下一代英伟达H100 GPU发布时,国产芯片能追上吗?
Posted OneFlow深度学习框架
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了下一代英伟达H100 GPU发布时,国产芯片能追上吗?相关的知识,希望对你有一定的参考价值。

撰文|吕坚平
继2020年GTC(GPU技术大会)发布A100 GPU,时隔两年,英伟达如所预期在今年(2022年)上GTC公布了媒体形容为“核弹”GPU的H100。
2020年GTC后,国内很多GPU 初创公司争先恐后的宣称能超赶A100;2021年GTC上英伟达发布的DPU也让很多芯片精英竞相创业投入DPU开发,谓为风潮;今年的H100会造成什么样的回响,且让我们拭目以待。
媒体已经有很多关于H100的介绍,对H100的技术进行详细报道,例如芯东西标题为《800亿晶体管核弹GPU架构深入解读,又是“拼装货”?》,以及半导体行业观察的《深入解读英伟达“HOPPER”GPU 架构》,这里就不再赘述。这篇文章目的是要探讨H100背后的技术思路及市场策略对中国的启发,是否值得国内业界完全跟随效仿?到2024年的GTC,H100的下一代问世,我们是不是又更落后了?
1
解读英伟达
英伟达这些年一直致力于宣称,在后摩尔时代,其新产品还是可以超越传统摩尔定律,为行业提供相对于两年前产品,两倍以上的性能提升,淡化功耗增加的代价。每代产品之间(以Turing、Ampere、Hopper为例)基本上寄希望于四个性能提升潜力来达成目标:1) 工艺提升为频率带来1.5倍以内提升;2)在不计功耗成本下,计算单元数倍增;3) 领域专用架构(Domain-Specific Architecture,DSA)设计带来性能加倍,如Turing的Tensor Core, Ampere的硬件Sparsity, Hopper的Transformer Engine;4)引入新的数据精度类型,用低精度来代替高精度单元比如Turing的INT4, Ampere的TF32, Hopper的FP8 带来加倍性能。
综合这些因子,理论上,英伟达的代际产品之间有1.5 x 2 x 2 x 2 = 12,也就是一个数量级的性能提升空间。然而,受限于后摩尔定律时代的现实及功耗墙的限制,性能提升总远小于一个数量级。运用这个思路,英伟达用以下图示,宣称H100性能达到A100的六倍:
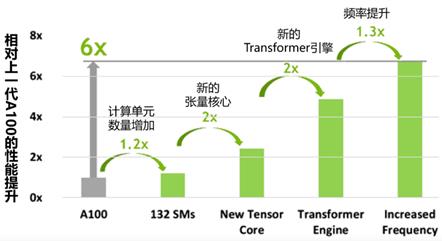
H100相对于上一代A100的性能提升
然而,要注意的是,这六倍性能提升是峰值中的峰值,特例中的特例,并非是一般情况下的平均性能。原因在于,这是在跑Transformer之类网络的性能峰值,而且只有在数据完全能以FP8来表示的情况下才会发生。更何况,在后摩尔定律时代,谈到性能,我们一定还要考虑功耗,性能功耗比是更重要指标。
除此之外,我们还应该排除工艺带来的性能功耗比提升,才能确切了解H100相较于A100,架构的创新贡献了多少性能功耗比。此外,现实中,英伟达产品的很多创新需要时间被行业消化,有些新功能需要时间被市场接受,最终的普适效果不见得会发生,也不会真的有那么大影响。具体来说,大部分客户在迭代时会先做平移,也就是将上代代码直接移到下代。由下表可以看出, H100相较于A100,峰值算力的提升在一般状况下应该可以达到3.2倍。
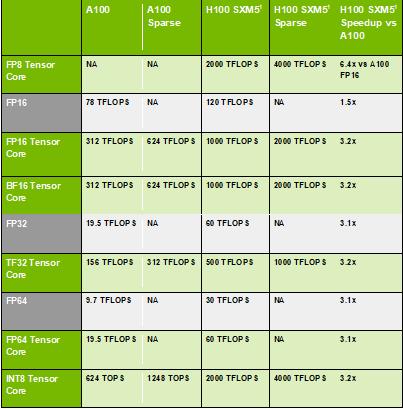
H100 VS A100
假设台积电的N7到N4工艺进步使得性能功耗比提升了26%,那么H100相较于A100,在一般状况下,H100在性能功耗比上提升了3.2 x 350/700 - 1 = 60%, 而滤除工艺加持,纯架构创新只贡献 (3.2 x 350) / (1.26 x 700) -1 ≈ 30% 的峰值算力效能提升。
那么,客户到最后要多付出多少代价换取60% 性能功耗比的提升?我们还不知道最终H100系列产品性价比有没有进步,但已知的是,这次GTC并没有透露基于H100的DGX价格,也不再重复那句名言 “你买的越多,省得也越多“ (“The more you buy, the more you save”)。
2
技术路线分析
我们接下来分析H100几个重要技术路线。
GPU走DSA路线是从H100开始的吗?
芯东西的报道结尾提到H100设计是英伟达的GPU朝DSA(Domain Specific Architecture,领域专用架构)的方向发展的开始。然而,GPU传统上就一直接纳DSA,并非从H100开始,这也是英伟达能从容应付DSA挑战者一大制胜关键。让一般人甚至包括提出DSA的大师John Hennessey 及David Patterson 教授都没有理解的是,GPU架构师向来的理念都是融合DSA于通用架构。但他们是在核心,而不是在芯片上层异构化。这一点可以用以下图来说明。
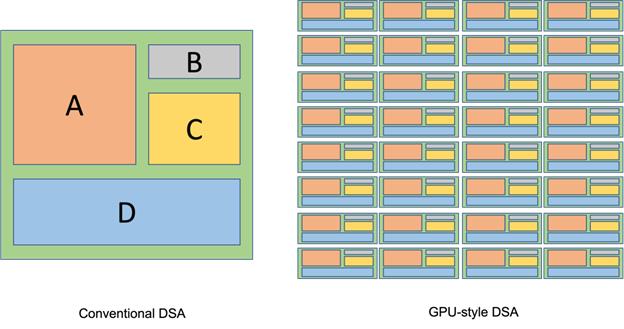
传统DSA架构图(左)GPU融合DSA架构的示意图(右)
图左是一般人认同的DSA架构示意图,谷歌的TPU AI加速芯片大致就是这个样子。图右是GPU融合DSA架构的示意图,如,从早期的纹理单元(Texture Unit),特殊函数单元 (Special Function Unit), 到最近的张量核心(Tensor Core)及光追核心(RT Core)。这些例子有些共通之处:
1.一个DSA设计的硬件资源平均分布到每个运算单元,以特殊指令或是程序调用的方式引用,成为各单元通用计算核心的一部分,不在芯片最上层成为一个独立处理器,而是原可编程生态的自然延伸,不影响原先的编程方式。
2.适配于市场上的成熟应用,譬如说纹理运算之于绝大部分图形应用,张量计算之于几乎所有AI算法,而且资源投入多少,可以基于应用的频率,不会被过度闲置。
我们可以将GPU这种融合DSA设计的方式称为“DSA通用化”,在提升效能的同时,持续强化通用优势。这可以解释,为什么号称为AI专门设计的芯片,包括TPU在内,都无法碾压GPU,而且在通用性上彻底对GPU称臣。
这次英伟达在H100上加了为Transformer类型网络优化的Transformer Engine 以及相对应的FP8数据格式,与针对Dynamic Programing 优化的DPX 特殊指令集,可以说是延续了DSA 通用化的传统。就Transformer Engine 来说,Transformer类型网络已公认能通用到各样应用领域,跳脱源起的自然语言处理范畴,而Transformer Engine 也是配置到Tensor Core中,针对网络层数据做统计分析,未来有可能可以通用化到其他类型网络。
对DPX来说,英伟达也列举了基因排序以及机器人路径规划等应用。与先前针对市场成熟应用DSA加速器不同的是,Transformer Engine 及 DPX 的应用范围在短期内还是比较小,也尚未被市场广泛接受,英伟达这次走在了市场之前。这是不是GPU未来DSA通用化的趋势,尚未得知。对天数智芯来说,我们愿意跟国内客户密切合作,走出一条适配国内市场又兼具国际技术视野的DSA通用化道路。
H100以“非同步执行”(Asynchronous Execution)提升通用计算效率
H100延伸A100开始的非同步执行路线,提升通用计算效率,增加Tensor Memory Accelerator(TMA)处理芯外内存及核心内共享记忆体(SMEM)或是 SMEM之间搬移大张量的问题。SMEM附属于一个SM(Streaming Multiprocessor,英伟达的计算单元)。现在为了能支持SMEM之间数据搬移,以及整合成一块SMEM,SM之间现在也有了一个互联网络。
因为AI算法的多样性及快速演进,鱼与熊掌不可兼得,我们不得不走向通用,而舍弃专用的好处。在我看来,非同步执行技术方向的终极目标是要填补通用与专用之间的效能差距,使得鱼与熊掌可以兼得,让GPU的通用计算效率更接近ASIC (Application- Specific IC)中常见的专用流水线。
ASIC这个字眼现在几乎已经完全被DSA掩盖,我采用ASIC,而不是DSA,是因为后者不一定以流水线为主。专用流水线的特色是在把数据从生产者(Producer)传送到消费者(Consumer)的同时,生产者及消费者还是继续工作。
我将这个技术方向更强化为“计算图形化”,因为图形流水线,如下图左边所示,是专用流水线的代表作。虽然中间数个节点已被跑在通用算力池的着色器(Shader)程序取代,它的流水线结构依然存在。非同步执行以不浪费时间等待数据传输,来接近专用流水线的效率。面对后摩尔定律时代的到来,通用计算借鉴ASIC风格的专用流水线精神,是条必须走下去的路线。
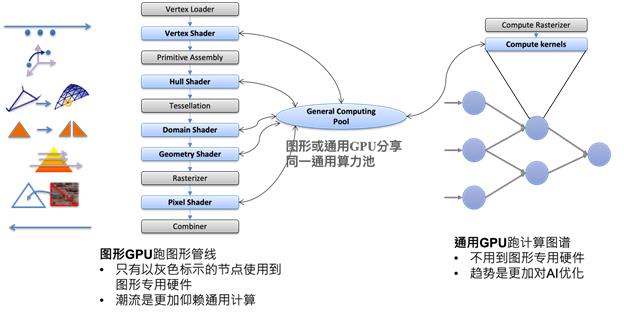
图形管线
传统图形无法充分利用H100 的AI算力
H100 SMX版本的66个TPC,以及PCIe版本的57个TPC中,只有两个TPC具备图形功能。这个设计或许是因为,虽然图形专用硬件的面积在1个TPC中不算大,但乘上三十倍左右之后,在面积及功耗已经都爆表的状况下,也是难以消受。
因为H100 的图形与通用计算如此不成比例,我们可以称H100为通用GPU。可想而知,像H100这样级别的通用GPU要有与之匹配的图形能力,前提是图形必须在功能不减,性能不降的条件下,充分运用AI算力,并简化图形专用硬件。
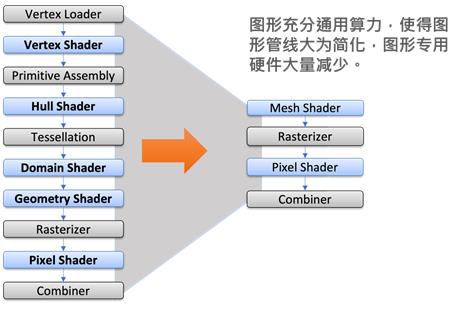
利用mesh shader简化图形
随着图形流水线多个节点被跑在通用算力池的着色器程序取代,为什么不减少几个着色器节点?如上图所示,先进图形标准中,崭新的、更加利用计算功能的mesh shader 可以取代从vertex shader 到 geometry shader的着色器,从而在不减功能的前提下,将图形流水线节点数大量减少,并移除一些连接节点的专用硬件。性能还可能因为mesh shader 拥有的弹性,而有所提升。这是简化图形的第一步。
在英伟达的元宇宙/数字孪生蓝图中,H100 通用GPU系列与RTX 图形GPU 各司其职。然而图形GPU 需要通用计算加持才能支持数字孪生所需要的物理模拟运算,更需要AI做超分及为光追所需要的降噪。反而言之,通用GPU需要渲染才能广泛地从事基于AI的内容生成及三维建模。
我的看法是,通用与图形GPU应该融合。但H100没这么做,原因是作为通用GPU的H100已经高度为AI优化。更正确的说法是,张量计算已经由协同处理的角色,演变为通用GPU的算力中心,因为AI以张量计算为主。
然而传统的图形渲染着色器算法并非基于张量。这意味着要让以支援张量计算为主的通用GPU实现匹配的图形,唯一的途径就是要能够融合图形与AI,使得图形渲染着色器必须也采用基于AI的算法。我称该走向为“图形计算化”。
这一点,英伟达作为图形显卡市场领导者,是很难办到的,因为着色器算法的选择及编写在于图形应用开发者。对于天数智芯来说,我们做图形的目标是支援元宇宙/数字孪生的云端渲染,有机会与客户开发属于中国的生态,促使图形应用开发都以AI为基础,而使得为张量计算优化的通用GPU也能在图形领域大显身手。
3
深层合作与良性竞争的大联盟
大家最关心的话题是,我们如何接近甚至超赶英伟达?就如同前文所分析的,在一般的状况下,滤除工艺及功耗等因子,H100架构上的创新相较于A100贡献了30%左右效能提升。我们要能在2024年超赶英伟达,走不一样的路,在技术路线上,我们应该:
1.与国内客户合作,做出适合国内市场的DSA通用化来持续通用优势
2.以计算图形化,提升通用计算效能,媲美图形流水线
3.与国内生态合作,借由图形计算化,直接跨接先进图形标准,并使专精于张量计算的通用GPU可以在图形领域大显身手
我们也不能忽略“开发全自主、技术广通用”在GPU赛道的重要性。只有坚持自主创新,从底层硬件到上层软件独立设计开发,不走购买国外GPU IP的捷径,才能确保完全自主知识产权,打破国内长期作为国外IP代理的局面。也只有全自研的架构、计算核、指令集及基础软件栈,才能立即响应快速变化的市场需求,实现持续自主发展,完全不受国外IP制约。而且针对客户要求的不同技术层面开放性测试,才能从根本上保障了客户使用安全、信息安全。
就如同The Information 在题为“China’s 'Little Nvidia' Has a Big Secret: Its Homegrown AI Chip Isn’t”的报导中引述我的话,“只有一行一行地写代码来实现GPU的核心功能,才是走向自主的唯一途径“。有了开发全自主,技术广通用的GPU芯片之后,我们也要能在测试、客户适配、稳定供货,成功量产并实现规模应用等方面与英伟达对标,流片及点亮等只能说是初步站上赛道。
最后,我们还要探讨借鉴英伟达的根本意义在哪里。我们是要看到一家公司,在算力上, 席卷芯片、板卡、服务器、小集群、大集群到数据中心甚至算力中心, 在网络上, 涵盖芯间、片间、机箱间、到集群间互联,以及在应用上,坐拥芯片实力,广及医药、互联网、工厂、自动驾驶、生物医药吗?
中国所需要的,或许是个在技术深度及广度上,足以与英伟达相比拟,以深层合作及良性竞争为基调的大联盟。

吕坚平,天数智芯首席技术官(CTO)。毕业于耶鲁大学并获计算机科学博士学位,曾在英伟达、英特尔、三星等跨国半导体巨头担任要职,是GPU领域的著名专家。
(本文经授权后发布。原文:
https://mp.weixin.qq.com/s/rtO8PxRj08GVimT3bfbplA)
其他人都在看
点击“阅读原文”,欢迎下载体验OneFlow v0.7.0最新版本

以上是关于下一代英伟达H100 GPU发布时,国产芯片能追上吗?的主要内容,如果未能解决你的问题,请参考以下文章
英伟达首席科学家:5nm实验芯片用INT4达到INT8的精度,每瓦运算速度可达H100的十倍...
英伟达首席科学家:5nm实验芯片用INT4达到INT8的精度,每瓦运算速度可达H100的十倍...