5W 字详解分库分表之 Sharding-JDBC 中间件
Posted Java后端
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了5W 字详解分库分表之 Sharding-JDBC 中间件相关的知识,希望对你有一定的参考价值。
本文大纲如下
Sharding-JDBC 的基本用法和基本原理
前言
1. 我的出生和我的家族
2. 我统治的世界和我的职责
3. 召唤我的方式
4. 我的特性和我的工作方法
4.3.1. SQL 解析
4.3.2. SQL 路由
4.3.3. SQL 改写
4.3.4. SQL 执行
4.3.5. 结果归并
4.2.1. 逻辑表和物理表
4.2.2. 分片键
4.2.3. 路由
4.2.4. 分片策略和分片算法
4.2.5. 绑定表
4.2. 一些核心概念
4.3. 我处理 SQL 的过程
5. 结束语
这是一篇将“介绍 Sharding-JDBC 基本使用方法”作为目标的文章,但笔者却把大部分文字放在对 Sharding-JDBC 的工作原理的描述上,因为笔者认为原理是每个 IT 打工人学习技术的归途。
使用框架、中间件、数据库、工具包等公共组件来组装出应用系统是我们这一代 IT 打工人工作的常态。对于这些公共组件——比如框架——的学习,有些人的方法是这样的:避开复杂晦涩的框架原理,仅仅关注它的各种配置、API、注解,在尝试了这个框架的常用配置项、API、注解的效果之后,就妄称自己学会了这个框架。这种对技术的肤浅的认知既经不起实践的考验,也经不起面试官的考验,甚至连自己使用这些配置项、API、注解在干什么都没有明确的认知。
所以,打工人们,还是多学点原理,多看点源码,让优秀的设计思想、算法和编程风格冲击一下自己的大脑吧 :-)
因为 Sharding-JDBC 的设计细节实在太多,因此本文不可能对 Sharding-JDBC 进行面面俱到的讲解。笔者在本文中仅仅保留了对 Sharding-JDBC 的核心特性、核心原理的讲解,并尽量使用简单生动的文字进行表达,使读者阅读本文后对 Sharding-JDBC 的基本原理和使用有清晰的认知。为了使这些文字尽量摆脱枯燥的味道,文章采用了第一人称的讲述方式,让 Sharding-JDBC 现身说法,进行自我剖析,希望给大家一个更好的阅读体验。
但是,妄图不动脑子就能对某项技术产生深度认知是绝不可能的,你思考得越多,你得到的越多。这就印证了那句话:“我变秃了,也变强了。”
1. 我的出生和我的家族
我是 Sharding-JDBC,一个关系型数据库中间件,我的全名是 Apache ShardingSphere JDBC,我被冠以 Apache 这个贵族姓氏是 2020 年 4 月的事情,这意味着我进入了代码世界的“体制内”。但我还是喜欢别人称呼我的小名,Sharding-JDBC。
我的创造者在我诞生之后给我讲了我的身世:
“
你的诞生是一个必然的结果。
在你诞生之前,传统软件的存储层架构将所有的业务数据存储到单一数据库节点,在性能、可用性和运维成本这三方面已经难于满足互联网的海量数据场景。
从性能方面来说,由于关系型数据库大多采用 B+树类型的索引,在数据量逐渐增大的情况下,索引深度的增加也将使得磁盘访问的 IO 次数增加,进而导致查询性能的下降;同时,高并发访问请求也使得集中式数据库成为系统的最大瓶颈。
从可用性的方面来讲,应用服务器节点能够随意水平拓展(水平拓展就是增加应用服务器节点数量)以应对不断增加的业务流量,这必然导致系统的最终压力都落在数据库之上。而单一的数据库节点,或者简单的主从架构,已经越来越难以承担众多应用服务器节点的数据查询请求。数据库的可用性,已成为整个系统的关键。
从运维成本方面考虑,随着数据库实例中的数据规模的增大,DBA 的运维压力也会增加,因为数据备份和恢复的时间成本都将随着数据量的增大而愈发不可控。
这样看来关系型数据库似乎难以承担海量记录的存储。
然而,关系型数据库当今依然占有巨大市场,是各个公司核心业务的基石。在传统的关系型数据库无法满足互联网场景需要的情况下,将数据存储到原生支持分布式的 NoSQL 的尝试越来越多。但 NoSQL 对 SQL 的不兼容性以及生态圈的不完善,使得它们在与关系型数据库的博弈中处于劣势,关系型数据库的地位却依然不可撼动,未来也难于撼动。
我们目前阶段更加关注在原有关系型数据库的基础上做增量,使之更好适应海量数据存储和高并发查询请求的场景,而不是要颠覆关系型数据库。
分库分表方案就是这种增量,它的诞生解决了海量数据存储和高并发查询请求的问题。
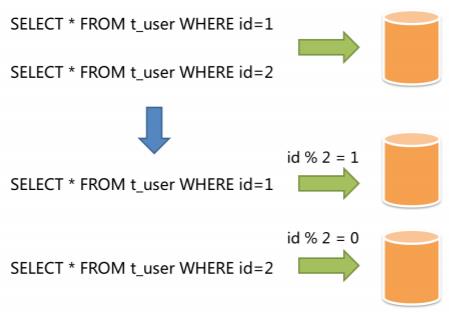
但是,单一数据库被分库分表之后,繁杂的库和表使得编写持久层代码的工程师的思维负担翻了很多倍,他们需要考虑一个业务 SQL 应该去哪个库的哪个表里去查询,查询到的结果还要进行聚合,如果遇到多表关联查询、排序、分页、事务等等问题,那简直是一个噩梦。
于是我们创造了你。你可以让工程师们以像查询单数据库实例和单表那样来查询被水平分割的库和表,我们称之为透明查询。
你是水平分片世界的神。
”
这使我感到骄傲。
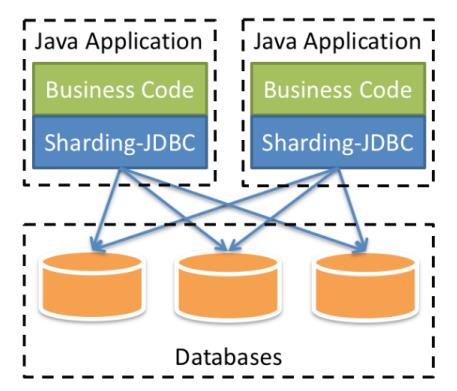
我被定位为一个轻量级 Java 框架,我在 Java 的 JDBC 层提供的额外服务,可以说是一个增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
-
我适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC。 -
我支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP 等。 -
我支持任意实现 JDBC 规范的数据库,目前支持 mysql,Oracle,SQLServer,PostgreSQL 以及任何遵循 SQL92 标准的数据库。
2. 我统治的世界和我的职责
3. 召唤我的方式
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core</artifactId>
<version>${latest.release.version}</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-spring-boot-starter</artifactId>
<version>${shardingsphere.version}</version>
</dependency>
// 配置真实数据源
Map<String, DataSource> dataSourceMap = new HashMap<>();
// 配置第 1 个数据源
BasicDataSource dataSource1 = new BasicDataSource();
dataSource1.setDriverClassName("com.mysql.jdbc.Driver");
dataSource1.setUrl("jdbc:mysql://localhost:3306/ds0");
dataSource1.setUsername("root");
dataSource1.setPassword("");
dataSourceMap.put("ds0", dataSource1);
// 配置第 2 个数据源
BasicDataSource dataSource2 = new BasicDataSource();
dataSource2.setDriverClassName("com.mysql.jdbc.Driver");
dataSource2.setUrl("jdbc:mysql://localhost:3306/ds1");
dataSource2.setUsername("root");
dataSource2.setPassword("");
dataSourceMap.put("ds1", dataSource2);
// 配置 t_order 表规则
ShardingTableRuleConfiguration orderTableRuleConfig
= new ShardingTableRuleConfiguration(
"t_order",
"ds${0..1}.t_order${0..1}"
);
// 配置 t_order 被拆分到多个子库的策略
orderTableRuleConfig.setDatabaseShardingStrategy(
new StandardShardingStrategyConfiguration(
"user_id",
"dbShardingAlgorithm"
)
);
// 配置 t_order 被拆分到多个子表的策略
orderTableRuleConfig.setTableShardingStrategy(
new StandardShardingStrategyConfiguration(
"order_id",
"tableShardingAlgorithm"
)
);
// 省略配置 t_order_item 表规则...
// ...
// 配置分片规则
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTables().add(orderTableRuleConfig);
// 配置 t_order 被拆分到多个子库的算法
Properties dbShardingAlgorithmrProps = new Properties();
dbShardingAlgorithmrProps.setProperty(
"algorithm-expression",
"ds${user_id % 2}"
);
shardingRuleConfig.getShardingAlgorithms().put(
"dbShardingAlgorithm",
new ShardingSphereAlgorithmConfiguration("INLINE", dbShardingAlgorithmrProps)
);
// 配置 t_order 被拆分到多个子表的算法
Properties tableShardingAlgorithmrProps = new Properties();
tableShardingAlgorithmrProps.setProperty(
"algorithm-expression",
"t_order${order_id % 2}"
);
shardingRuleConfig.getShardingAlgorithms().put(
"tableShardingAlgorithm",
new ShardingSphereAlgorithmConfiguration("INLINE", tableShardingAlgorithmrProps)
);
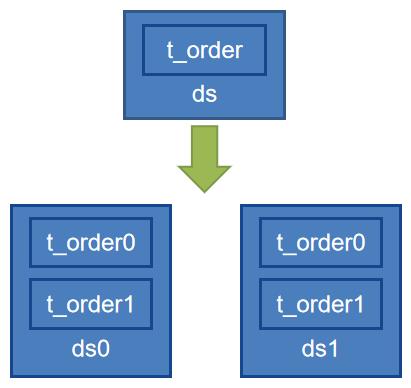
ds$->{0..1}.t_order$->{0..1}
ds_${user_id % 2}
t_order_${order_id % 2}
# 配置真实数据源
spring.shardingsphere.datasource.names=ds0,ds1
# 配置第 1 个数据源
spring.shardingsphere.datasource.ds0.type=org.apache.commons.dbcp2.BasicDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds0.url=jdbc:mysql://localhost:3306/ds0
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=
# 配置第 2 个数据源
spring.shardingsphere.datasource.ds1.type=org.apache.commons.dbcp2.BasicDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/ds1
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=
# 配置 t_order 表规则
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=ds$->{0..1}.t_order$->{0..1}
# 配置 t_order 被拆分到多个子库的策略
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-column=user_id
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-algorithm-name=database_inline
# 配置 t_order 被拆分到多个子表的策略
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-column=order_id
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-algorithm-name=table_inline
# 省略配置 t_order_item 表规则...
# ...
# 配置 t_order 被拆分到多个子库的算法
spring.shardingsphere.rules.sharding.sharding-algorithms.database_inline.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.database_inline.props.algorithm-expression=ds_${user_id % 2}
# 配置 t_order 被拆分到多个子表的算法
spring.shardingsphere.rules.sharding.sharding-algorithms.table_inline.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.table_inline.props.algorithm-expression=t_order_${order_id % 2}
// 创建 ShardingSphereDataSource
DataSource dataSource = ShardingSphereDataSourceFactory.createDataSource(
dataSourceMap,
Collections.singleton(shardingRuleConfig, new Properties())
);
/**
* 注入一个 ShardingSphereDataSource 实例
*/
@Resource
private DataSource dataSource;
String sql = "SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.user_id=? AND o.order_id=?";
try (
Connection conn = dataSource.getConnection();
PreparedStatement ps = conn.prepareStatement(sql)
) {
ps.setInt(1, 10);
ps.setInt(2, 1000);
try (
ResultSet rs = preparedStatement.executeQuery()
) {
while(rs.next()) {
// ...
}
}
}
4. 我的特性和我的工作方法
4.2. 一些核心概念
4.2.1. 逻辑表和物理表
4.2.2. 分片键
4.2.3. 路由
4.2.4. 分片策略和分片算法
......
// 配置 t_order 被拆分到多个子库的策略
orderTableRuleConfig.setDatabaseShardingStrategy(
new StandardShardingStrategyConfiguration(
"user_id",
"dbShardingAlgorithm"
)
);
// 配置 t_order 被拆分到多个子表的策略
orderTableRuleConfig.setTableShardingStrategy(
new StandardShardingStrategyConfiguration(
"order_id",
"tableShardingAlgorithm"
)
);
......
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTables().add(orderTableRuleConfig);
// 配置 t_order 被拆分到多个子库的算法
Properties dbShardingAlgorithmrProps = new Properties();
dbShardingAlgorithmrProps.setProperty(
"algorithm-expression",
"ds${user_id % 2}"
);
shardingRuleConfig.getShardingAlgorithms().put(
"dbShardingAlgorithm",
new ShardingSphereAlgorithmConfiguration("INLINE", dbShardingAlgorithmrProps)
);
// 配置 t_order 被拆分到多个子表的算法
Properties tableShardingAlgorithmrProps = new Properties();
tableShardingAlgorithmrProps.setProperty(
"algorithm-expression",
"t_order${order_id % 2}"
);
shardingRuleConfig.getShardingAlgorithms().put(
"tableShardingAlgorithm",
new ShardingSphereAlgorithmConfiguration("INLINE", tableShardingAlgorithmrProps)
);
......
package org.apache.shardingsphere.core.strategy.route.standard;
......
public final class StandardShardingStrategy implements ShardingStrategy {
private final String shardingColumn;
/**
* 要配合 PreciseShardingAlgorithm 或 RangeShardingAlgorithm 使用
* 标准分片策略
*/
private final PreciseShardingAlgorithm preciseShardingAlgorithm;
private final RangeShardingAlgorithm rangeShardingAlgorithm;
public StandardShardingStrategy(
// 传入分片配置
final StandardShardingStrategyConfiguration standardShardingStrategyConfig
) {
......
// 从配置中提取分片键
shardingColumn = standardShardingStrategyConfig.getShardingColumn();
// 从配置中提取分片算法
preciseShardingAlgorithm = standardShardingStrategyConfig.getPreciseShardingAlgorithm();
rangeShardingAlgorithm = standardShardingStrategyConfig.getRangeShardingAlgorithm();
}
@Override
public Collection<String> doSharding(
// 所有可能的分片表(或分片库)名称
final Collection<String> availableTargetNames,
// 分片键的值
final Collection<RouteValue> shardingValues,
final ConfigurationProperties properties
) {
RouteValue shardingValue = shardingValues.iterator().next();
Collection<String> shardingResult
= shardingValue instanceof ListRouteValue
// 处理精确分片
? doSharding(availableTargetNames, (ListRouteValue) shardingValue)
// 处理范围分片
: doSharding(availableTargetNames, (RangeRouteValue) shardingValue);
Collection<String> result = new TreeSet<>(String.CASE_INSENSITIVE_ORDER);
result.addAll(shardingResult);
// 根据分片键的值,找到对应的分片表(或分片库)名称并返回
return result;
}
/**
* 处理范围分片
*/
@SuppressWarnings("unchecked")
private Collection<String> doSharding(
// 所有可能的分片表(或分片库)名称
final Collection<String> availableTargetNames,
// 分片键的值
final RangeRouteValue<?> shardingValue
) {
......
// 调用 rangeShardingAlgorithm.doSharding()根据分片键的值找到对应的
// 分片表(或分片库)名称并返回,rangeShardingAlgorithm.doSharding()
// 由你们自己实现
return rangeShardingAlgorithm.doSharding(
availableTargetNames,
new RangeShardingValue(
shardingValue.getTableName(),
shardingValue.getColumnName(),
shardingValue.getValueRange()
)
);
}
/**
* 处理精确分片
*/
@SuppressWarnings("unchecked")
private Collection<String> doSharding(
// 所有可能的分片表(或分片库)名称
final Collection<String> availableTargetNames,
// 分片键的值
final ListRouteValue<?> shardingValue
) {
Collection<String> result = new LinkedList<>();
for (Comparable<?> each : shardingValue.getValues()) {
// 调用 preciseShardingAlgorithm.doSharding()根据分片键的值找到对应的
// 分片表(或分片库)名称并返回,preciseShardingAlgorithm.doSharding()
// 由你们自己实现
String target
= preciseShardingAlgorithm.doSharding(
availableTargetNames,
new PreciseShardingValue(
shardingValue.getTableName(),
shardingValue.getColumnName(),
each
)
);
if (null != target) {
result.add(target);
}
}
return result;
}
/**
* 获取所有的分片键
*/
@Override
public Collection<String> getShardingColumns() {
Collection<String> result = new TreeSet<>(String.CASE_INSENSITIVE_ORDER);
result.add(shardingColumn);
return result;
}
}
package org.apache.shardingsphere.api.sharding.standard;
......
public interface PreciseShardingAlgorithm<T extends Comparable<?>>
extends ShardingAlgorithm {
/**
* @param 所有可能的分片表(或分片库)名称
* @param 分片键的值
* @return 根据分片键的值,找到对应的分片表(或分片库)名称并返回
*/
String doSharding(
Collection<String> availableTargetNames,
PreciseShardingValue<T> shardingValue
);
}
package org.apache.shardingsphere.api.sharding.standard;
......
public interface RangeShardingAlgorithm<T extends Comparable<?>>
extends ShardingAlgorithm {
/**
* @param 所有可能的分片表(或分片库)名称
* @param 分片键的值
* @return 根据分片键的值,找到对应的分片表(或分片库)名称并返回
*/
Collection<String> doSharding(
Collection<String> availableTargetNames,
RangeShardingValue<T> shardingValue
);
}
策略一:设置 6 个分片
t_order.order_id % 6 == 0 的查询分片到 t_order0
t_order.order_id % 6 == 1 的查询分片到 t_order1
t_order.order_id % 6 == 2 的查询分片到 t_order2
t_order.order_id % 6 == 3 的查询分片到 t_order3
t_order.order_id % 6 == 4 的查询分片到 t_order4
t_order.order_id % 6 == 5 的查询分片到 t_order5
策略二:设置 2 个分片
t_order.order_id % 6 in (0,2,4) 的查询分片到 t_order1
t_order.order_id % 6 in (1,3,5) 的查询分片到 t_order1
策略三:经过估算订单不超过 60000 个,设置 6 个分片
t_order.order_id between 0 and 10000 的查询分片到 t_order0
t_order.order_id between 10000 and 20000 的查询分片到 t_order1
t_order.order_id between 20000 and 30000 的查询分片到 t_order2
t_order.order_id between 30000 and 40000 的查询分片到 t_order3
t_order.order_id between 40000 and 50000 的查询分片到 t_order4
t_order.order_id between 50000 and 60000 的查询分片到 t_order5
策略四:经过估算订单不超过 20000 个,设置 2 个分片
t_order.order_id <=10000 的查询分片到 t_order0
t_order.order_id >10000 的查询分片到 t_order1
......
-- 注:使用 t_order.order_id 作为 t_order 表的分片键
SELECT o.* FROM t_order o WHERE o.order_id = 10;
SELECT o.* FROM t_order o WHERE o.order_id IN (10, 11);
SELECT o.* FROM t_order o WHERE o.order_id > 10;
SELECT o.* FROM t_order o WHERE o.order_id <= 11;
SELECT o.* FROM t_order o WHERE o.order_id BETWEEN 10 AND 12;
......
INSERT INTO t_order(order_id, user_id) VALUES (20, 1001);
......
DELETE FROM t_order o WHERE o.order_id = 10;
DELETE FROM t_order o WHERE o.order_id IN (10, 11);
DELETE FROM t_order o WHERE o.order_id > 10;
DELETE FROM t_order o WHERE o.order_id <= 11;
DELETE FROM t_order o WHERE o.order_id BETWEEN 10 AND 12;
......
UPDATE t_order o SET o.update_time = NOW() WHERE o.order_id = 10;
......
package org.apache.shardingsphere.core.strategy.route.complex;
......
public final class ComplexShardingStrategy implements ShardingStrategy {
@Getter
private final Collection<String> shardingColumns;
/**
* 要配合 ComplexKeysShardingAlgorithm 使用复合分片策略
*/
private final ComplexKeysShardingAlgorithm shardingAlgorithm;
public ComplexShardingStrategy(
// 传入分片配置
final ComplexShardingStrategyConfiguration complexShardingStrategyConfig
) {
......
// 从配置中提取分片键
shardingColumns = new TreeSet<>(String.CASE_INSENSITIVE_ORDER);
shardingColumns.addAll(
Splitter
.on(",")
.trimResults()
.splitToList(complexShardingStrategyConfig.getShardingColumns())
);
// 从配置中提取分片算法
shardingAlgorithm = complexShardingStrategyConfig.getShardingAlgorithm();
}
@SuppressWarnings("unchecked")
@Override
public Collection<String> doSharding(
// 所有可能的分片表(或分片库)名称
final Collection<String> availableTargetNames,
// 分片键的值
final Collection<RouteValue> shardingValues,
final ConfigurationProperties properties
) {
Map<String, Collection<Comparable<?>>> columnShardingValues
= new HashMap<>(shardingValues.size(), 1);
Map<String, Range<Comparable<?>>> columnRangeValues
= new HashMap<>(shardingValues.size(), 1);
String logicTableName = "";
// 提取多个分片键的值
for (RouteValue each : shardingValues) {
if (each instanceof ListRouteValue) {
columnShardingValues.put(
each.getColumnName(),
((ListRouteValue) each).getValues()
);
} else if (each instanceof RangeRouteValue) {
columnRangeValues.put(
each.getColumnName(),
((RangeRouteValue) each).getValueRange()
);
}
logicTableName = each.getTableName();
}
Collection<String> shardingResult
// 调用 shardingAlgorithm.doSharding()根据分片键的值找到对应的
// 分片表(或分片库)名称并返回,shardingAlgorithm.doSharding()
// 由你们自己实现
= shardingAlgorithm.doSharding(
availableTargetNames,
new ComplexKeysShardingValue(
logicTableName,
columnShardingValues,
columnRangeValues)
);
Collection<String> result = new TreeSet<>(String.CASE_INSENSITIVE_ORDER);
result.addAll(shardingResult);
// 根据分片键的值,找到对应的分片表(或分片库)名称并返回
return result;
}
}
package org.apache.shardingsphere.api.sharding.complex;
......
public interface ComplexKeysShardingAlgorithm<T extends Comparable<?>>
extends ShardingAlgorithm {
/**
* @param 所有可能的分片表(或分片库)名称
* @param 分片键的值
* @return 根据分片键的值,找到对应的分片表(或分片库)名称并返回
*/
Collection<String> doSharding(
Collection<String> availableTargetNames,
ComplexKeysShardingValue<T> shardingValue
);
}
策略一:设置 4 个分片
t_order.order_id % 2 == 0 && t_order.user_id % 2 == 0 的查询分片到 t_order0
t_order.order_id % 2 == 0 && t_order.user_id % 2 == 1 的查询分片到 t_order1
t_order.order_id % 2 == 1 && t_order.user_id % 2 == 0 的查询分片到 t_order2
t_order.order_id % 2 == 1 && t_order.user_id % 2 == 1 的查询分片到 t_order3
策略二:经过估算订单不超过 60000 个、用户不超过 1000 个,设置 4 个分片
t_order.order_id between 0 and 40000 && t_order.user_id between 0 and 500 的查询分片到 t_order0
t_order.order_id between 0 and 40000 && t_order.user_id between 500 and 1000 的查询分片到 t_order1
t_order.order_id between 40000 and 60000 && t_order.user_id between 0 and 500 的查询分片到 t_order2
t_order.order_id between 40000 and 60000 && t_order.user_id between 500 and 1000 的查询分片到 t_order3
......
-- 注:使用 t_order.order_id、t_order.user_id 作为 t_order 表的分片键
SELECT o.* FROM t_order o WHERE o.order_id = 10;
SELECT o.* FROM t_order o WHERE o.order_id IN (10, 11);
SELECT o.* FROM t_order o WHERE o.order_id > 10;
SELECT o.* FROM t_order o WHERE o.order_id <= 11;
SELECT o.* FROM t_order o WHERE o.order_id BETWEEN 10 AND 12;
......
INSERT INTO t_order(order_id, user_id) VALUES (20, 1001);
......
DELETE FROM t_order o WHERE o.order_id = 10;
DELETE FROM t_order o WHERE o.order_id IN (10, 11);
DELETE FROM t_order o WHERE o.order_id > 10;
DELETE FROM t_order o WHERE o.order_id <= 11;
DELETE FROM t_order o WHERE o.order_id BETWEEN 10 AND 12;
......
UPDATE t_order o SET o.update_time = NOW() WHERE o.order_id = 10;
......
SELECT o.* FROM t_order o WHERE o.order_id = 10 AND user_id = 1001;
SELECT o.* FROM t_order o WHERE o.order_id IN (10, 11) AND user_id IN (......);
SELECT o.* FROM t_order o WHERE o.order_id > 10 AND user_id > 1000;
SELECT o.* FROM t_order o WHERE o.order_id <= 11 AND user_id <= 1000;
SELECT o.* FROM t_order o WHERE (o.order_id BETWEEN 10 AND 12) AND (o.user_id BETWEEN 1000 AND 2000);
......
INSERT INTO t_order(order_id, user_id) VALUES (21, 1002);
......
DELETE FROM t_order o WHERE o.order_id = 10 AND user_id = 1001;
DELETE FROM t_order o WHERE o.order_id IN (10, 11) AND user_id IN (......);
DELETE FROM t_order o WHERE o.order_id > 10 AND user_id > 1000;
DELETE FROM t_order o WHERE o.order_id <= 11 AND user_id <= 1000;
DELETE FROM t_order o WHERE (o.order_id BETWEEN 10 AND 12) AND (o.user_id BETWEEN 1000 AND 2000);
......
UPDATE t_order o SET o.update_time = NOW() WHERE o.order_id = 10 AND user_id = 1001;
......
String sql = "SELECT * FROM t_order";
try (
// HintManager 是使用“暗示”的工具,它会把暗示的分片值放入
// 当前线程上下文(ThreadLocal)中,这样当前线程执行 SQL 的
// 时候就能获取到分片值
HintManager hintManager = HintManager.getInstance();
Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql);
) {
hintManager.setDatabaseShardingValue(3);
try (ResultSet rs = pstmt.executeQuery()) {
// 若 t_order 仅仅使用 order_id 作为分片键,则这里根据暗
// 示获取了分片值,因此上面的 SQL 的实际执行效果相当于:
// SELECT * FROM t_order where order_id = 3
while (rs.next()) {
//...
}
}
}
package org.apache.shardingsphere.core.strategy.route.none;
......
@Getter
public final class NoneShardingStrategy implements ShardingStrategy {
private final Collection<String> shardingColumns = Collections.emptyList();
@Override
public Collection<String> doSharding(
// 所有可能的分片表(或分片库)名称
final Collection<String> availableTargetNames,
// 分片键的值
final Collection<RouteValue> shardingValues,
final ConfigurationProperties properties
) {
// 不需要任何算法,不进行任何逻辑处理,直接返回
// 所有可能的分片表(或分片库)名称
return availableTargetNames;
}
}
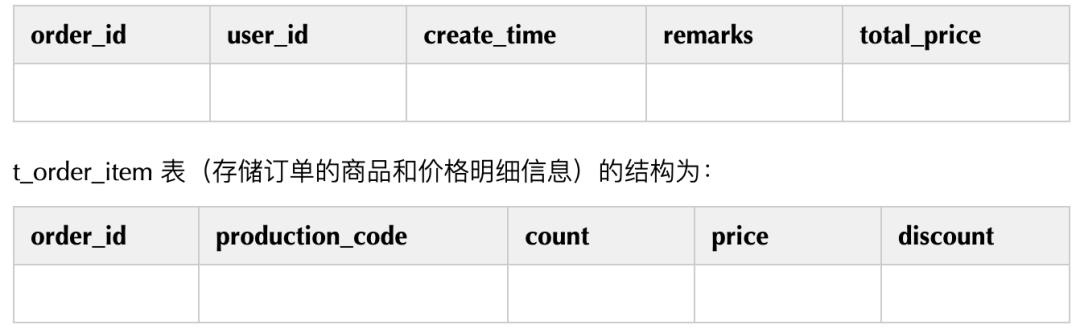
4.2.5. 绑定表
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id IN (10, 11);
SELECT i.* FROM t_order0 o JOIN t_order_item0 i ON o.order_id=i.order_id WHERE o.order_id IN (10, 11);
SELECT i.* FROM t_order0 o JOIN t_order_item1 i ON o.order_id=i.order_id WHERE o.order_id IN (10, 11);
SELECT i.* FROM t_order1 o JOIN t_order_item0 i ON o.order_id=i.order_id WHERE o.order_id IN (10, 11);
SELECT i.* FROM t_order1 o JOIN t_order_item1 i ON o.order_id=i.order_id WHERE o.order_id IN (10, 11);
SELECT i.* FROM t_order0 o JOIN t_order_item0 i ON o.order_id=i.order_id WHERE o.order_id IN (10, 11);
SELECT i.* FROM t_order1 o JOIN t_order_item1 i ON o.order_id=i.order_id WHERE o.order_id IN (10, 11);
# 设置绑定表
sharding.jdbc.config.sharding.binding-tables=t_order, t_order_item
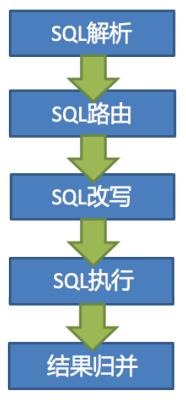
4.3. 我处理 SQL 的过程
4.3.1. SQL 解析
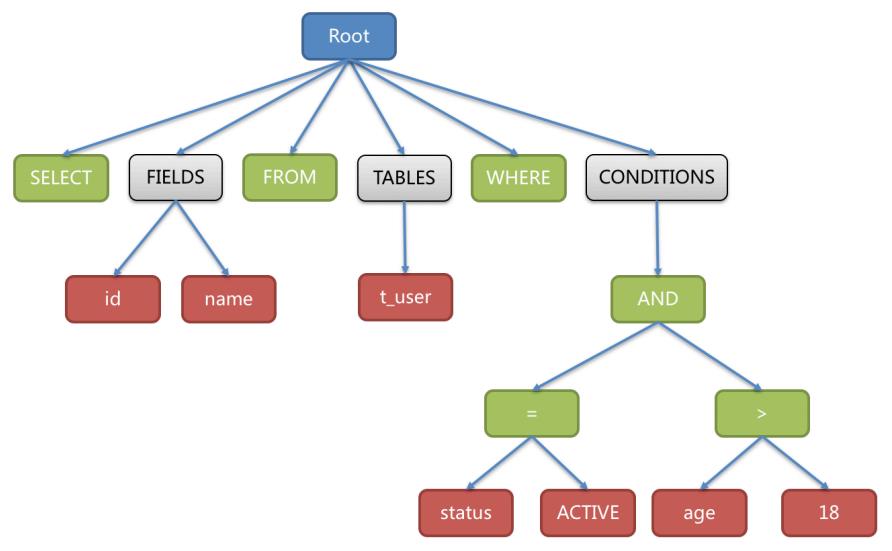
SELECT id, name FROM t_user WHERE status = 'ACTIVE' AND age > 18
4.3.2. SQL 路由
-- 若仅以 user_id 作为分片键对 t_user 进行分片,且分片算法为 user_id % 5,则以下 SQL 在一个数据源内会针对一个特定分片执行:
SELECT * FROM t_user WHERE user_id = 1009 --路由到 t_user4 执行
-- 若仅以 user_id 作为分片键对 t_user 进行分片,且分片算法为 user_id % 5,则以下 SQL 在一个数据源内会针对多个分片执行:
SELECT * FROM t_user WHERE user_id in (1002, 1003, 1009) --路由到 t_user2、t_user3、t_user4
SELECT * FROM t_user WHERE user_id > 1002 AND user_id <= 1004 --路由到 t_user3、t_user4
SELECT * FROM t_user WHERE user_id between 1002 and 1004 --路由到 t_user2、t_user3
-- 若仅以 user_id 作为分片键对 t_user 进行分片,且分片算法为 user_id % 5,则以下 SQL 在一个数据源内会针对所有的分片执行:
SELECT count(1) FROM t_user --路由到 t_user0、t_user1、t_user2、t_user3、t_user4
SELECT * FROM t_user where age < 18 --路由到 t_user0、t_user1、t_user2、t_user3、t_user4
4.3.3. SQL 改写
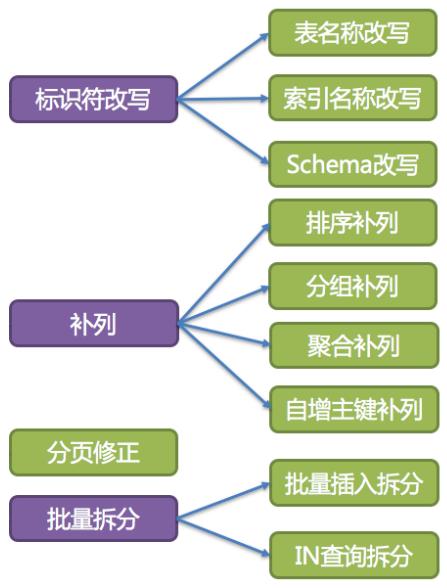
SELECT order_id FROM t_order WHERE order_id=1;
SELECT order_id FROM t_order1 WHERE order_id=1;
SELECT t_order.order_id FROM t_order AS t_order WHERE t_order.order_id=1 AND remarks='备注 t_order xxx';
SELECT t_order.order_id FROM t_order_1 AS t_order WHERE t_order.order_id=1 AND remarks='备注 t_order xxx';
SHOW COLUMNS FROM t_order FROM order_ds;
SELECT order_id, user_id FROM t_order ORDER BY user_id;
SELECT order_id FROM t_order0 ORDER BY user_id;
SELECT order_id, user_id FROM t_order0 ORDER BY user_id;
-- 补列前(结果集 o.* 中不包含排序键 order_item_id)
SELECT o.* FROM t_order o, t_order_item i WHERE o.order_id=i.order_id ORDER BY user_id, order_item_id;
-- 补列后(结果集 o.* 中包含排序键 order_item_id)
SELECT o.*, order_item_id FROM t_order o, t_order_item i WHERE o.order_id=i.order_id ORDER BY user_id, order_item_id;
-- 补列前(结果集 order_id 中不包含分组键 user_id)
SELECT order_id FROM t_order GROUP BY user_id
-- 补列后(结果集 order_id 中包含分组键 user_id)
SELECT order_id, user_id FROM t_order GROUP BY user_id
SELECT AVG(age) FROM t_user WHERE age>=18;
SELECT COUNT(age) AS AVG_DERIVED_COUNT, SUM(age) AS AVG_DERIVED_SUM FROM t_user WHERE age>=18;
SELECT COUNT(age) AS AVG_DERIVED_COUNT, SUM(age) AS AVG_DERIVED_SUM FROM t_user0 WHERE age>=18;
SELECT COUNT(age) AS AVG_DERIVED_COUNT, SUM(age) AS AVG_DERIVED_SUM FROM t_user1 WHERE age>=18;
SELECT COUNT(age) AS AVG_DERIVED_COUNT, SUM(age) AS AVG_DERIVED_SUM FROM t_user2 WHERE age>=18;
(
四(1)班总分 +
四(2)班总分 +
四(3)班总分 +
四(4)班总分
) / (
四(1)班人数 +
四(2)班人数 +
四(3)班人数 +
四(4)班人数
)
(
四(1)班平均分 +
四(2)班平均分 +
四(3)班平均分 +
四(4)班平均分
) / 4
INSERT INTO t_example (`field1`, `field2`) VALUES (10, 1);
INSERT INTO t_example (id, `field1`, `field2`) VALUES (snow_flake_id, 10, 1);
SELECT age FROM t_user ORDER BY age DESC LIMIT 1, 2;
SELECT age FROM t_user0 ORDER BY age DESC LIMIT 1, 2;
SELECT age FROM t_user1 ORDER BY age DESC LIMIT 1, 2;
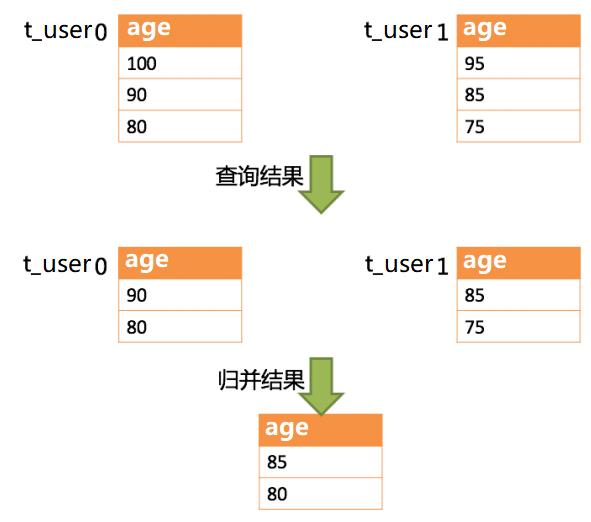
SELECT age FROM t_user ORDER BY age DESC LIMIT 0, 3;
SELECT age FROM t_user0 ORDER BY age DESC LIMIT 0, 3;
SELECT age FROM t_user1 ORDER BY age DESC LIMIT 0, 3;
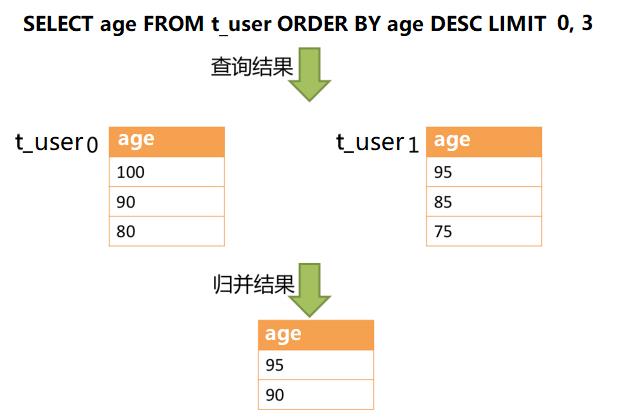
INSERT INTO t_order (order_id, xxx) VALUES (1, 'xxx'), (2, 'xxx'), (3, 'xxx');
INSERT INTO t_order0 (order_id, xxx) VALUES (2, 'xxx');
INSERT INTO t_order1 (order_id, xxx) VALUES (1, 'xxx'), (3, 'xxx');
SELECT * FROM t_order WHERE order_id IN (1, 2, 3);
SELECT * FROM t_order0 WHERE order_id IN (1, 2, 3);
SELECT * FROM t_order1 WHERE order_id IN (1, 2, 3);
SELECT * FROM t_order0 WHERE order_id IN (2);
SELECT * FROM t_order1 WHERE order_id IN (1, 3);
4.3.4. SQL 执行

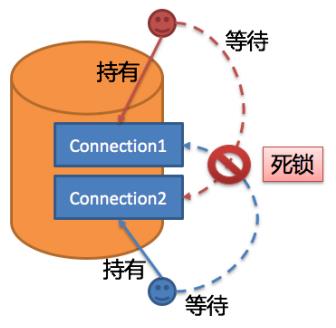
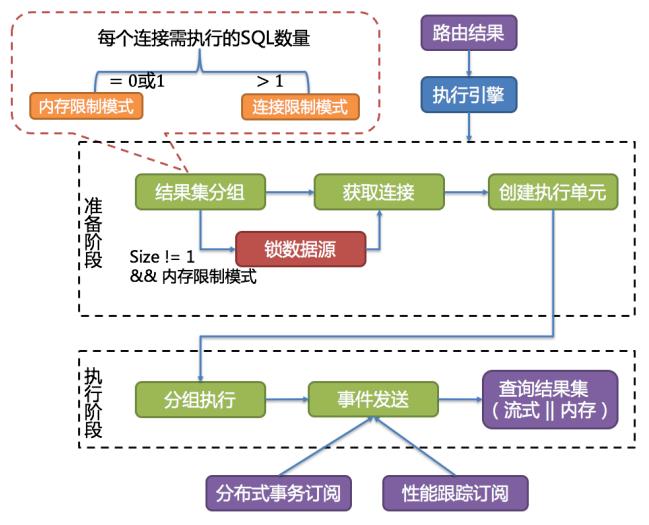
4.3.5. 结果归并
SELECT age FROM t_user where age < 18
SELECT age FROM t_user0 where age < 18
SELECT age FROM t_user1 where age < 18
SELECT age FROM t_user2 where age < 18
SELECT age FROM t_user order by age DESC
SELECT age FROM t_user0 order by age DESC
SELECT age FROM t_user1 order by age DESC
SELECT age FROM t_user2 order by age DESC
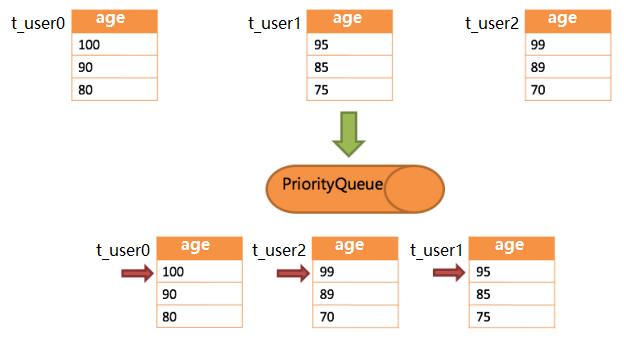
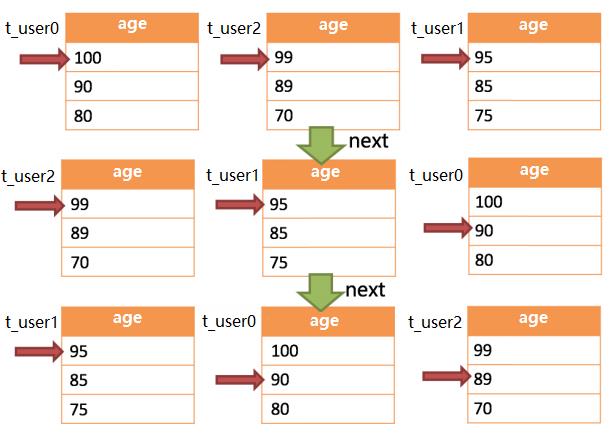
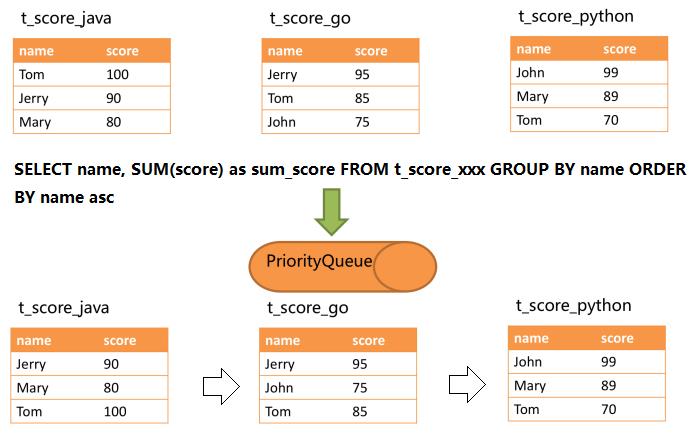
SELECT name, SUM(score) as sum_score FROM t_score GROUP BY name ORDER BY name asc;
SELECT name, SUM(score) as sum_score FROM t_score_java GROUP BY name ORDER BY name asc;
SELECT name, SUM(score) as sum_score FROM t_score_go GROUP BY name ORDER BY name asc;
SELECT name, SUM(score) as sum_score FROM t_score_python GROUP BY name ORDER BY name asc;
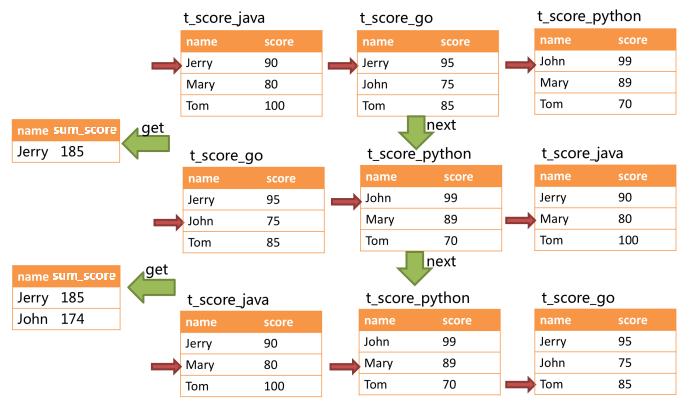
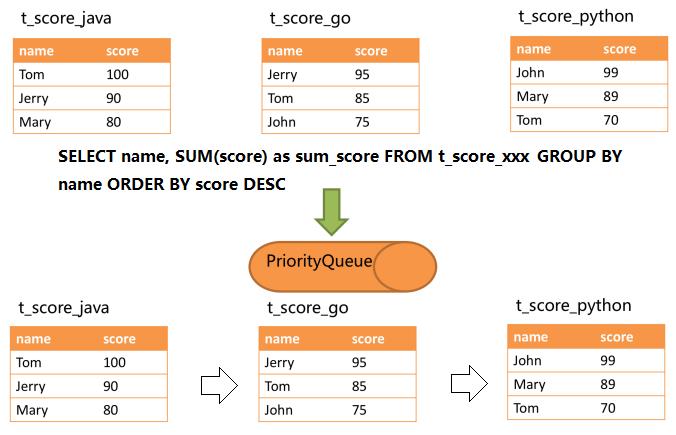
SELECT name, SUM(score) as sum_score FROM t_score GROUP BY name ORDER BY score DESC;
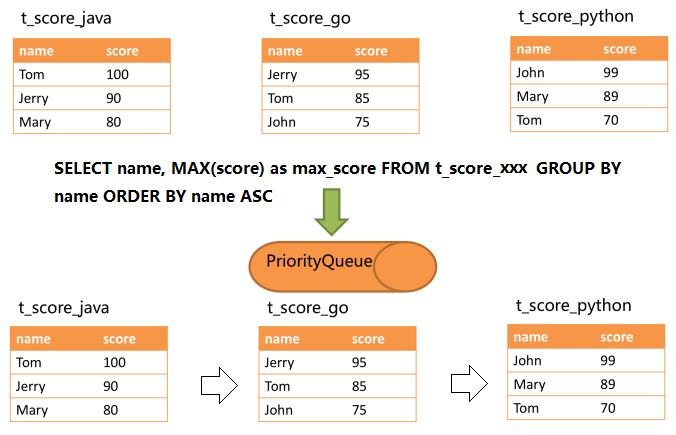
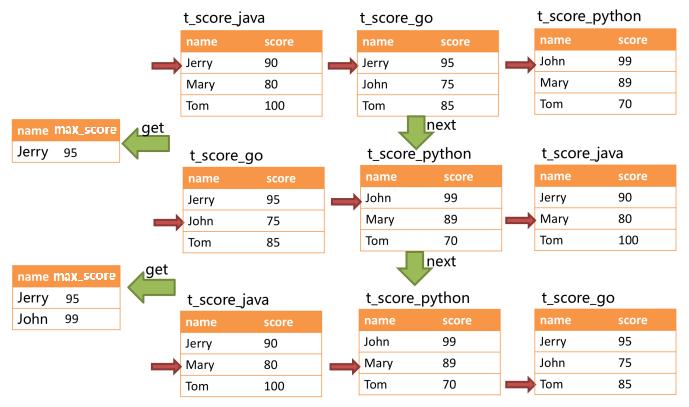
SELECT name, MAX(score) FROM t_score GROUP BY name;
--当 SQL 中只包含分组语句时,我会通过 SQL 改写,自动增加与分组项一致的排序项,这能够使得这句 SQL 的归并阶段从消耗内存的内存分组归并方式转化为流式分组归并方式
SELECT name, MAX(score) as max_score FROM t_score_java GROUP BY name ORDER BY name ASC;
SELECT name, MAX(score) as max_score FROM t_score_go GROUP BY name ORDER BY name ASC;
SELECT name, MAX(score) as max_score FROM t_score_python GROUP BY name ORDER BY name ASC;
SELECT * FROM t_order WHERE id > 100000 AND id <= 100010 ORDER BY id;
SELECT * FROM t_order WHERE id > 10000000 LIMIT 10;
5. 结束语
/**
* 所有的分片算法 interface 都包含该方法
*
* @param 所有可能的分片表(或分片库)名称
* @param 分片键的值
* @return 根据分片键的值,找到对应的分片表(或分片库)名称并返回
*/
Collection<String> doSharding(
Collection<String> availableTargetNames,
ComplexKeysShardingValue<T> shardingValue
);
最近整理一份面试资料《Java技术栈学习手册》,覆盖了Java技术、面试题精选、Spring全家桶、nginx、SSM、微服务、数据库、数据结构、架构等等。
获取方式:点“ 在看,关注公众号 Java后端 并回复 777 领取,更多内容陆续奉上。
推
荐
阅
读
1.
2.
3.
4.
5.
喜欢文章,点个
在看
以上是关于5W 字详解分库分表之 Sharding-JDBC 中间件的主要内容,如果未能解决你的问题,请参考以下文章
数据库分库分表中间件 Sharding-JDBC 源码分析 —— SQL 路由之分库分表配置
数据库分库分表中间件 Sharding-JDBC 源码分析 —— SQL 路由之分库分表路由