三深度学习基础2(前反向传播;超参数)
Posted 满满myno
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了三深度学习基础2(前反向传播;超参数)相关的知识,希望对你有一定的参考价值。
前向传播与反向传播
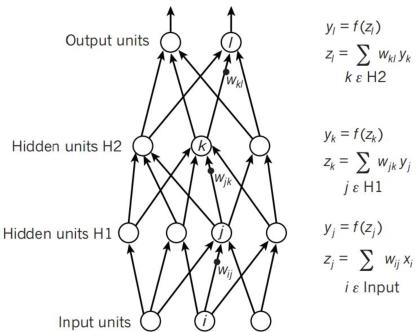
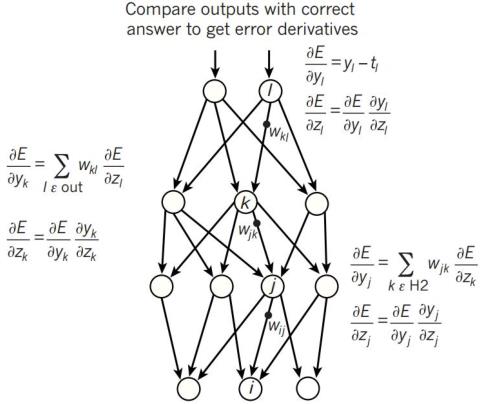
神经网络的输出 、卷积神经网络输出值以及Pooling 层输出值(主要作用是下采样)过程皆为比较简单的基础知识,在此不作详细赘述。
超参数
超参数:比如算法中的 learning rate (学习率)、iterations(梯度下降法循环的数量)、(隐藏层数目)、(隐藏层单元数目)、choice of activation function(激活函数的选择)都需要根据实际情况来设置,这些数字实际上控制了最后的参数和的值,所以它们被称作超参数。
如何寻找超参数的最优值
1、猜测和检查:根据经验或直觉,选择参数,一直迭代。
2、网格搜索:让计算机尝试在一定范围内均匀分布的一组值。
3、随机搜索:让计算机随机挑选一组值。
4、贝叶斯优化:使用贝叶斯优化超参数,会遇到贝叶斯优化算法本身就需要很多的参数的困难。
5、在良好初始猜测的前提下进行局部优化:这就是 MITIE 的方法,它使用 BOBYQA 算法,并有一个精心选择的起始点。由于 BOBYQA 只寻找最近的局部最优解,所以这个方法是否成功很大程度上取决于是否有一个好的起点。在 MITIE 的情况下,我们知道一个好的起点,但这不是一个普遍的解决方案,因为通常你不会知道好的起点在哪里。从好的方面来说,这种方法非常适合寻找局部最优解。稍后我会再讨论这一点。
6、最新提出的 LIPO 的全局优化方法。这个方法没有参数,而且经验证比随机搜索方法好。
超参数搜索一般过程
1、将数据集划分成训练集、验证集及测试集。
2、在训练集上根据模型的性能指标对模型参数进行优化。
3、在验证集上根据模型的性能指标对模型的超参数进行搜索。
4、步骤 2 和步骤 3 交替迭代,最终确定模型的参数和超参数,在测试集中验证评价模型的优劣。
其中,搜索过程需要搜索算法,一般有:
网格搜索、随机搜索、启发式智能搜索、贝叶斯搜索。
以上是关于三深度学习基础2(前反向传播;超参数)的主要内容,如果未能解决你的问题,请参考以下文章