论文写作分析之五《融合类别特征扩展与N-gram子词过滤的fastText短文本分类》
Posted 征途黯然.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文写作分析之五《融合类别特征扩展与N-gram子词过滤的fastText短文本分类》相关的知识,希望对你有一定的参考价值。
[1] 参考论文信息
论文名称:《融合类别特征扩展与N-gram子词过滤的fastText短文本分类》
发布期刊:《小型微型计算机系统》
期刊信息:CSCD扩展

论文写作分析摘要:
从创新点上来说,本文是在文本预处理的时候,把文本的一元语法、二元语法、三元语法,用TFIDF、LDA、信息熵这三个基础手段提取过滤一下,然后再作为FastText模型的输入来跑。看起来好像没什么技术含量。
从我个人理解来看,用TFIDF、LDA、信息熵这三个基础手段无非就是特征提取,那为什么不用CNN来提取关键信息?或者使用注意力机制来提取突出特征?因为相对来说,深度学习的提取能力要比普通机器学习算法表现要好。所以我个人觉得,本文的工作还是比较有争议的。
【注】:其实,如果先用CNN来提取特征,然后再使用FastText模型,就等于直接使用CNN做文本分类了。因为CNN做文本分类原本就是会使用多个不同尺寸的卷积核的,和FastText就差不多了。
[2] 参考论文分解
【摘要部分】

分析:
主要是名词起的好。摘要部分我是再看完全文之后才看懂的。想发中文论文的话,起名字一定要高大上。
利用TDIDF和LDA来做特征提取,论文称为 “基于 TF-IDF的 LDA类别特征提取方法以提升类别特征质量”;利用信息熵来对一元语法、二元语法、三元语法做特征提取,论文称为 “基于词汇信息熵的 N-gram子词过滤方法过滤 N-gram子词中低类别区分贡献度子词”;把特征提取提取后的文本喂入FastText,论文称为 “构建更专注于高类别区分贡献度语义特征学习的 EF-fastText短文本分类模型”。
【注】:大家细品。
【引言部分】
分析:
比较常规,介绍了一下各个论文的工作和自己论文的主要贡献。
【TFIDF+LDA部分】
分析:
介绍了TF-IDF。然后给出了基于 TF-IDF的 LDA类别特征提取方法的处理流程图:
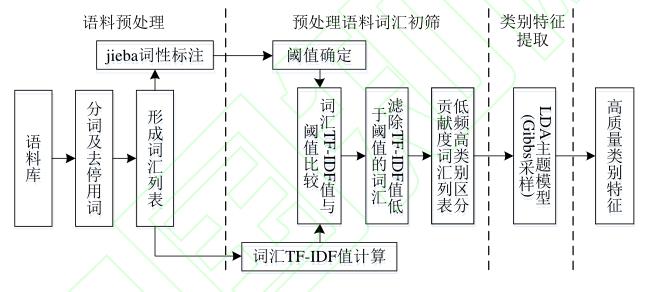
【注】:个人觉得TFIDF+LDA是不应该单独作为一个章节的。
【 N-gram的信息熵部分】
分析:
介绍了信息熵、多元语法这个概念,然后给出了基于词汇信息熵的 N-gram子词过滤方法的处理流程图:
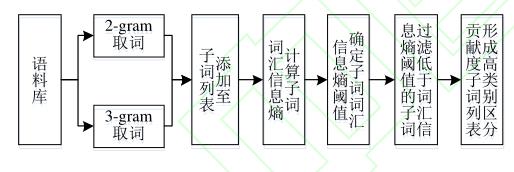
【注】:仍然觉得此处内容不应该单独作为一个章节。
【分类模型部分】
分析:
给出了使用了以上两种特征提取之后的FastText模型图:
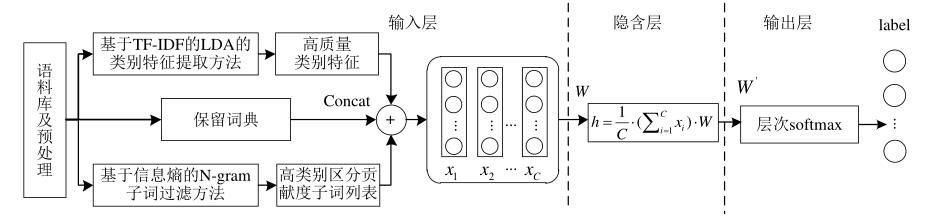
【注】:这FastText模型完全没有改动,只是前面加了特征提取。。。。
以上是关于论文写作分析之五《融合类别特征扩展与N-gram子词过滤的fastText短文本分类》的主要内容,如果未能解决你的问题,请参考以下文章
radar毫米波雷达-相机-激光雷达融合相关论文汇总(特征融合RPN融合弱监督融合决策融合深度估计跟踪)