英伟达首席科学家:5nm实验芯片用INT4达到INT8的精度,每瓦运算速度可达H100的十倍...
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了英伟达首席科学家:5nm实验芯片用INT4达到INT8的精度,每瓦运算速度可达H100的十倍...相关的知识,希望对你有一定的参考价值。
梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
32位与16位格式的混合精度训练,正是当前深度学习的主流。
最新的英伟达核弹GPU H100,刚刚添加上对8位浮点数格式FP8的支持。
英伟达首席科学家Bill Dally现在又表示,他们还有一个“秘密武器”:
在IEEE计算机运算研讨会上,他介绍了一种实验性5nm芯片,可以混合使用8位与4位格式,并且在4位上得到近似8位的精度。
目前这种芯片还在开发中,主要用于深度学习推理所用的INT4和INT8格式,对于如何应用在训练中也在研究了。
相关论文已发表在2022 IEEE Symposium on VLSI Technology上。

新的量化技术
降低数字格式而不造成重大精度损失,要归功于按矢量缩放量化(per-vector scaled quantization,VSQ)的技术。
具体来说,一个INT4数字只能精确表示从-8到7的16个整数。
其他数字都会四舍五入到这16个值上,中间产生的精度损失被称为量化噪声。
传统的量化方法给每个矩阵添加一个缩放因子来减少噪声,VSQ则在这基础之上给每个向量都添加缩放因子,进一步减少噪声。
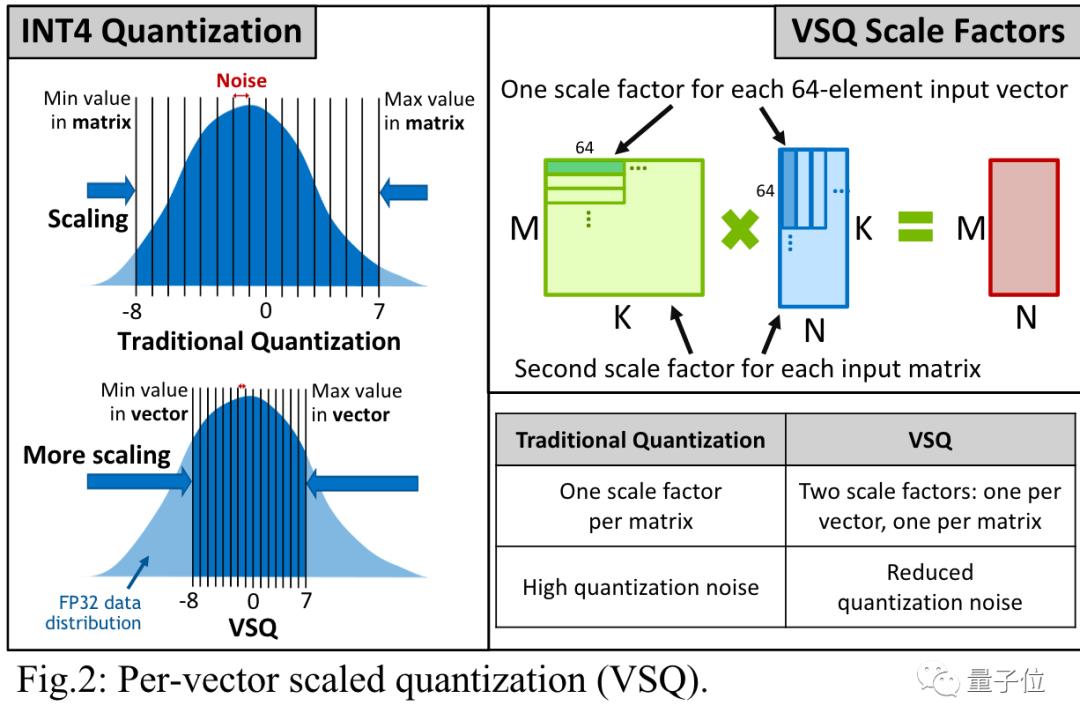
关键之处在于,缩放因子的值要匹配在神经网络中实际需要表示的数字范围。
英伟达研究人员发现,每64个数字为一组赋予独立调整过的缩放因子可以最小化量化误差。
计算缩放因子的开销可以忽略不计,从INT8降为INT4则让能量效率增加了一倍。
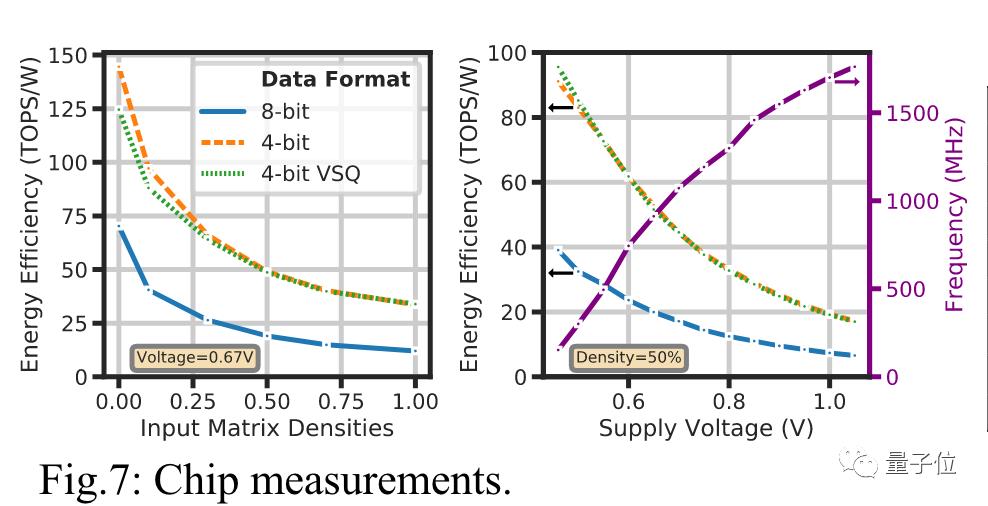
Bill Dally认为,结合上INT4计算、VSQ技术和其他优化方法后,新型芯片可以达到Hopper架构每瓦运算速度的10倍。
还有哪些降低计算量的努力
除了英伟达之外,业界还有更多降低计算量的工作也在这次IEEE研讨会上亮相。
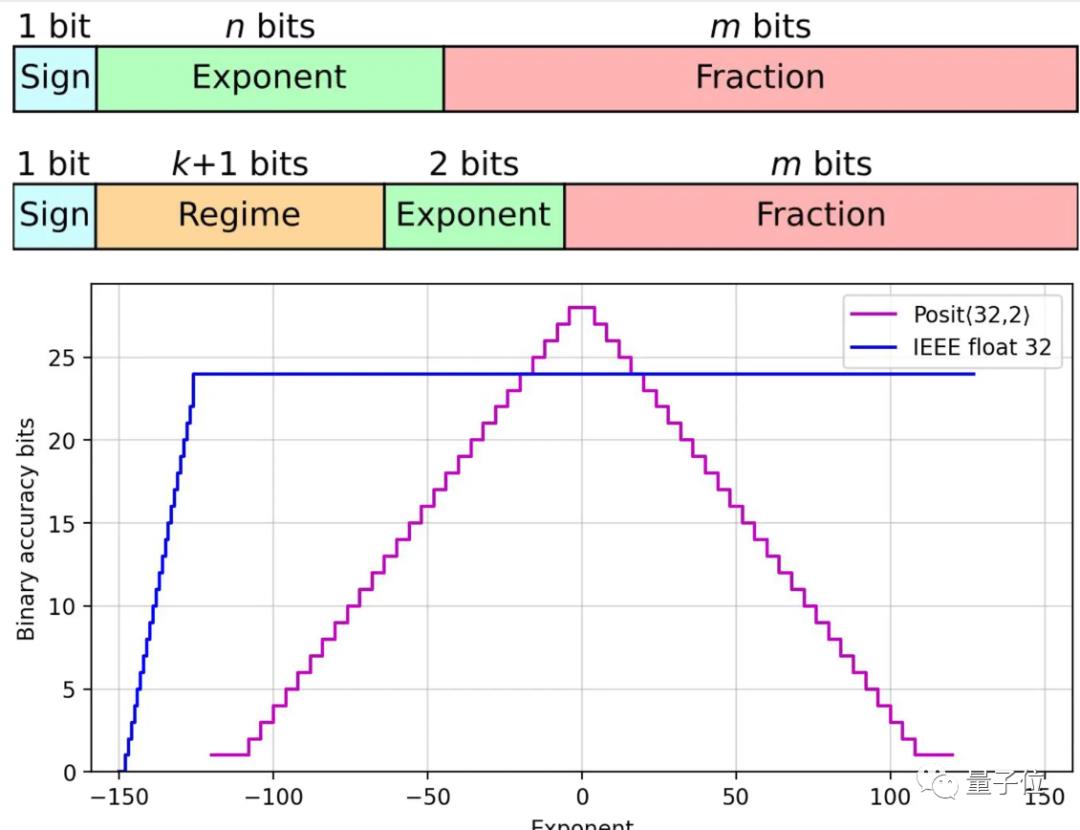
马德里康普顿斯大学的一组研究人员设计出基于Posits格式的处理器核心,与Float浮点数相比准确性提高了多达4个数量级。
Posits与Float相比,增加了一个可变长度的Regime区域,用来表示指数的指数。
对于0附近的较小数字只需要占用两个位,而这类数字正是在神经网络中大量使用的。
适用Posits格式的新硬件基于FPGA开发,研究人员发现可以用芯片的面积和功耗来提高精度,而不用增加计算时间。
ETH Zurich一个团队的研究基于RISC-V,他们把两次混合精度的积和熔加计算(fused multiply-add,FMA)放在一起平行计算。
这样可以防止两次计算之间的精度损失,还可以提高内存利用率。
FMA指的是d = a * b + c这样的操作,一般情况下输入中的a和b会使用较低精度,而c和输出的d使用较高精度。
研究人员模拟了新方法可以使计算时间减少几乎一半,同时输出精度有所提高,特别是对于大矢量的计算。
相应的硬件实现正在开发中。

巴塞罗那超算中心和英特尔团队的研究也和FMA相关,致力于神经网络训练可以完全使用BF16格式完成。
BF16格式已在DALL·E 2等大型网络训练中得到应用,不过还需要与更高精度的FP32结合,并且在两者之间来回转换。
这是因为神经网络训练中只有一部分计算不会因BF16而降低精度。
最新解决办法开发了一个扩展的格式BF16-N,将几个BF16数字组合起来表示一个数,可以在不显著牺牲精度的情况下更有效进行FMA计算
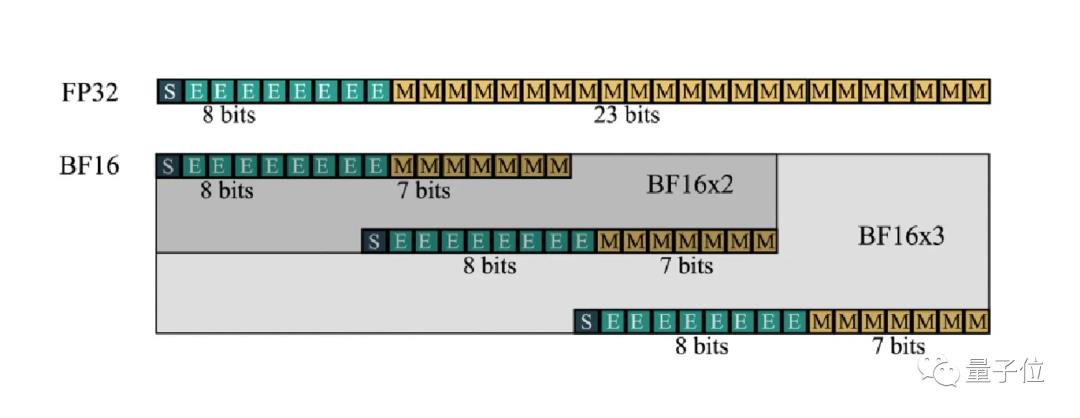
关键之处在于,FMA计算单元的面积只受尾数位影响。
比如FP32有23个尾数位,需要576个单位的面积,而BF16-2只需要192个,减少了2/3。
另外这项工作的论文题目也很有意思,BF16 is All You Need。

参考链接:
[1]https://spectrum.ieee.org/number-representation
[2]https://ieeexplore.ieee.org/document/9830277
[3]https://ieeexplore.ieee.org/document/9823406
以上是关于英伟达首席科学家:5nm实验芯片用INT4达到INT8的精度,每瓦运算速度可达H100的十倍...的主要内容,如果未能解决你的问题,请参考以下文章
英伟达发布支持L5自动驾驶芯片Orin,中国自动驾驶朋友圈扩大