Myqsql使用Sharding-JDBC配置详解
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Myqsql使用Sharding-JDBC配置详解相关的知识,希望对你有一定的参考价值。
目录
1 需求说明
使用Sharding-JDBC完成对订单表的水平分表,通过快速入门程序的开发,快速体验Sharding-JDBC的使用方法。
人工创建两张表,t_order_1和t_order_2,这两张表是订单表拆分后的表,通过Sharding-Jdbc向订单表插入数据,按照一定的分片规则,主键为偶数的进入t_order_1,另一部分数据进入t_order_2,通过Sharding-Jdbc 查询数据,根据 SQL语句的内容从t_order_1或t_order_2查询数据。
2 环境搭建
2.1 环境说明
操作系统: Win10
数据库: mysql-5.7.25
JDK :64位 jdk1.8.0_201
应用框架: spring-boot-2.1.3.RELEASE,Mybatis3.5.0
Sharding-JDBC :sharding-jdbc-spring-boot-starter-4.0.0-RC1
2.2 创建数据库
创建订单库 order_db
CREATE DATABASE `order_db` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
在order_db中创建t_order_1、t_order_2表
DROP TABLE IF EXISTS `t_order_1`;
CREATE TABLE `t_order_1` (
`order_id` bigint(20) NOT NULL COMMENT '订单id',
`price` decimal(10, 2) NOT NULL COMMENT '订单价格',
`user_id` bigint(20) NOT NULL COMMENT '下单用户id',
`status` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '订单状态',
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
DROP TABLE IF EXISTS `t_order_2`;
CREATE TABLE `t_order_2` (
`order_id` bigint(20) NOT NULL COMMENT '订单id',
`price` decimal(10, 2) NOT NULL COMMENT '订单价格',
`user_id` bigint(20) NOT NULL COMMENT '下单用户id',
`status` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '订单状态',
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
2.3.引入maven依赖
引入 sharding-jdbc和SpringBoot整合的Jar包:
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding‐jdbc‐spring‐boot‐starter</artifactId>
<version>4.0.0‐RC1</version>
</dependency>
具体spring boot相关依赖及配置请参考资料中dbsharding/sharding-jdbc-simple工程,本指引只说明与Sharding-
JDBC相关的内容。
3 编写程序
3.1 分片规则配置
分片规则配置是sharding-jdbc进行对分库分表操作的重要依据,配置内容包括:数据源、主键生成策略、分片策略等。
在application.properties中配置
server.port=56081
spring.application.name = sharding‐jdbc‐simple‐demo
server.servlet.context‐path = /sharding‐jdbc‐simple‐demo
spring.http.encoding.enabled = true
spring.http.encoding.charset = UTF‐8
spring.http.encoding.force = true
spring.main.allow‐bean‐definition‐overriding = true
mybatis.configuration.map‐underscore‐to‐camel‐case = true
# 以下是分片规则配置
# 定义数据源
spring.shardingsphere.datasource.names = m1
spring.shardingsphere.datasource.m1.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver‐class‐name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m1.url = jdbc:mysql://localhost:3306/order_db?useUnicode=true
spring.shardingsphere.datasource.m1.username = root
spring.shardingsphere.datasource.m1.password = root
# 指定t_order表的数据分布情况,配置数据节点
spring.shardingsphere.sharding.tables.t_order.actual‐data‐nodes = m1.t_order_$‐>1..2
# 指定t_order表的主键生成策略为SNOWFLAKE
spring.shardingsphere.sharding.tables.t_order.key‐generator.column=order_id
spring.shardingsphere.sharding.tables.t_order.key‐generator.type=SNOWFLAKE
# 指定t_order表的分片策略,分片策略包括分片键和分片算法
spring.shardingsphere.sharding.tables.t_order.table‐strategy.inline.sharding‐column = order_id
spring.shardingsphere.sharding.tables.t_order.table‐strategy.inline.algorithm‐expression =
t_order_$‐>order_id % 2 + 1
# 打开sql输出日志
spring.shardingsphere.props.sql.show = true
swagger.enable = true
logging.level.root = info
logging.level.org.springframework.web = info
logging.level.com.itheima.dbsharding = debug
logging.level.druid.sql = debug
- 首先定义数据源m1,并对m1进行实际的参数配置。
2.指定t_order表的数据分布情况,他分布在m1.t_order_1,m1.t_order_2
3.指定t_order表的主键生成策略为SNOWFLAKE,SNOWFLAKE是一种分布式自增算法,保证id全局唯一
4.定义t_order分片策略,order_id为偶数的数据落在t_order_1,为奇数的落在t_order_2,分表策略的表达式为t_order_$->order_id % 2 + 1
3.2 sharding-jdbc4种分片策略
如果我一部分表做了分库分表,另一部分未做分库分表的表怎么处理?怎么才能正常访问?
这是一个比较典型的问题,我们知道分库分表是针对某些数据量持续大幅增长的表,比如用户表、订单表等,而不是一刀切将全部表都做分片。那么不分片的表和分片的表如何划分,一般有两种解决方案。
- 严格划分功能库,分片的库与不分片的库剥离开,业务代码中按需切换数据源访问
- 设置默认数据源,以
Sharding-JDBC为例,不给未分片表设置分片规则,它们就不会执行,因为找不到路由规则,这时我们设置一个默认数据源,在找不到规则时一律访问默认库。
# 配置数据源 ds-0
spring.shardingsphere.datasource.ds-0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds-0.driverClassName=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds-0.url=jdbc:mysql://47.94.6.5:3306/ds-0?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
spring.shardingsphere.datasource.ds-0.username=root
spring.shardingsphere.datasource.ds-0.password=root
# 默认数据源,未分片的表默认执行库
spring.shardingsphere.sharding.default-data-source-name=ds-0
这篇我们针对具体的SQL使用场景,实践一下4种分片策略的用法,开始前先做点准备工作。
- 标准分片策略
- 复合分片策略
- 行表达式分片策略
- Hint分片策略
3.2.1 准备工作
先创建两个数据库 ds-0、ds-1,两个库中分别建表 t_order_0、t_order_1、t_order_2 、t_order_item_0、t_order_item_1、t_order_item_2 6张表,下边实操看看如何在不同场景下应用 sharding-jdbc 的 4种分片策略。
t_order_n 表结构如下:
CREATE TABLE `t_order_0` (
`order_id` bigint(200) NOT NULL,
`order_no` varchar(100) DEFAULT NULL,
`user_id` bigint(200) NOT NULL,
`create_name` varchar(50) DEFAULT NULL,
`price` decimal(10,2) DEFAULT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
t_order_item_n 表结构如下:
CREATE TABLE `t_order_item_0` (
`item_id` bigint(100) NOT NULL,
`order_id` bigint(200) NOT NULL,
`order_no` varchar(200) NOT NULL,
`item_name` varchar(50) DEFAULT NULL,
`price` decimal(10,2) DEFAULT NULL,
PRIMARY KEY (`item_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
分片策略分为分表策略和分库策略,它们实现分片算法的方式基本相同,不同是一个对库ds-0、ds-1,一个对表 t_order_0 ··· t_order_n 等做处理。
3.2.2 标准分片策略
使用场景:SQL 语句中有>,>=, <=,<,=,IN 和 BETWEEN AND 操作符,都可以应用此分片策略。
标准分片策略(StandardShardingStrategy),它只支持对单个分片健(字段)为依据的分库分表,并提供了两种分片算法 PreciseShardingAlgorithm(精准分片)和 RangeShardingAlgorithm(范围分片)。
在使用标准分片策略时,精准分片算法是必须实现的算法,用于 SQL 含有 = 和 IN 的分片处理;范围分片算法是非必选的,用于处理含有 BETWEEN AND 的分片处理。
一旦我们没配置范围分片算法,而 SQL 中又用到
BETWEEN AND或者like等,那么 SQL 将按全库、表路由的方式逐一执行,查询性能会很差需要特别注意。
接下来自定义实现 精准分片算法 和 范围分片算法。
3.2.3 精准分片算法
精准分库算法
实现自定义精准分库、分表算法的方式大致相同,都要实现 PreciseShardingAlgorithm 接口,并重写 doSharding() 方法,只是配置稍有不同,而且它只是个空方法,得我们自行处理分库、分表逻辑。其他分片策略亦如此。
SELECT * FROM t_order where order_id = 1 or order_id in (1,2,3);
下边我们实现精准分库策略,通过对分片健 order_id 取模的方式(怎么实现看自己喜欢)计算出 SQL 该路由到哪个库,计算出的分片库信息会存放在分片上下文中,方便后续分表中使用。
/**
* @author
* @description 自定义标准分库策略
*/
public class MyDBPreciseShardingAlgorithm implements PreciseShardingAlgorithm<Long>
@Override
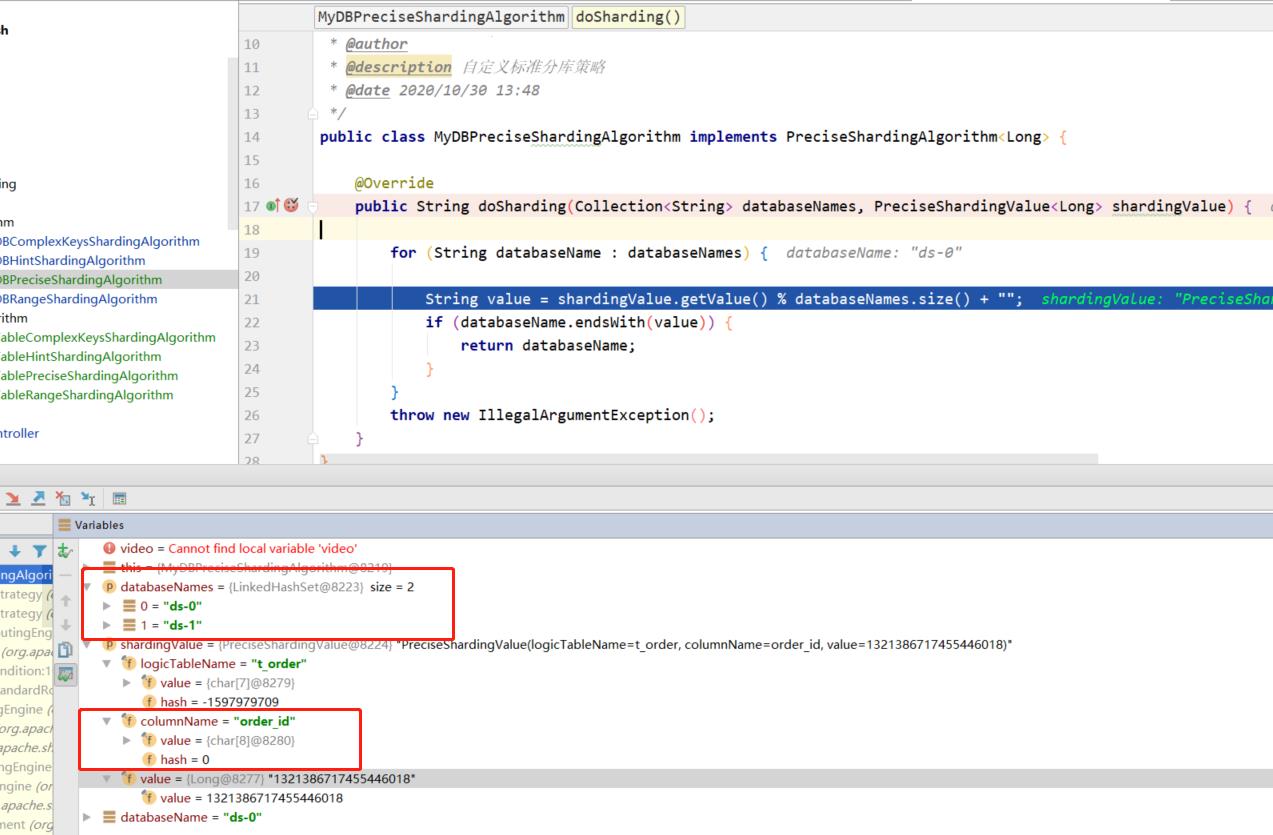
public String doSharding(Collection<String> databaseNames, PreciseShardingValue<Long> shardingValue)
/**
* databaseNames 所有分片库的集合
* shardingValue 为分片属性,其中 logicTableName 为逻辑表,columnName 分片健(字段),value 为从 SQL 中解析出的分片健的值
*/
for (String databaseName : databaseNames)
String value = shardingValue.getValue() % databaseNames.size() + "";
if (databaseName.endsWith(value))
return databaseName;
throw new IllegalArgumentException();
其中 Collection<String> 参数在几种分片策略中使用一致,在分库时值为所有分片库的集合 databaseNames,分表时为对应分片库中所有分片表的集合 tablesNames;PreciseShardingValue 为分片属性,其中 logicTableName 为逻辑表,columnName 分片健(字段),value 为从 SQL 中解析出的分片健的值。
而 application.properties 配置文件中只需修改分库策略名 database-strategy 为标准模式 standard,分片算法 standard.precise-algorithm-class-name 为自定义的精准分库算法类路径。
### 分库策略
# 分库分片健
spring.shardingsphere.sharding.tables.t_order.database-strategy.standard.sharding-column=order_id
# 分库分片算法
spring.shardingsphere.sharding.tables.t_order.database-strategy.standard.precise-algorithm-class-name=com.oldlu.sharding.algorithm.dbAlgorithm.MyDBPreciseShardingAlgorithm
精准分表算法
精准分表算法同样实现 PreciseShardingAlgorithm 接口,并重写 doSharding() 方法。
/**
* @description 自定义标准分表策略
*/
public class MyTablePreciseShardingAlgorithm implements PreciseShardingAlgorithm<Long>
@Override
public String doSharding(Collection<String> tableNames, PreciseShardingValue<Long> shardingValue)
/**
* tableNames 对应分片库中所有分片表的集合
* shardingValue 为分片属性,其中 logicTableName 为逻辑表,columnName 分片健(字段),value 为从 SQL 中解析出的分片健的值
*/
for (String tableName : tableNames)
/**
* 取模算法,分片健 % 表数量
*/
String value = shardingValue.getValue() % tableNames.size() + "";
if (tableName.endsWith(value))
return tableName;
throw new IllegalArgumentException();
分表时 Collection<String> 参数为上边计算出的分片库,对应的所有分片表的集合 tablesNames;PreciseShardingValue 为分片属性,其中 logicTableName 为逻辑表,columnName 分片健(字段),value 为从 SQL 中解析出的分片健的值。

application.properties 配置文件也只需修改分表策略名 database-strategy 为标准模式 standard,分片算法 standard.precise-algorithm-class-name 为自定义的精准分表算法类路径。
# 分表策略
# 分表分片健
spring.shardingsphere.sharding.tables.t_order.table-strategy.standard.sharding-column=order_id
# 分表算法
spring.shardingsphere.sharding.tables.t_order.table-strategy.standard.precise-algorithm-class-name=com.oldlu.sharding.algorithm.tableAlgorithm.MyTablePreciseShardingAlgorithm
看到这不难发现,自定义分库和分表算法的实现基本是一样的,所以后边我们只演示分库即可
3.2.4 范围分片算法
使用场景:当我们 SQL中的分片健字段用到 BETWEEN AND操作符会使用到此算法,会根据 SQL中给出的分片健值范围值处理分库、分表逻辑。
SELECT * FROM t_order where order_id BETWEEN 1 AND 100;
自定义范围分片算法需实现 RangeShardingAlgorithm 接口,重写 doSharding() 方法,下边我通过遍历分片健值区间,计算每一个分库、分表逻辑。
/**
* @description 范围分库算法
*/
public class MyDBRangeShardingAlgorithm implements RangeShardingAlgorithm<Integer>
@Override
public Collection<String> doSharding(Collection<String> databaseNames, RangeShardingValue<Integer> rangeShardingValue)
Set<String> result = new LinkedHashSet<>();
// between and 的起始值
int lower = rangeShardingValue.getValueRange().lowerEndpoint();
int upper = rangeShardingValue.getValueRange().upperEndpoint();
// 循环范围计算分库逻辑
for (int i = lower; i <= upper; i++)
for (String databaseName : databaseNames)
if (databaseName.endsWith(i % databaseNames.size() + ""))
result.add(databaseName);
return result;
和上边的一样 Collection<String> 在分库、分表时分别代表分片库名和表名集合,RangeShardingValue 这里取值方式稍有不同, lowerEndpoint 表示起始值, upperEndpoint 表示截止值。

在配置上由于范围分片算法和精准分片算法,同在标准分片策略下使用,所以只需添加上 range-algorithm-class-name 自定义范围分片算法类路径即可。
# 精准分片算法
spring.shardingsphere.sharding.tables.t_order.database-strategy.standard.precise-algorithm-class-name=com.oldlu.sharding.algorithm.dbAlgorithm.MyDBPreciseShardingAlgorithm
# 范围分片算法
spring.shardingsphere.sharding.tables.t_order.database-strategy.standard.range-algorithm-class-name=com.oldlu.sharding.algorithm.dbAlgorithm.MyDBRangeShardingAlgorithm
3.2.5 复合分片策略
使用场景:SQL 语句中有>,>=, <=,<,=,IN 和 BETWEEN AND 等操作符,不同的是复合分片策略支持对多个分片健操作。
下面我们实现同时以 order_id、user_id 两个字段作为分片健,自定义复合分片策略。
SELECT * FROM t_order where user_id =0 and order_id = 1;
我们先修改一下原配置,complex.sharding-column 切换成 complex.sharding-columns 复数,分片健上再加一个 user_id ,分片策略名变更为 complex ,complex.algorithm-class-name 替换成我们自定义的复合分片算法。
### 分库策略
# order_id,user_id 同时作为分库分片健
spring.shardingsphere.sharding.tables.t_order.database-strategy.complex.sharding-column=order_id,user_id
# 复合分片算法
spring.shardingsphere.sharding.tables.t_order.database-strategy.complex.algorithm-class-name=com.oldlu.sharding.algorithm.dbAlgorithm.MyDBComplexKeysShardingAlgorithm
自定义复合分片策略要实现 ComplexKeysShardingAlgorithm 接口,重新 doSharding()方法。
/**
* @description 自定义复合分库策略
*/
public class MyDBComplexKeysShardingAlgorithm implements ComplexKeysShardingAlgorithm<Integer>
@Override
public Collection<String> doSharding(Collection<String> databaseNames, ComplexKeysShardingValue<Integer> complexKeysShardingValue)
// 得到每个分片健对应的值
Collection<Integer> orderIdValues = this.getShardingValue(complexKeysShardingValue, "order_id");
Collection<Integer> userIdValues = this.getShardingValue(complexKeysShardingValue, "user_id");
List<String> shardingSuffix = new ArrayList<>();
// 对两个分片健同时取模的方式分库
for (Integer userId : userIdValues)
for (Integer orderId : orderIdValues)
String suffix = userId % 2 + "_" + orderId % 2;
for (String databaseName : databaseNames)
if (databaseName.endsWith(suffix))
shardingSuffix.add(databaseName);
return shardingSuffix;
private Collection<Integer> getShardingValue(ComplexKeysShardingValue<Integer> shardingValues, final String key)
Collection<Integer> valueSet = new ArrayList<>();
Map<String, Collection<Integer>> columnNameAndShardingValuesMap = shardingValues.getColumnNameAndShardingValuesMap();
if (columnNameAndShardingValuesMap.containsKey(key))
valueSet.addAll(columnNameAndShardingValuesMap.get(key));
return valueSet;
Collection<String> 用法还是老样子,由于支持多分片健 ComplexKeysShardingValue 分片属性内用一个分片健为 key,分片健值为 value 的 map来存储分片键属性。

3.2.6 行表达式分片策略
行表达式分片策略(InlineShardingStrategy),在配置中使用 Groovy 表达式,提供对 SQL语句中的 = 和 IN 的分片操作支持,它只支持单分片健。
行表达式分片策略适用于做简单的分片算法,无需自定义分片算法,省去了繁琐的代码开发,是几种分片策略中最为简单的。
它的配置相当简洁,这种分片策略利用inline.algorithm-expression书写表达式。
比如:ds-$->order_id % 2 表示对 order_id 做取模计算,$ 是个通配符用来承接取模结果,最终计算出分库ds-0 ··· ds-n,整体来说比较简单。
# 行表达式分片键
sharding.jdbc.config.sharding.tables.t_order.database-strategy.inline.sharding-column=order_id
# 表达式算法
sharding.jdbc.config.sharding.tables.t_order.database-strategy.inline.algorithm-expression=ds-$->order_id % 2
3.2.7 Hint分片策略
Hint分片策略(HintShardingStrategy)相比于上面几种分片策略稍有不同,这种分片策略无需配置分片健,分片健值也不再从 SQL中解析,而是由外部指定分片信息,让 SQL在指定的分库、分表中执行。ShardingSphere 通过 Hint API实现指定操作,实际上就是把分片规则tablerule 、databaserule由集中配置变成了个性化配置。
举个例子,如果我们希望订单表t_order用
以上是关于Myqsql使用Sharding-JDBC配置详解的主要内容,如果未能解决你的问题,请参考以下文章