机器学习——K-means(聚类)与人脸识别
Posted @李忆如
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习——K-means(聚类)与人脸识别相关的知识,希望对你有一定的参考价值。
目录
系列文章目录
本系列博客重点在机器学习的概念原理与代码实践,不包含繁琐的数学推导(有问题欢迎在评论区讨论指出,或直接私信联系我)。
第一章 机器学习——PCA(主成分分析)与人脸识别_@李忆如的博客-CSDN博客
第二章 机器学习——LDA (线性判别分析) 与人脸识别_@李忆如的博客-CSDN博客
第三章 机器学习——LR(线性回归)、LRC(线性回归分类)与人脸识别_@李忆如的博客
第四章 机器学习——SVM(支持向量机)与人脸识别_@李忆如的博客
第五章 机器学习——K-means(聚类) 与人脸识别
梗概
本篇博客主要介绍K-means(聚类)算法,包括算法原理、流程、分析,利用经典K-means实现简单聚类及可视化,并利用K-means及其优化实现人脸识别及其可视化(内附数据集与matlab代码)
一、K-means聚类算法的原理、过程与分析
1.K-means算法原理
K-means是一种无监督的学习,主要通过不断地取离种子点(质心)最近均值的数据,自动将相似的对象归到同一个簇中(共聚类k个簇),常用于聚类分析。K-means中所用最重要方法即求点群中心的算法:即欧氏距离,公式(以n维数据为例)如下:
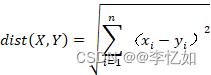
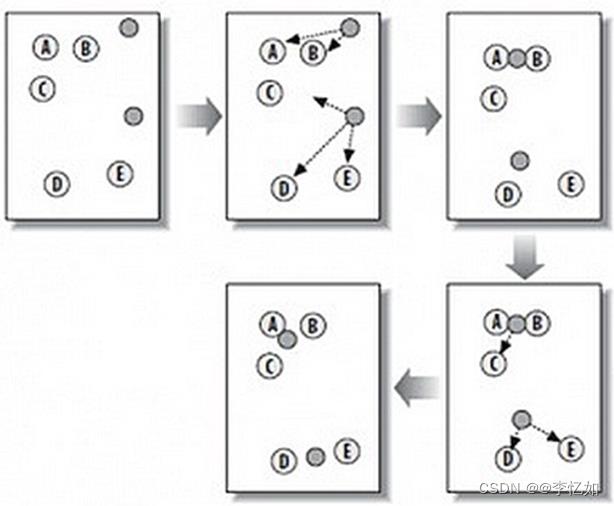
K-Means算法的简单示例(K=2)如下图:
2.K-means算法流程
1.随机选择数据集中 k 个样本作为初始聚类中心α=α1,α2,……,αk;
2.针对数据集中每个样本xi,计算它到 k 个聚类中心的距离并将其分到距离最小的聚类中心所对应的类中;
3.针对每个类别aj,重新计算它的聚类中心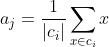 (即属于该类的所有样本的质心);
(即属于该类的所有样本的质心);
4.重复上面2,3两步操作,直到达到某个中止条件(最大迭代次数、最小误差变化(质心的位置变化小于指定的阈值(默认为 0.0001))等),以此确定最优的聚类中心。
3.K-means算法分析
1.优点
① 算法简单,容易理解,聚类效果不错
② 处理大数据集的时候,该算法可以保证较好的伸缩性
③ 当簇近似高斯分布的时候,效果相对较好
2.缺点
① K值需要人为设定,不同 K 值对实验结果影响较大
② 对初始的簇中心敏感,不同选取方式对实验结果影响较大
③ 对异常值敏感
④ 每个样本只能归为一类,不适合多分类任务
⑤ 不适合太离散的分类、样本类别不平衡的分类、非凸形状的分类
二、K-means聚类的简单实践及可视化
① 问题描述:为更熟练掌握K-means聚类算法与结果的展示,做一个2维或三维空间中的2~3类点(每个类有10个点)聚类实验,把聚类结果用不同的颜色与符号表示。
② 算法实现核心:首先利用mvnrnd函数生成3组满足高斯分布的数据(聚类效果相对较好),再按1.2中的K-means算法流程(或调库)对生成k个蔟质心进行迭代确定,实现聚类。
③ 手敲代码如下(也可调库实现):
clear;
clc;
times = 0;
N = input('请设置聚类数目:');%设置聚类数目
%% 第一组数据
mu1=[0 0]; %均值
S1=[0.1 0 ; 0 0.1]; %协方差
data1=mvnrnd(mu1,S1,10); %产生高斯分布数据
%% 第二组数据
mu2=[-1.25 1.25];
S2=[0.1 0 ; 0 0.1];
data2=mvnrnd(mu2,S2,10);
%% 第三组数据
mu3=[1.25 1.25];
S3=[0.1 0 ; 0 0.1];
data3=mvnrnd(mu3,S3,10);
%% 显示数据
plot(data1(:,1),data1(:,2),'b+');
hold on;
plot(data2(:,1),data2(:,2),'b+');
plot(data3(:,1),data3(:,2),'b+');
%% 初始化工作
data = [data1;data2;data3];
[m,n] = size(data); % m = 30,n = 2
center = zeros(N,n);% 初始化聚类中心,生成N行n列的零矩阵
pattern = data; % 将整个数据拷贝到pattern矩阵中
%% 算法
for x = 1 : N
center(x,:) = data(randi(3,1),:); % 第一次随机产生聚类中心 randi返回1*1的(1,300)的数
end
while true
distence = zeros(1,N); % 产生1行N列的零矩阵
num = zeros(1,N); % 产生1行N列的零矩阵
new_center = zeros(N,n); % 产生N行n列的零矩阵
%% 将所有的点打上标签1 2 3...N
for x = 1 : m
for y = 1 : N
distence(y) = norm(data(x,:) - center(y,:)); % norm函数计算到每个类的距离
end
[~,temp] = min(distence); %求最小的距离 ~是距离值,temp是第几个
pattern(x,n + 1) = temp;
end
times = times+1;
k = 0;
%% 将所有在同一类里的点坐标全部相加,计算新的中心坐标
for y = 1 : N
for x = 1 : m
if pattern(x,n + 1) == y
new_center(y,:) = new_center(y,:) + pattern(x,1:n);
num(y) = num(y) + 1;
end
end
new_center(y,:) = new_center(y,:) / num(y);
if norm(new_center(y,:) - center(y,:)) < 0.0001 %设定最小误差变化(阈值)
k = k + 1;
end
end
if k == N || times > 10000 % 设置终止条件(加入最大迭代次数限制)
break;
else
center = new_center;
end
end
[m, n] = size(pattern); %[m,n] = [30,3]
%% 最后显示聚类后的数据
figure;
hold on;
for i = 1 : m
if pattern(i,n) == 1
plot(pattern(i,1),pattern(i,2),'r*');
plot(center(1,1),center(1,2),'ko');
elseif pattern(i,n) == 2
plot(pattern(i,1),pattern(i,2),'g*');
plot(center(2,1),center(2,2),'ko');
elseif pattern(i,n) == 3
plot(pattern(i,1),pattern(i,2),'b*');
plot(center(3,1),center(3,2),'ko');
elseif pattern(i,n) == 4
plot(pattern(i,1),pattern(i,2),'y*');
plot(center(4,1),center(4,2),'ko');
else
plot(pattern(i,1),pattern(i,2),'m*');
plot(center(5,1),center(5,2),'ko');
end
end
④ 使用K-means聚类(终止条件为质心的位置变化小于指定的阈值(0.0001)或迭代次数大于阈值(10000)),K=2与K=3结果如下图所示:
Tips:同色为K-means聚类同簇,原点为最优质心

K=2的聚类前后

K=3的聚类前后
分析:由以上两图可看出,程序按人工设置好的K值进行聚类,效果较好。
三、K-means实现人脸与物体聚类及可视化
问题描述:实现人脸图像(取前2~3个人的人脸图像)与旋转物体(在COIL20数据集中取前2~3个类的图像)聚类实验, 把结果用不同的颜色与符号表示,并把对应的图像放在相应点的旁边,同时列表给出其在不同数据库在不同K时的聚类精度。
1.数据导入
利用imread批量导入人脸或物体数据库,或直接load相应mat文件,并在导入时不断将人脸拉成一个个列向量组成reshaped_faces,并取出2~3类作为待聚类数据,将导入数据抽象成框架,可以匹配不同数据集的导入(本实验框架适配ORL、AR、FERET、COIL20数据集)。
Tips:代码可见本系列第二篇文章(LDA与人脸识别),基本一致。
2.K-means聚类
K = 3; % 设置K-means的K
% K-means训练
test_data = reshaped_faces(:,1:pic_num_of_each * 3);
[idx,center] = kmeans(test_data',K); %idx是分类类别,center是质心集3.LDA降维
代码与本系列第二篇文章(LDA与人脸识别),基本一致,降维方法本实验选择的是伪逆的LDA。
4.降维与可视化
% 降维与可视化
class_num_to_show = 3;
pic_num_in_a_class = pic_num_of_each;
pic_to_show = class_num_to_show * pic_num_in_a_class;
m = 3; % 制定可视化维数
% 取出相应数量特征向量
project_matrix = eigen_vectors(:,1:m);
% 投影
projected_test_data = project_matrix' * (reshaped_faces - all_mean);
projected_test_data = projected_test_data(:,1:pic_to_show);
pattern = projected_test_data';
%可视化
if(m ==2)
figure;
[max_xy,index]=max(pattern); %用于在图像上标记未聚类原类别
for i = 1 : pic_num_of_each * 3
if(i <= pic_num_of_each)
if idx(i,1) == 1
scatter(pattern(i,1),pattern(i,2),'o','r*');
elseif idx(i,1) == 2
scatter(pattern(i,1),pattern(i,2),'o','g*');
elseif idx(i,1) == 3
scatter(pattern(i,1),pattern(i,2),'o','b*');
elseif idx(i,1) == 4
scatter(pattern(i,1),pattern(i,2),'o','y*');
end
elseif(i <= pic_num_of_each * 2)
if idx(i,1) == 1
scatter(pattern(i,1),pattern(i,2),'^','r*');
elseif idx(i,1) == 2
scatter(pattern(i,1),pattern(i,2),'^','g*');
elseif idx(i,1) == 3
scatter(pattern(i,1),pattern(i,2),'^','b*');
elseif idx(i,1) == 4
scatter(pattern(i,1),pattern(i,2),'^','y*');
end
elseif(i <= pic_num_of_each * 3)
if idx(i,1) == 1
scatter(pattern(i,1),pattern(i,2),'x','r*');
elseif idx(i,1) == 2
scatter(pattern(i,1),pattern(i,2),'x','g*');
elseif idx(i,1) == 3
scatter(pattern(i,1),pattern(i,2),'x','b*');
elseif idx(i,1) == 4
scatter(pattern(i,1),pattern(i,2),'x','y*');
end
end
hold on;
end
text(max_xy(1,1)-10,max_xy(1,2),'第一类:o');
text(max_xy(1,1)-10,max_xy(1,2)-15,'第二类:▲');
text(max_xy(1,1)-10,max_xy(1,2)-30,'第三类:x');
end
if(m==3)
figure
[max_xyz,index]=max(pattern); %用于在图像上标记未聚类原类别
for i = 1 :pic_num_of_each * 3
if(i <= pic_num_of_each)
if idx(i,1) == 1
scatter3(pattern(i,1),pattern(i,2),pattern(i,3),'o','r*');
elseif idx(i,1) == 2
scatter3(pattern(i,1),pattern(i,2),pattern(i,3),'o','g*');
elseif idx(i,1) == 3
scatter3(pattern(i,1),pattern(i,2),pattern(i,3),'o','b*');
elseif idx(i,1) == 4
scatter3(pattern(i,1),pattern(i,2),pattern(i,3),'o','y*');
end
elseif(i <= pic_num_of_each * 2)
if idx(i,1) == 1
scatter3(pattern(i,1),pattern(i,2),pattern(i,3),'^','r*');
elseif idx(i,1) == 2
scatter3(pattern(i,1),pattern(i,2),pattern(i,3),'^','g*');
elseif idx(i,1) == 3
scatter3(pattern(i,1),pattern(i,2),pattern(i,3),'^','b*');
elseif idx(i,1) == 4
scatter3(pattern(i,1),pattern(i,2),pattern(i,3),'^','y*');
end
elseif(i <= pic_num_of_each * 3)
if idx(i,1) == 1
scatter3(pattern(i,1),pattern(i,2),pattern(i,3),'x','r*');
elseif idx(i,1) == 2
scatter3(pattern(i,1),pattern(i,2),pattern(i,3),'x','g*');
elseif idx(i,1) == 3
scatter3(pattern(i,1),pattern(i,2),pattern(i,3),'x','b*');
elseif idx(i,1) == 4
scatter3(pattern(i,1),pattern(i,2),pattern(i,3),'x','y*');
end
end
hold on;
end
text(max_xyz(1,1)-10,max_xyz(1,2),max_xyz(1,3),'第一类:o');
text(max_xyz(1,1)-10,max_xyz(1,2)-15,max_xyz(1,3)-15,'第二类:▲');
text(max_xyz(1,1)-10,max_xyz(1,2)-30,max_xyz(1,3)-30,'第三类:x');
end5.结果与分析
本实验所用数据集:人脸(ORL5646、AR5040)、物体(COIL20),代码适用于其他数据集
5.1 可视化结果
对不同数据集使用K-means聚类(K=2、K=3),聚类二维及三维可视化结果如下图所示(K=2以AR数据集为例,K=3以ORL数据集为例):
Tips:同色为K-means聚类同簇,同形状为原数据集同一类
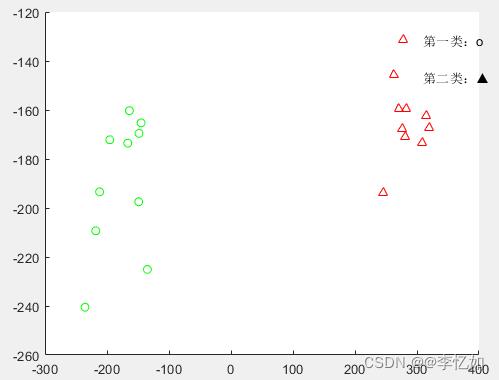
AR数据集K=2的聚类二维可视化

AR数据集K=2的聚类三维可视化
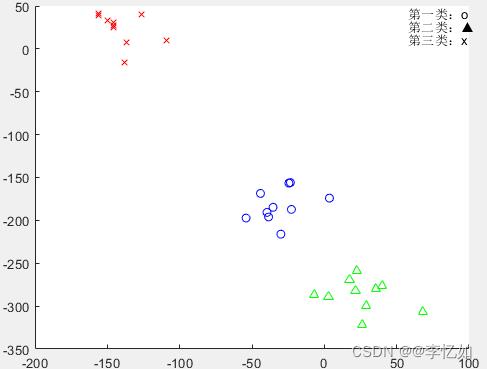
ORL数据集K=3的聚类二维可视化

ORL数据集K=3的聚类三维可视化
分析:由以上四图可以看出,对于AR与ORL数据集,K-means能够将不同人脸进行较正确聚类(不同形状对应不同颜色),聚类精度较高,效果较好。
5.2 数据集与K对聚类精度的影响
在不同数据集与不同K下对K-means进行聚类测试,每个数据集每个K进行20次实验取平均聚类精度分析,结果如下:
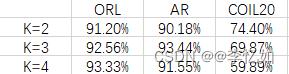

分析:由以上两图可以看出,K的选择与数据集的不同都会对聚类效果有影响,与理论分析一致。在本实验中,COIL20数据集下K-means的聚类精度远低于另外两个数据集,且随着K增大精度降低,原因与K-means聚类难以处理旋转物体有关。而对于ORL与AR数据集,聚类精度随K有小波动,但平均精度较高,聚类效果较好。
5.3 K-means优化前后的比较
在不同数据集(K=3)下分别使用K-means、K-means++、前文提到的创新聚类方法进行聚类测试,以此探究不同聚类算法的效率与聚类精度,每个数据集进行20次实验取平均聚类精度分析,结果如下:
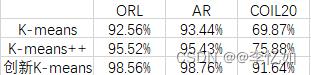
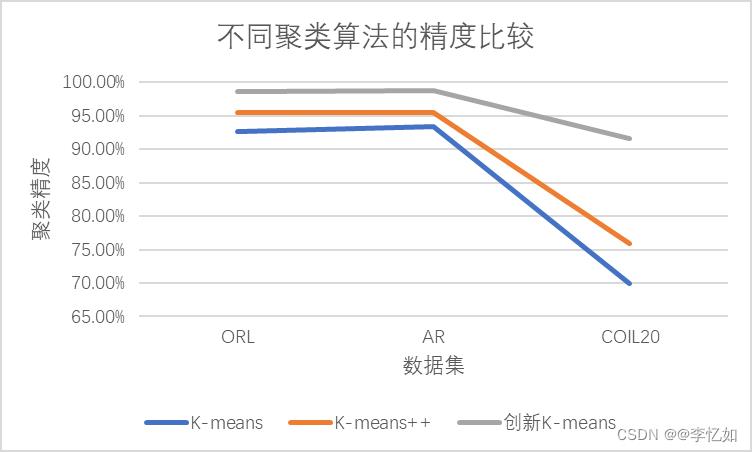
分析:由以上两图可以看出,K-means++与创新K-means作为K-means的优化版本,在不同数据集下相对K-means在效率与聚类精度下均有较大提升,尤其是前文提到的创新聚类算法,通过实验与比较可以分析出其相对经典K-means及其优化的优越性,效率、聚类效果与稳定性均有明显提升。
四、创新聚类算法设计
① 经典K-means的不足:K值选择与初始质心确定的困难、对数据的分布有要求、对异常值敏感、不适合样本多分类问题。
② 已有改进:K-means++、Xmeans、ISODATA、核K-means等等
③ 创新聚类算法简述:
一.选择K:由于K-means算法受K值影响较大,舍弃人为选择,使用Gap statistic法优化,确定最优K值。
二.初始聚类中心点:由于K-means算法受初始中心点影响较大,舍弃传统K-means的随机选择质心,先将数据采用层次聚类的方法预处理,得到的k个中心点作为K均值算法的中心点。
三.质心迭代:传统的聚类中心点更新是在结束一次循环后,本方法的聚类中心采用实时更新策略,即每次将一个模式归于一个新的聚类中心时,即立刻更新的所属中心和原属聚类中心的中心值,增强算法的收敛性。
四.增加不定K选择:为达到类内方差最小化,类间方差最大化这一原则,考虑到往往设定的K值不一定能很好实现聚类效果,故将以往的固定聚类中心改为一浮动区间。原有K为最小聚类中心个数,另设一聚类中心个数上限maxK。其具体实现如下:
4.1) 当一待聚类的模式得到其最近中心时,计算该聚类中心类内方差和将此模式归于该中心之后的类内方差,如果两者差别大于某设定阈值,则以该模式数据为基础,得到一新的聚类中心。
4.2) 在当前聚类中心个数等于设定的最大聚类中心时,合并最相邻的两个聚类。为使得到的聚类效果更为均衡,应该优先合并维度较小的聚类类别。
五. 终止判断:为防止聚类不准确及出现死循环等问题,同时使用最大迭代次数与最小误差变化(小阈值)作为终止判断条件,若满足某一条件,即输出聚类图像与结果。
五、K-means聚类出现的一些问题分析与优化
对理论分析与实验中出现的K-means存在的问题总结与优化如下:
① 聚类不准确
聚类不准确的情况示例如下:

分析:对于右边的样本集,我们用肉眼观察很明显聚类应该如红框所示,但是使用K-Means聚类后得到的结果与预期差异较大,存在多种原因,包括但不限于数据集的随机分布程度、阈值的设置、K的选择。
优化:减小阈值(即质心的位置变化),以达到更加精确的聚类
② 程序出现死循环
分析:对于一个数据集,可能的聚类方式不止一种,并且存在确实无法达到所有的聚类中心差都小于阈值的情况。
优化:加一个变量times用于记录执行了多少次while循环(迭代),当times达到一个很大的值而依旧没有停止程序,可以判断出现了死循环,直接输出结果,不再计算。
③ K值的选择
分析:不同 K 值对实验结果影响较大,但K值在经典K-means中是人为选择。
优化:使用手肘法(核心:取距离和曲线变化的拐点对应的K值)或Gap statistic法代替直接的人为选择,Gap statistic法核心优化问题如下(最大Gap(K)对应的K):

其中Dk为损失函数,这里E(logDk)指的是logDk的期望(通过蒙特卡洛模拟产生)。
④ 程序容易产生空蔟(最终聚类数量少于K)
分析:经典K-means容易受初始质心的影响,可能收敛到局部最小值。因此算法聚类时,容易产生空簇。
优化:使用K-Means++代替K-means,或使用其它优化初始质心的方法。
六、其他
1. 数据集及资源
本实验所用数据集:ORL5646、AR5040、COIL20。
常用人脸数据集如下(不要白嫖哈哈哈)
链接:https://pan.baidu.com/s/12Le0mKEquGMgh5fhNagZGw
提取码:yrnb
K-means与简单实践完整代码:李忆如/忆如的机器学习 - Gitee.com
2. 参考资料
1.【机器学习】K-means(非常详细) - 知乎 (zhihu.com)
2.K-Means算法实现(Matlab)_数学家是我理想的博客-CSDN博客_k-means++ matlab
3.k 均值聚类 - MATLAB kmeans - MathWorks 中国
4.【机器学习】K-Means算法及多种优化改进算法,聚类模型评估_Day-yong的博客-CSDN博客
5.模式识别中的K均值算法改进_k均值算法的改进-C++代码类资源-CSDN文库
总结
K-means作为经典的聚类算法,通过迭代确定最优质心将数据分为k个簇,实现聚类。如今仍然在机器学习许多领域(数据聚类、语言图像处理、推荐系统)有不错表现。且K-means算法原理简单,实现难度较低。但K-means作为一种无监督学习方法,未利用数据的原有信息,仍存在聚类不准确、容易出现空簇、受质心选择、k值影响等问题,另外,K-means假设的数据属性在现实世界的问题中往往难以达到,从而影响实验结果,本博客已提出一些优化方法与思路,后续博客会分析其他算法优化或解决上述问题。
 开发者涨薪指南
开发者涨薪指南
 48位大咖的思考法则、工作方式、逻辑体系
48位大咖的思考法则、工作方式、逻辑体系
以上是关于机器学习——K-means(聚类)与人脸识别的主要内容,如果未能解决你的问题,请参考以下文章