强化学习笔记:随机高斯策略
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了强化学习笔记:随机高斯策略相关的知识,希望对你有一定的参考价值。
1 自由度是1的情况
- 自由度是1,也就是说动作a是实数,动作空间A是实数集R的一个子集。
- 我们记动作的均值为μ(s),标准差为σ(s),于是我们可以用正态分布的概率密度函数作为策略函数:
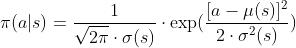
- 假如我们知道函数μ(s)和σ(s)的解析式,那么我们可以用以下几步做控制(做控制——找agent需要执行的动作a):
- 观测到当前状态s,预测均值
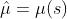 ,标准差
,标准差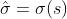
- 从正态分布中做随机抽样:
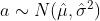
- 智能体执行动作a
- 观测到当前状态s,预测均值
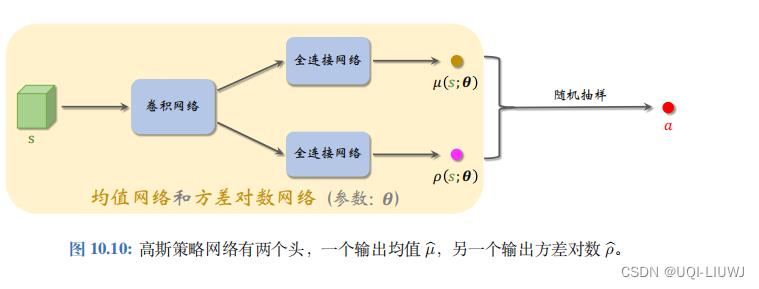
- 一个很自然的想法,就是用神经网络来近似μ(s)和σ(s)
- 在实践中,我们不是直接近似标准差σ,而是近似方差对数
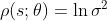
- 在实践中,我们不是直接近似标准差σ,而是近似方差对数
在均值网络和方差对数网络下,我们的策略网络为:
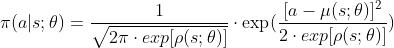
2 随机高斯策略网络
假设动作是d维向量,那么此时μ(s;θ)和ρ(s;θ)都是d维向量。
用标量
表示动作向量a的第i个元素。
分别表示μ(s;θ)和ρ(s;θ)的第i个元素。
此时我们用多元正态分布的概率密度函数作为策略网络:
——>做控制的时候,只需要μ(s;θ)和ρ(s;θ)即可
做训练的时候,我们需要引入辅助网络f(s,a;θ)
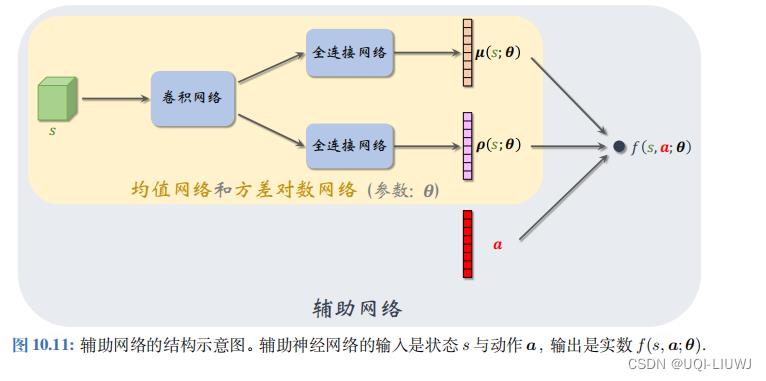
它的具体定义如下
(它的 可训练参数都是μ(s;θ)和ρ(s;θ)中的参数)
把
代入,不难发现:
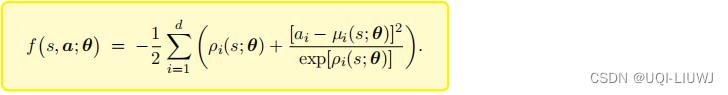

2.1 训练过程
在强化学习笔记:policy learning_UQI-LIUWJ的博客-CSDN博客我们知道
将10.3代入,于是有:


所以训练过程如下:
- 搭建均值网络 µ ( s ; θ ) 、方差对数网络 ρ ( s ; θ ) 、辅助网络 f ( s, a ; θ ) 。
-
让智能体与环境交互,记录每一步的状态、动作、奖励,并对参数
θ
做更新:
-
观测到当前状态 s,计算均值、方差对数、方差
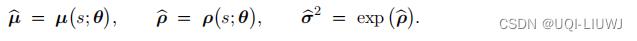
-

-

-
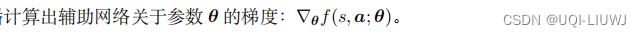
-
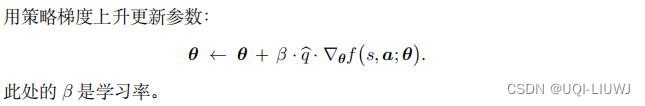
-
观测到当前状态 s,计算均值、方差对数、方差
和 强化学习笔记:policy learning_UQI-LIUWJ的博客-CSDN博客问题一样,如何近似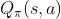 是一个问题,同样地,我们可以用REINFORCE和Actor-critic
是一个问题,同样地,我们可以用REINFORCE和Actor-critic
 开发者涨薪指南
开发者涨薪指南
 48位大咖的思考法则、工作方式、逻辑体系
48位大咖的思考法则、工作方式、逻辑体系
以上是关于强化学习笔记:随机高斯策略的主要内容,如果未能解决你的问题,请参考以下文章