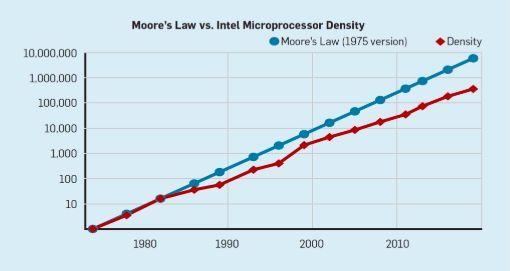
尽管摩尔定律已经存在了几十年,但它在 2000 年左右开始放缓,到 2018 年,摩尔的预测与目前的能力之间的差距大约是 15 倍。目前的预期是,随着 CMOS 技术接近基本极限,差距将继续扩大。
- 图2:每片英特尔微处理器的晶体管与摩尔定律的差别
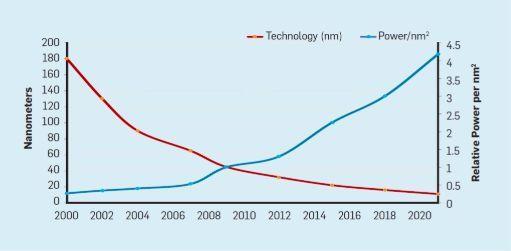
与摩尔定律相伴而来的是罗伯特·登纳德 (Robert Dennard) 的预测,称为 “登纳德缩放比例” (Dennard Scaling)。该定律指出,随着晶体管密度的增加,每个晶体管的功耗会下降,因此每平方毫米硅的功耗几乎是恒定的。由于硅的计算能力随着每一代新技术的发展而提高,计算机将变得更加节能。Dennard Scaling 在 2007 年开始显著放缓,到 2012 年几乎变为零 (见图3)。
- 图3:Transistors per chip and power per mm2.
在 1986 年到 2002 年之间,指令级并行 (ILP) 的开发是提高性能的主要架构方法,并且随着晶体管速度的提高,每年的性能增长大约 50%。Dennard Scaling 的结束意味着架构师必须找到更有效的方法来利用并行性。
要理解为什么 ILP 的增加会导致更大的效率低下,可以考虑一个像 ARM、Intel 和 AMD 这样的现代处理器核心。假设它有一个 15-stage 的 pipeline,每个时钟周期可以发出四条指令。因此,它在任何时刻都有多达 60 条指令在 pipeline 中,包括大约 15 个分支,因为它们代表了大约 25% 的执行指令。为了使 pipeline 保持完整,需要预测分支,并推测地将代码放入 pipeline 中以便执行。投机性的使用是 ILP 性能和效率低下的根源。当分支预测完美时,推测可以提高性能,但几乎不需要额外的能源成本 —— 甚至可以节省能源 —— 但是当它 “错误地预测” 分支时,处理器必须扔掉错误推测的指令,它们的计算工作和能量就被浪费了。处理器的内部状态也必须恢复到错误预测分支之前的状态,这将花费额外的时间和精力。
要了解这种设计的挑战性,请考虑正确预测 15 个分支的结果的难度。如果处理器架构师希望将浪费的工作限制在 10% 的时间内,那么处理器必须在 99.3% 的时间内正确预测每个分支。很少有通用程序具有能够如此准确预测的分支。
为了理解这些浪费的工作是如何累加起来的,请考虑下图中的数据,其中显示了有效执行但由于处理器的错误推测而被浪费的指令的部分。在 Intel Core i7 上,这些基准测试平均浪费了 19% 的指令。
- 图4
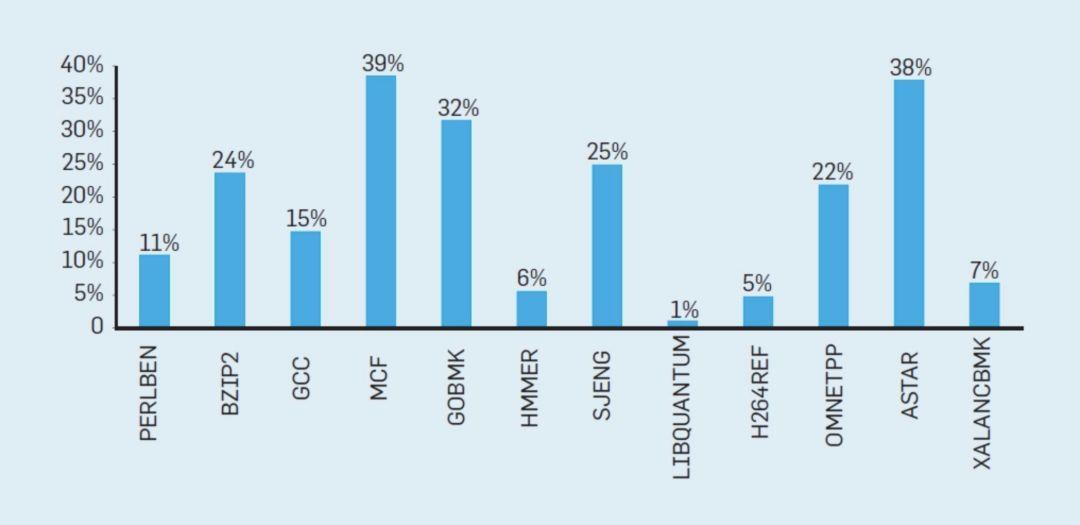
但是,浪费的能量更大,因为处理器在推测错误时必须使用额外的能量来恢复状态。这样的度量导致许多人得出结论,架构师需要一种不同的方法来实现性能改进。多核时代就这样诞生了。
多核将识别并行性和决定如何利用并行性的责任转移给程序员和语言系统。多核并不能解决由于登纳德缩放比例定律结束而加剧的节能计算的挑战。无论有源堆芯对计算的贡献是否有效,有源堆芯都会消耗能量。
一个主要的障碍是 Amdahl 定律,它指出并行计算机的加速受到连续计算部分的限制。 为了理解这一观察的重要性,请考虑下图,其中显示了假设串行执行的不同部分 (其中只有一个处理器处于活动状态),在最多 64 个内核的情况下,应用程序的运行速度要比单个内核快得多。例如,当只有 1% 的时间是串行的,64 处理器配置的加速大约是 35。不幸的是,所需的功率与 64 个处理器成正比,因此大约 45% 的能量被浪费了。
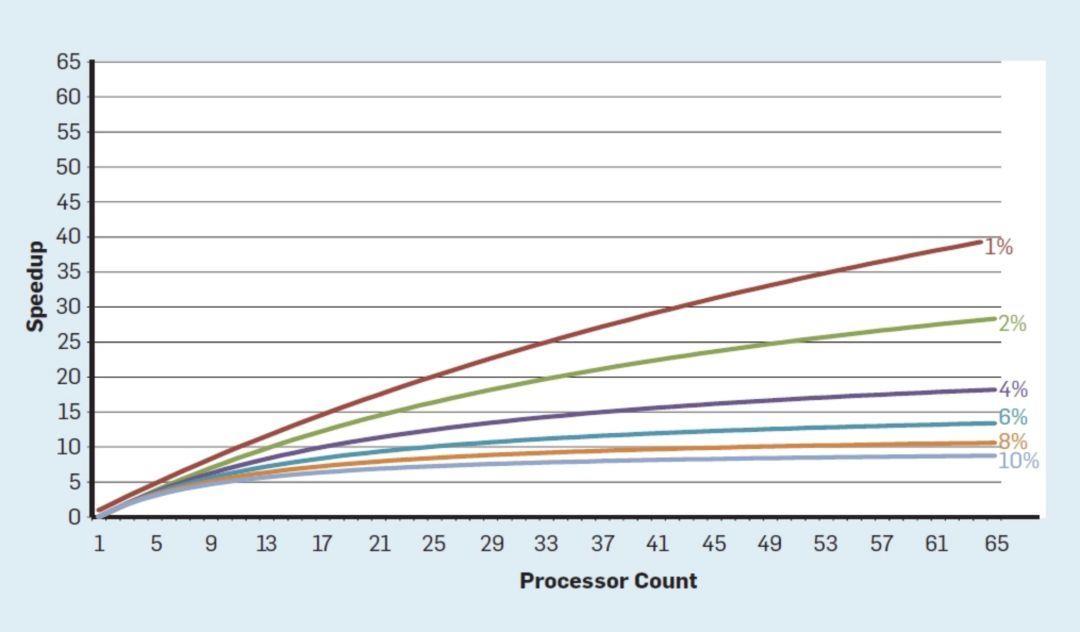
当然,真正的程序有更复杂的结构,其中部分允许在任何给定的时间点使用不同数量的处理器。尽管如此,定期通信和同步的需求意味着大多数应用程序的某些部分只能有效地使用一部分处理器。尽管 Amdahl 定律已有 50 多年的历史,但它仍然是一个困难的障碍。
随着 Dennards Scaling 定律的结束,芯片上内核数量的增加意味着功率也在以几乎相同的速度增长。不幸的是,进入处理器的能量也必须以热量的形式被移除。因此,多核处理器受到热耗散功率 (TDP) 的限制,即封装和冷却系统可以移除的平均功率。虽然一些高端数据中心可能会使用更先进的软件包和冷却技术,但没有电脑用户愿意在办公桌上安装一个小型热交换器,或者在背上安装散热器来冷却手机。TDP 的限制直接导致了 “暗硅” 时代,处理器会降低时钟速率,关闭空闲内核以防止过热。另一种看待这种方法的方法是,一些芯片可以重新分配他们宝贵的权力,从空闲的核心到活跃的。
一个没有 Dennards Scaling,摩尔定律减速、Amdahl 法则完全有效的时代,意味着低效率限制了性能的提升,每年只有几个百分点的提升(见图 6)。实现更高的性能改进需要新的架构方法,更有效地使用集成电路功能。在讨论了现代计算机的另一个主要缺点后,我们将回到可能起作用的方法上来。
- 图6
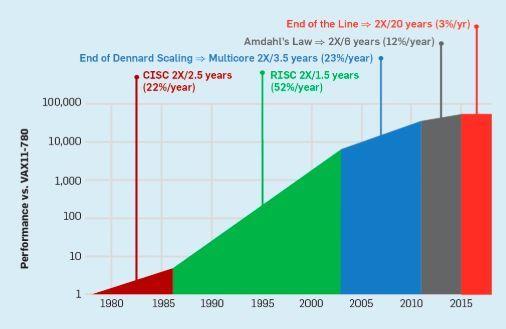
被忽视的安全问题
20 世纪 70 年代,处理器架构师将重点放在通过保护环等概念来增强计算机安全性上。这些架构师充分认识到大多数错误将出现在软件中,但是他们相信架构支持可以提供帮助。这些特性在很大程度上没有被操作系统所采用,这些操作系统被有意地集中在所谓的良性环境中(比如个人电脑),并且成本很高,所以很快被放弃了。在软件社区中,许多人认为正式验证机制和微内核这样的技术,将为构建高度安全的软件提供有效的机制。遗憾的是,规模化软件系统和对性能的追求,使得这些技术无法跟上处理器的性能。其结果是,大型软件系统仍然存在许多安全缺陷,由于在线个人信息的大量增加,以及云计算的大规模应用,这种缺陷的影响被进一步放大了。
尽管计算机架构师们安全性的重要意识方面进展缓慢,但他们也已经开始为虚拟机和加密硬件提供安全支持。遗憾的是,这也可能为不少处理器带来了一个未知、但重要的安全缺陷。尤其是,Meltdown 和 Spectre 安全缺陷导致了新的漏洞,这些漏洞会利用微架构中的漏洞,使得本来受保护的信息迅速泄露。Meltdown 和 Spectre 使用所谓的侧通道攻击(Side-channel attacks),通过观察任务所需时间,将 ISA 级别上不可见的信息转换为时间上可见的属性,从而泄露信息。
2018 年,研究人员展示了如何利用 Spectre 的变种在网络上泄露信息,而攻击者并不需要将代码加载到目标处理器上。尽管这种被称为 NetSpectre 的攻击泄漏信息速度很慢,但它可以让同一局域网 (或云中的同一集群) 上的任何机器受到攻击,这又产生了许多新的漏洞。随后有报告称发现了虚拟机体系结构中的另外两个漏洞。其中一种被称为 “预见” (hadow),可以渗透英特尔旨在保护高风险数据 (如加密密钥) 的安全机制。此后每月都有新的漏洞被发现。
侧通道攻击并不新鲜,但在早期,软件缺陷导致这种攻击往往能够成功。在 Meltdown 和 Spectre 和其他攻击中,导致受保护信息泄露的是硬件实现中的一个缺陷。处理器架构师在如何定义 ISA 的正确实现上存在基本的困难,因为标准定义中并没有说明执行指令序列对性能的影响,只是说明了执行指令的 ISA 可见的体系结构状态。处理器架构师们需要重新考虑 ISA 的正确实现的定义,以防范此类安全缺陷。同时,架构师们应该重新考虑他们对计算机安全性的关注程度,以及如何与软件设计人员合作来打造更安全的系统。从目前来看,架构师过于依赖于信息系统,并不愿意将安全性问题视为设计时的首要关注焦点。
计算机体系结构新机遇
“我们面前的一些令人叹为观止的机会被伪装成不可解决的问题。” —— John Gardner,1965年
通用处理器固有的低效率,无论是由 ILP 技术还是多核所致,加上登纳德缩放定律 (Dennard Scaling) 和摩尔定律的终结,使我们认为处理器架构师和设计人员在一般情况下难以继续保持通用处理器性能实现显著的提升。而鉴于提高处理器性能以实现新的软件功能的重要性,我们必须要问:还有哪些其他可行的方法?
有两个很清楚的机会,以及将两者结合起来所创造出的第三个机会。首先,现有的软件构建技术广泛使用具有动态类型和存储管理的高级语言。不幸的是,这些语言的可解释性和执行效率往往非常低。Leiserson 等人用矩阵乘法运算为例来说明这种低效率。如图7所示,简单地把动态高级语言 Python 重写为 C 语言代码,将性能提高了 47 倍。使用多核并行循环处理将性能提升了大约 7 倍。优化内存布局提高缓存利用率,将性能提升了 20 倍,最后,使用硬件扩展来执行单指令多数据(SIMD)并行操作每条指令能够执行 16 个 32 位操作,让性能提高了 9 倍。总而言之,与原始 Python 版本相比,最终的高度优化版在多核英特尔处理器上的运行速度提高了 62,000 倍。这当然只是一个小的例子,程序员应该使用优化后的代码库。虽然它夸大了通常的性能差距,但有许多软件都可以实现这样性能 100 倍到 1000 倍的提升。
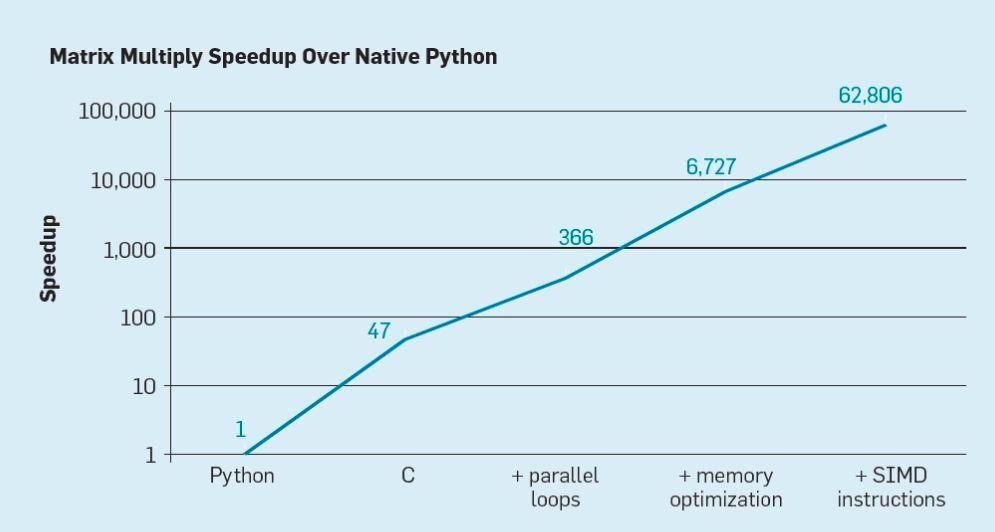
一个有趣的研究方向是关于是否可以使用新的编译器技术来缩小某些性能差距,这可能有助于体系结构的增强。尽管高效编译和实现 Python 等高级脚本语言的难度很大,但潜在的收益也是巨大的。哪怕编译性能提升 25% 的潜在收益都可能使 Python 程序运行速度提高数十乃至数百倍。这个简单的例子说明了在注重程序员效率的现代语言与传统方法之间有多大的差距。
领域特定结构 (DSA)
DSA 是一个更加以硬件为中心的方法,是设计针对特定问题域定制的体系结构,并为该领域提供显著的性能(和能效)增益,这也被称之为 “领域特定结构”(DSA),是一种为特定领域可编程且通常是图灵完整的,但针对特定应用程序类别进行了定制。从这个意义上说,DSA 与专用集成电路(ASIC)不同,后者通常用于单一功能,代码很少发生变化。DSA 通常称为加速器,因为与在通用 CPU 上执行整个应用程序相比,它们只会加速某些应用程序。此外,DSA 可以实现更好的性能,因为它们更贴近应用程序的需求;DSA 的例子包括图形处理单元(GPU),用于深度学习的神经网络处理器和用于软件定义网络(SDN)的处理器。
DSA 可以实现更好的性能和更高的能效,主要有以下四个原因:
-
首先也是最重要的一点,DSA 利用了特定领域中更有效的并行形式。例如,单指令多数据并行(SIMD)比多指令多数据(MIMD)更有效,因为它只需要获取一个指令流并且处理单元以锁步操作。虽然 SIMD 不如 MIMD 灵活,但它很适合许多 DSA。DSA 也可以使用 VLIW 方法来实现 ILP,而不是推测性的无序机制。如前所述,VLIW 处理器与通用代码不匹配,但由于控制机制更简单,因此对于数量有限的几个领域更为有效。特别是,大多数高端通用处理器都是乱序超标量执行,需要复杂的控制逻辑来启动和完成指令。相反,VLIW 在编译时会进行必要的分析和调度,这非常适用于运行显式并行程序。
-
其次,DSA 可以更高效地利用内存层次结构。正如 Horowitz 所指出的,内存访问比加减计算成本要高得多。例如,访问 32K 字节缓存块所需的能量成本比 32 位整数相加高约 200 倍。这种巨大的差异使得优化存储器访问对于实现高能效至关重要。通用处理器在运行代码的时候,存储器访问往往表现出空间和时间局部性,但这在编译时非常难以预测。因此,CPU 使用多级高速缓存来增加带宽,并隐藏相对较慢的片外 DRAM 的延迟。这些多级高速缓存通常消耗大约一半的处理器能量,但几乎都不需要对片外 DRAM 的所有访问,导致这些访问需要大约 10 倍于最后一级高速缓存访问的能量。
缓存有两大明显缺点:
- 数据集非常大时:当数据集非常大并且时间或空间位置较低时,缓存根本不能很好工作;
- 当缓存工作得很好时:当缓存运行良好时,位置非常高,这意味着,根据定义,大多数缓存大部分时间都处于空闲状态。
在编译时可以很好地定义和发现应用程序中的内存访问模式,这对于典型的 DSL 来说是正确的,程序员和编译器可以比动态分配缓存,更好地优化内存的使用。因此,DSA 通常使用由软件明确控制的动态分层存储器,类似于矢量处理器的操作。对于合适的应用,用户控制的存储器可以比高速缓存消耗更少的能量。
- 第三,DSA 可以适度使用较低的精度。通用 CPU 通常支持 32 位和 64 位整数和浮点(FP)数据。机器学习和图形学中的许多应用不需要计算得这样精确。例如,在深度神经网络(DNN)中,推理通常使用 4 位,8 位或 16 位整数,从而提高数据和计算吞吐量。同样,对于 DNN 训练应用,FP 很有用,但 32 位足够了,一般 16 位就行。
最后,DSA 受益于以领域特定语言(DSL)编写的目标程序,这些程序可以利用更多的并行性,改进内存访问的结构和表示,并使应用程序更有效地映射到特定领域处理器。
领域特定语言(DSL)
DSA 要求将高级运算融入到体系结构里,但尝试从 Python,Java,C 或 Fortran 等通用语言中提取此类结构和信息实在太难了。领域特定语言(DSL)支持这一过程,并能有效地对 DSA 进行编程。例如,DSL 可以使向量、密集矩阵和稀疏矩阵运算显式化,使 DSL 编译器能够有效地将将运算映射到处理器。常见的 DSL 包括矩阵运算语言 Matlab,编程 DNN 的数据流语言 TensorFlow,编程 SDN 的语言 P4,以及用于指定高级变换的图像处理语言 Halide。
使用 DSL 的难点在于如何保持足够的架构独立性,使得在 DSL 中编写的软件可以移植到不同的架构,同时还可以实现将软件映射到底层 DSA 的高效率。例如,XLA 系统将 Tensorflow 编译到使用 Nvidia GPU 和张量处理器单元(TPU)的异构处理器。权衡 DSA 的可移植性以及效率是语言设计人员、编译器创建者和 DSA 架构师面临的一项有趣的研究挑战。
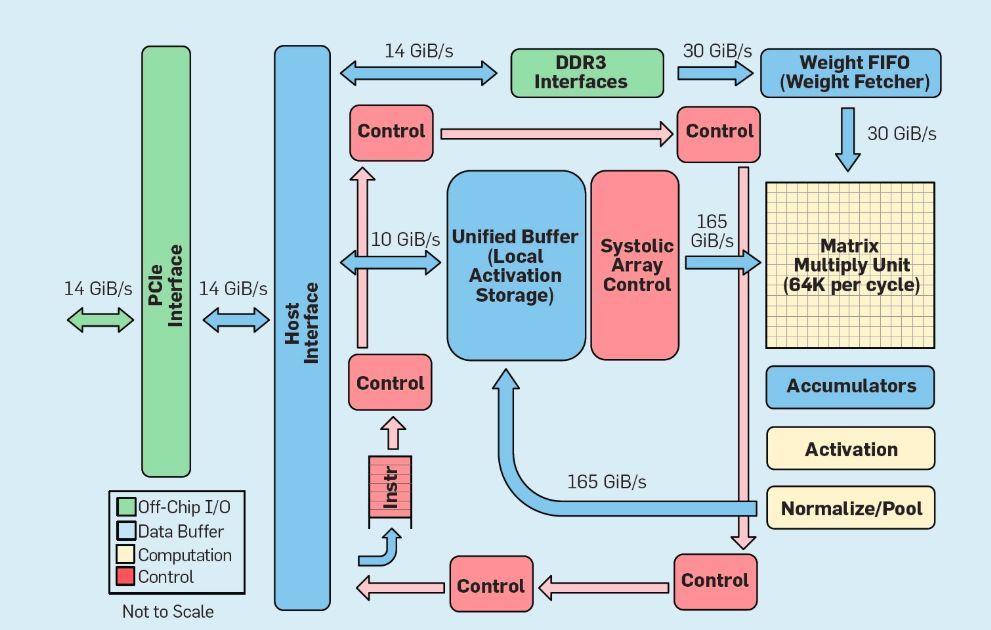
DSA TPU v1。以 Google TPU v1 作为 DSA 的一个例子,Google TPU v1 旨在加速神经网络推理。TPU 自 2015 年开始投入生产,应用范围从搜索查询到语言翻译再到图像识别,再到 DeepMind 的围棋程序 AlphaGo 和通用棋类程序 AlphaZero,其目标是将深度神经网络推理的性能和能效提高 10 倍。
如图8所示,TPU 的组织架构与通用处理器完全不同。
总结
我们考虑了两种不同的方法,通过提高硬件技术的使用效率来提高程序运行性能:首先,通过提高现代高级语言的编译性能;其次,通过构建领域特定体系结构,可以大大提高性能和效率。DSL 是另一个如何改进支持 DSA 等架构创新的硬件/软件接口的例子。通过这些方法获得显著性能提升。在行业横向结构化之前,需要在跨抽象层次上垂直集成并做出设计决策,这是计算机早期工作的主要特征。在这个新时代,垂直整合变得更加重要,能够核查和进行复杂权衡及优化的团队将会受益。
这个机会已经引发了架构创新的激增,吸引了许多竞争性的架构理念:
- Nvidia GPU 使用许多内核,每个内核都有大型寄存器文件,许多硬件线程和缓存;
- Google TPU 依赖于大型二维收缩倍增器和软件控制的片上存储器;
- FPGA,微软在其数据中心部署了现场可编程门阵列(FPGA),它可以根据神经网络应用进行定制;
- CPU,英特尔提供的 CPU 具有许多内核,这些内核通过大型多级缓存和一维 SIMD 指令(微软使用的 FPGA)以及更接近 TPU 而不是 CPU 的新型神经网络处理器得到增强。
除了这些大型企业外,还有数十家创业公司正在寻求自己的路径。为了满足不断增长的需求,体系结构设计师正在将数百到数千个此类芯片互连,形成神经网络超级计算机。
DNN 架构的这种雪崩使计算机架构变得有趣。在 2019 年很难预测这些方向中哪些(或者即使有)会赢,但市场肯定会最终解决技术以及架构争议。
开放式架构
受开源软件成功的启发,计算机体系结构中的第二个机遇是开源的 ISA。要创建一个 “面向处理器的 Linux”,该领域需要行业标准的开源 ISA,这样社区就可以创建开源内核 (除了拥有专有内核的个别公司之外)。如果许多组织使用相同的 ISA 设计处理器,那么更大的竞争可能会推动更快的创新。目标是为芯片提供处理器,成本从几美分到 100 美元不等。
第一个例子是 RISC-V(称为 “RISC Five”),这是加州大学伯克利分校开发的第五个 RISC 架构。RISC-V 的社区在 RISC-V 基金会 (http://riscv.org/) 的管理下维护体系结构。开源允许 ISA 在公开的场景下发生演变,在决策最终确定之前,由硬件和软件专家进行协作。
RISC-V 是一个模块化的指令集。一小部分指令运行完整的开源软件栈,然后是可选的标准扩展设计器,设计人员可以根据需求包含或省略这些扩展。这个基础包括 32 位和 64 位版本。RISC-V 只能通过可选扩展来发展;即使架构师不接受新的扩展,软件堆栈仍可以很好的运行。
专有架构通常需要向上的二进制兼容性,这意味着当处理器公司添加新特性时,所有在此之后的处理器也必须包含这些新特性。而 RISC-V 则不是如此,所有增强功能都是可选的,如果应用程序不需要,可以删除。以下是迄今为止的标准扩展名,使用的是代表其全名的缩写:
- M. Integer multiply/divide;
- A. Atomic memory operations;
- F/D. Single/double-precision floating-point;
- C. Compressed instructions。
RISC-V 的第三个显著特征是 ISA 的简单性。虽然难以量化,但这里有两个与 ARM 公司同期开发的 ARMv8 架构的比较:
更少的指令。RISC-V 的指令要少得多。在基础版本中只有 50 个,在数量和性质上与最初的 RIS-i 惊人地相似。剩下的标准扩展 (M,A,F 和 D) 添加了 53 条指令,再加上 C 又增加了 34 条,共计 137 条。而 ARMv8 有 500 多条。
更少的指令格式。 RISC-V 的指令格式少了六个,而 ARMv8 至少有 14 个。
简单性减少了设计处理器和验证硬件正确性的工作量。 由于 RISC-V 的目标范围从数据中心芯片到物联网设备,因此设计验证可能是开发成本的重要组成部分。
第四,RISC-V 是一个全新的设计。与第一代 RISC 架构不同,它避免了微架构或依赖技术的特性 (如延迟分支和延迟加载),也避免了被编译器技术的进步所取代的创新 (如注册窗口)。
最后,RISC-V 通过为自定义加速器保留大量的操作码空间来支持 DSA。
除了 RISC-V 之外,英伟达还 (在 2017 年) 宣布了一种名为 NVDLA 的免费开放架构,这是一种可伸缩、可配置的机器学习推断 DSA。配置选项包括数据类型 (int8、int16 或 fp16) 和二维乘法矩阵的大小。模具尺寸从 0.5 mm2 到 3 mm2 不等,功率从 20 毫瓦到 300 毫瓦不等。 ISA、软件堆栈和实现都是开放的。
开放的简单体系结构与安全性是协同的。
首先,安全专家不相信通过 “隐藏” 实现的安全性,因此实现开源很有吸引力,而开源的实现需要开放的体系结构。
同样重要的是,增加能够围绕安全架构进行创新的人员和组织的数量。专有架构限制了员工的参与,但是开放架构允许学术界和业界所有最优秀的“头脑”来帮助共同实现安全性。
最后,RISC-V 的简单性使得它的实现更容易检查。
此外,开放的架构、实现和软件栈,加上 FPGA 的可塑性,意味着架构师可以在线部署和评估新的解决方案,并每周迭代它们,而不是每年迭代一次。虽然 FPGA 比定制芯片慢 10倍 ,但这种性能仍然足以支持在线用户。
我们希望开放式架构成为架构师和安全专家进行硬件/软件协同设计的典范。
轻量级硬件开发
由 Beck 等人撰写的《轻量级软件开发》(The Manifesto for Agile Software Development,2011) 彻底改变了软件开发方式,克服了瀑布式开发中传统的详细计划和文档的频繁失败。小型编程团队在开始下一次迭代之前快速开发工作原型 (但不完整) 并获得了客户反馈。轻量级开发的 scrum 版本汇集了 5 到 10 个程序员的团队,每次迭代执行需两到四周的冲刺。
再次受到软件成功的启发,第三个机遇是轻量级硬件开发。对于架构师来说,好消息是现代电子计算机辅助设计 (ECAD )工具提高了抽象级别,从而支持轻量级开发,而这种更高的抽象级别增加了设计之间的重用。
但从设计芯片到得到用户反馈的几个月之间,像轻量级软件开发那样申请 “硬件四周的冲刺” 似乎是不合理的。
下图概述了轻量级开发方法如何通过在适当的级别上更改原型来工作。
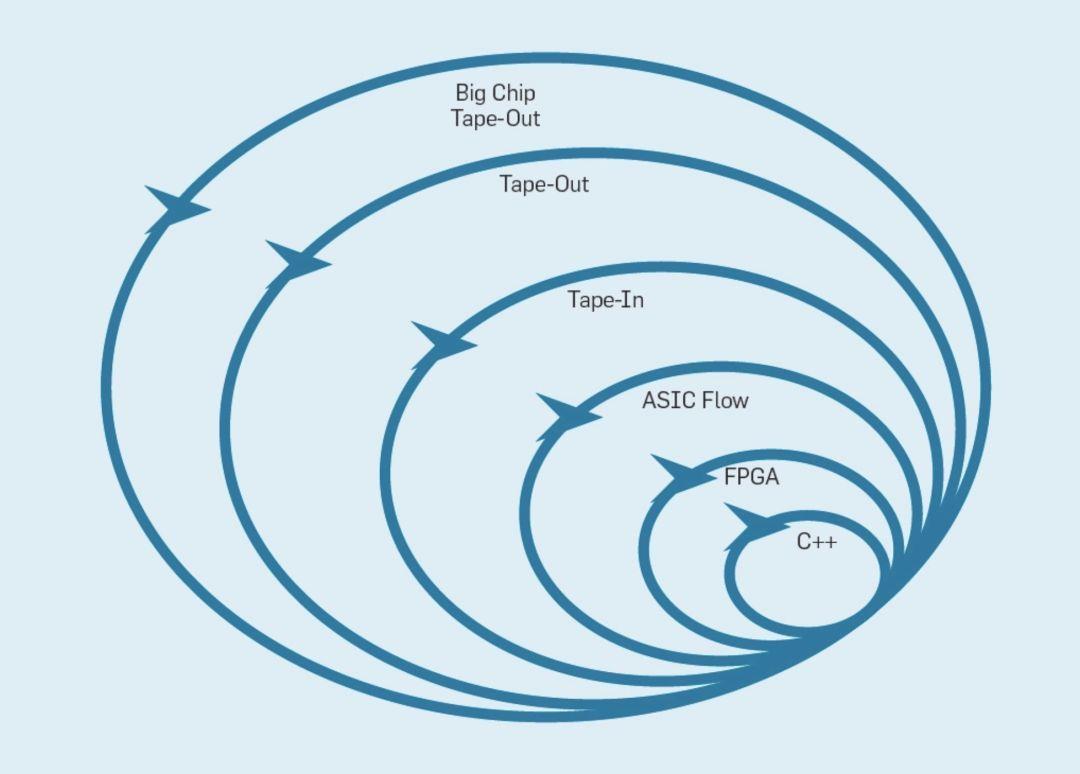
- 最内层是一个软件模拟器,如果模拟器能够满足迭代,那么这一环节是进行更改最容易和最快的地方。
- 下一级是 FPGA,它的运行速度比一个详细的软件模拟器快数百倍。FPGA 可以运行像 SPEC 那样的操作系统和完整的基准测试,从而可以对原型进行更精确的评估。Amazon Web Services 在云中提供 FPGA,因此架构师可以使用 FPGA,而不需要先购买硬件并建立实验室。
- 为了记录芯片面积和功率的数字,下一个外层使用 ECAD 工具生成芯片的布局。
- 即使在工具运行之后,在准备生产新的处理器之前,仍然需要一些手动步骤来细化结果。处理器设计人员将此级别称为 “Tape-In”。
前四个级别都支持为期四周的冲刺。
出于研究目的,当面积、能量和性能评估是非常准确的时候,我们可以停在 Tape-In 这个级别上。然而,这就像跑一场长跑,在终点前 100 码停了下来,尽管在比赛前做了大量的准备工作,运动员还是会错过真正跨越终点线的兴奋和满足。硬件工程师与软件工程师相比,其中一个优势是他们可以构建物理的东西。让芯片重新测量、运行真实的程序并显示给朋友和家人,这是硬件设计的一大乐趣。
许多研究人员认为他们必须在此环节停下来,因为制造一个芯片的成本着实太高了。当设计规模较小的时候,它们出奇的便宜:只需 14,000 美元即可订购 100 个 1-mm2 芯片。在 28nm 的规格下,1 mm2 的面积包含数百万个晶体管,足够容纳一个 RISC-V 处理器和一个 NVLDA 加速器。如果设计者的目标是构建一个大型芯片,那么最外层的成本是极其昂贵的,但是架构师可以用小型芯片演示许多新颖的想法。
总结
“黎明前最黑暗。”
——托马斯·富勒,1650
为了从历史的教训中获益,架构师必须意识到软件创新也可以激发架构师的兴趣,提高硬件/软件界面的抽象层次可以带来创新机会,并且市场最终会解决计算机架构的争论。iAPX-432 和 Itanium 说明了架构投资如何超过回报,而 S/360,8086 和 ARM 提供了长达数十年的高年度回报,并且看不到尽头。
登纳德缩放比例定律和摩尔定律的终结,以及标准微处理器性能增长的减速,这些都不是必须解决的问题,而是公认的事实,并且提供了让人惊叹的机遇。
高级、特定于领域的语言和体系结构,将架构师从专有指令集的链中解放出来,以及公众对改进安全性的需求,将为计算机架构师带来一个新的黄金时代。
在开源生态系统的帮助下,轻量级开发的芯片将会令人信服,从而加速商业应用。这些芯片中通用处理器的 ISA 理念很可能是 RISC,它经受住了时间的考验。可以期待与上一个黄金时代相同的快速改善,但这一次是在成本、能源、安全以及性能方面。
下一个十年将会是一个全新计算机架构的 “寒武纪” 大爆发,这意味着计算机架构师在学术界和工业界将迎来一个激动人心的时代。
以上是关于计算机体系结构的新黄金时代的主要内容,如果未能解决你的问题,请参考以下文章