自动文摘评测方法:Rouge-1Rouge-2Rouge-LRouge-S 评测指标
Posted Terry_dong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自动文摘评测方法:Rouge-1Rouge-2Rouge-LRouge-S 评测指标相关的知识,希望对你有一定的参考价值。
目录
前言
最近在看自动文摘的论文,之前对Rouge评测略有了解,为了更好的理解Rouge评测原理,查了些资料,并简单总结。
关于Rouge
Rouge(Recall-Oriented Understudy for Gisting Evaluation),是评估自动文摘以及机器翻译的一组指标。它通过将自动生成的摘要或翻译与一组参考摘要(通常是人工生成的)进行比较计算,得出相应的分值,以衡量自动生成的摘要或翻译与参考摘要之间的“相似度”。
Rouge-1、Rouge-2、Rouge-N
论文[3]中对Rouge-N的定义是这样的:
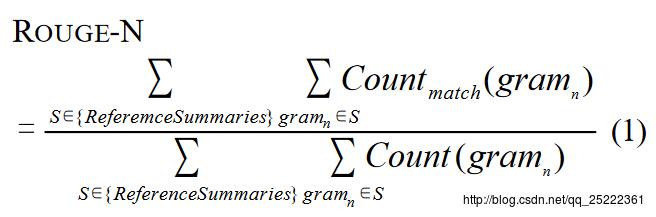
分母是n-gram的个数,分子是参考摘要和自动摘要共有的n-gram的个数。直接借用文章[2]中的例子说明一下:
自动摘要Y(一般是自动生成的):
the cat was found under the bed
参考摘要,X1 gold standard ,人工生成的):
the cat was under the bedsummary的1-gram、2-gram如下,N-gram以此类推:
| # | 1-gram | reference 1-gram | 2-gram | reference 2-gram |
| 1 | the | the | the cat | the cat |
| 2 | cat | cat | cat was | cat was |
| 3 | was | was | was found | was under |
| 4 | found | under | found under | under the |
| 5 | under | the | under the | the bed |
| 6 | the | bed | the bed | |
| 7 | bed | |||
| coun | 7 | 6 | 6 | 5 |
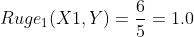 分子是待评测摘要和参考摘要都出现的1-gram的个数,分子是参考摘要的1-gram个数。(其实分母也可以是待评测摘要的,但是在精确率和召回率之间,我们更关心的是召回率Recall,同时这也和上面ROUGN-N的公式相同)
分子是待评测摘要和参考摘要都出现的1-gram的个数,分子是参考摘要的1-gram个数。(其实分母也可以是待评测摘要的,但是在精确率和召回率之间,我们更关心的是召回率Recall,同时这也和上面ROUGN-N的公式相同)
同样 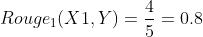
Rouge-L
L即是LCS(longest common subsequence,最长公共子序列)的首字母,因为Rouge-L使用了最长公共子序列。Rouge-L计算方式如下图:
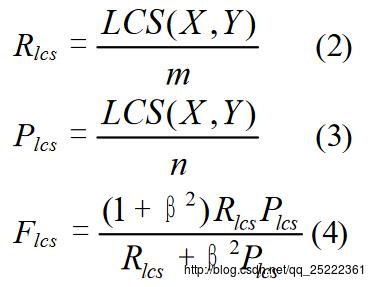
其中 是X和Y的最长公共子序列的长度,m,n分别表示参考摘要和自动摘要的长度(一般就是所含词的个数),
是X和Y的最长公共子序列的长度,m,n分别表示参考摘要和自动摘要的长度(一般就是所含词的个数),
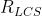 ,
,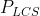 分别表示召回率和准确率。最后的
分别表示召回率和准确率。最后的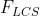 即是我们所说的Rouge-L。在DUC中,
即是我们所说的Rouge-L。在DUC中,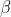 被设置为一个很大的数,所以
被设置为一个很大的数,所以 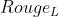 几乎只考虑了,与上文所说的一般只考虑召回率对应。
几乎只考虑了,与上文所说的一般只考虑召回率对应。
Rouge-L的改进版 — Rouge-W
论文[3]针对Rouge-L提出了一个问题:

图中,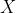 是参考文摘,
是参考文摘,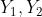 是两个待评测文摘,明显
是两个待评测文摘,明显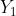 要优于
要优于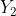 ,因为可以和参考摘要连续匹配,但是
,因为可以和参考摘要连续匹配,但是 针对这个问题论文作者提出了改进的方案—加权最长公共子序列(Weighted Longest Common Subsequence)。关于Rouge-W的详细内容请参看论文[3]。
针对这个问题论文作者提出了改进的方案—加权最长公共子序列(Weighted Longest Common Subsequence)。关于Rouge-W的详细内容请参看论文[3]。
Rouge-S
即使用了skip-grams,在参考摘要和待评测摘要进行匹配时,不要求gram之间必须是连续的,可以“跳过”几个单词,比如skip-bigram,在产生grams时,允许最多跳过两个词。比如“cat in the hat”的 skip-bigrams 就是 “cat in, cat the, cat hat, in the, in hat, the hat”.
多参考摘要的情况
某一个人的对谋篇文档的摘要也不一定准确,所以针对一篇文档,标准数据集一般有多个参考摘要(DUC数据集就有4个)。针对这个问题,论文作者也提出了多参考摘要的解决方案:

论文中的详细描述如下:
This procedure is also applied to computation of ROUGE-L (Section 3), ROUGE-W (Section 4), and ROUGE-S (Section 5). In the implementation, we use a Jackknifing procedure. Given M references, we compute the best score over M sets of M-1 references. The final ROUGE-N score is the average of the M ROUGE-N scores using different M-1 references.
我的理解是由M个参考摘要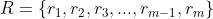 产生M个集合
产生M个集合
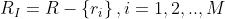
然后计算出每个集合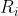 的最高分数
的最高分数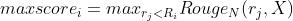
最终
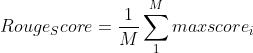
本博客参考:
[1].https://en.wikipedia.org/wiki/ROUGE_(metric)
[2].What is ROUGE and how it works for evaluation of summaries?
[3].ROUGE:A Package for Automatic Evaluation of Summaries
以上是关于自动文摘评测方法:Rouge-1Rouge-2Rouge-LRouge-S 评测指标的主要内容,如果未能解决你的问题,请参考以下文章