Elasticsearch:使用新的 field API 简化 Painless 语法和文档字段访问 - Elastic Stack 8.1
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:使用新的 field API 简化 Painless 语法和文档字段访问 - Elastic Stack 8.1相关的知识,希望对你有一定的参考价值。
在 8.1 中,我们引入了从 Painless 脚本轻松访问文档中的字段的功能。 你可以使用新的 field API 访问文档以自动处理缺失值,而不是使用需要逻辑来检查字段及其值是否存在的 doc 变量方法。
字段 API 返回一个字段对象,该对象对具有多个值的字段进行迭代,通过 get(<default_value>) 方法以及类型转换和辅助方法提供对基础值的访问。 它还返回你指定的默认值,无论该字段是否存在或是否具有文档的任何值。 这意味着字段 API 可以处理缺失值,而无需额外的逻辑。
field(‘name’).get(<default_value>)为了使脚本更具可读性,你还可以使用新的 $ 快捷方式。 确保包含 $ 符号、字段名称和在字段不存在时要获取的默认值:
$(‘field’, <default_value>)借助这些增强的功能和简化的语法,你可以编写更短且更易于阅读的脚本。 例如,以下脚本使用过时的语法:
if (!doc.containsKey('myfield') || doc['myfield'].empty) return "unavailable" else return doc['myfield'].value 使用 field API,你现在可以更简洁地编写相同的脚本,而无需额外的逻辑来确定字段是否存在,然后再对它们进行操作:
$(‘myfield’, ‘unavailable’)展示
在下面,我们来通过一些例子来进行展示。我们首先选择在之前的文章 “Elasticsearch:Painless scripting 编程实践” 文章中的例子来进行展示。
PUT employee/_bulk?refresh
"index":"_id": 1
"salary" : 5000, "bonus": 500, "@timestamp" : "2021-02-28", "weight": 60, "height": 175, "name" : "Peter", "occupation": "software engineer","hobbies": ["dancing", "badminton"]
"index":"_id": 2
"salary" : 6000, "bonus": 500, "@timestamp" : "2020-02-01", "weight": 50, "name" : "John", "occupation": "sales", "hobbies":["singing", "volleyball"]
"index":"_id": 3
"salary" : 7000, "bonus": 600, "@timestamp" : "2019-03-01", "weight": 55, "height": 172, "name" : "mary", "occupation": "manager", "hobbies":["dancing", "tennis"]
"index":"_id": 4
"salary" : 8000, "bonus": 700, "@timestamp" : "2018-02-28", "weight": 45, "height": 166, "name" : "jerry", "occupation": "sales", "hobbies":["biking", "swimming"]
"index":"_id": 5
"salary" : 9000, "bonus": 800, "@timestamp" : "2017-02-01", "weight": 60, "height": 170, "name" : "cathy", "occupation": "manager", "hobbies":["climbing", "jigging"]
"index":"_id": 6
"salary" : 7500, "bonus": 500, "@timestamp" : "2017-03-01", "weight": 40, "height": 158, "name" : "cherry", "occupation": "software engineer", "hobbies":["basketball", "yoga"]在上面,我需要特别指出的是针对 id 为 2 的文档:
"salary" : 6000, "bonus": 500, "@timestamp" : "2020-02-01", "weight": 50, "name" : "John", "occupation": "sales", "hobbies":["singing", "volleyball"]
我特别有意地省去了它的 height 字段,也即其它的文档都含有这个 height 字段。
GET employee/_doc/2
"_index" : "employee",
"_id" : "2",
"_version" : 1,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" :
"salary" : 6000,
"bonus" : 500,
"@timestamp" : "2020-02-01",
"weight" : 50,
"name" : "John",
"occupation" : "sales",
"hobbies" : [
"singing",
"volleyball"
]
我们接下来想得到这些员工的 BMI 值。我们可以参考之前文章 “Elasticsearch:Painless scripting 编程实践” 中介绍的方法来创建一个 scripted field:
GET employee/_search
"script_fields":
"BMI":
"script":
"source": """
double height = (float)doc['height'].value/100.0;
return doc['weight'].value / (height*height)
"""
如果我们运行上面的代码,我们会发现如下的错误信息:
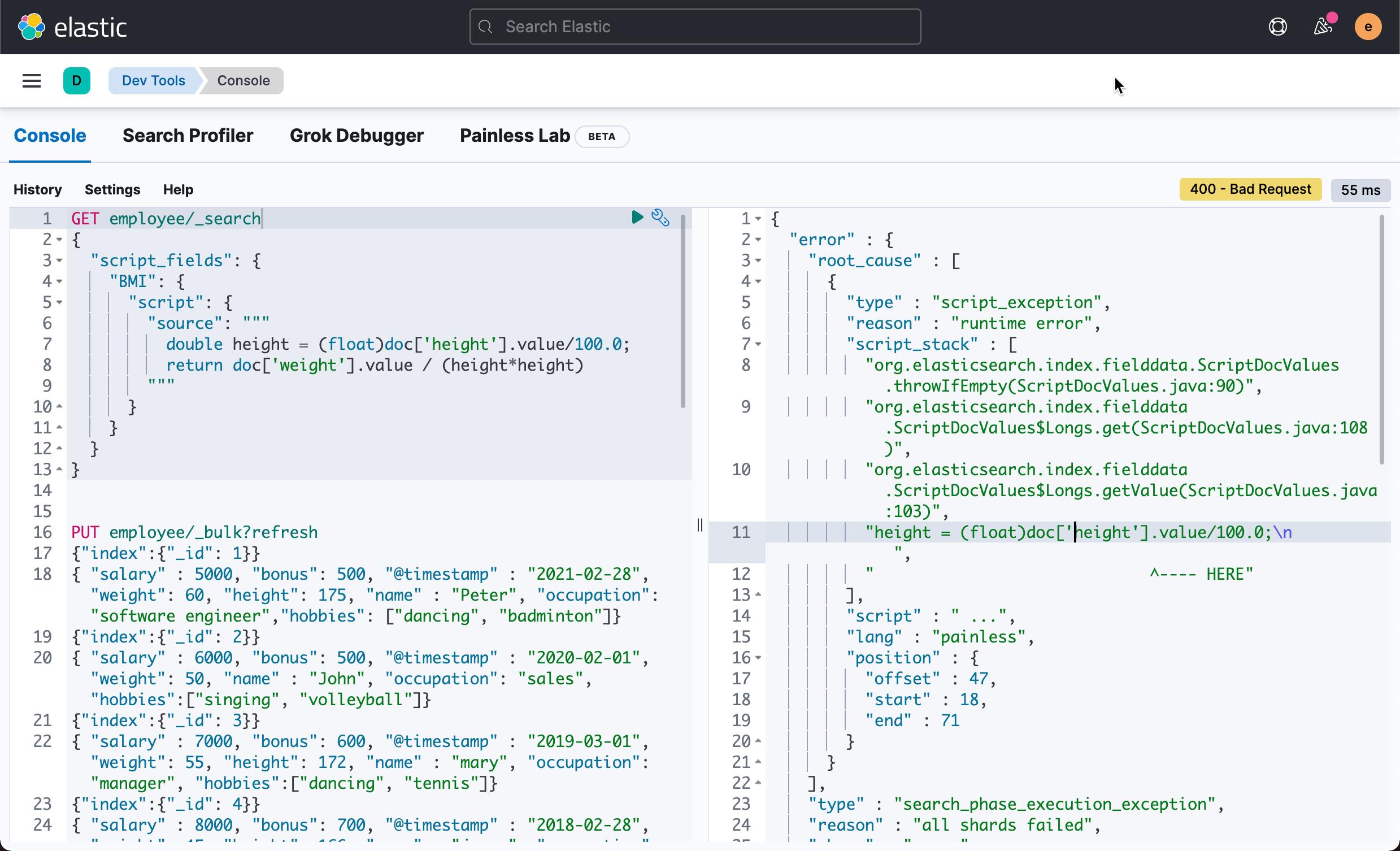
很显然这个错误的信息是由于我们的一个文档缺少 height 这个字段而造成的。一种修改这种问题的办法是添加一些代码来完成,比如:
GET employee/_search?filter_path=**.hits
"script_fields":
"BMI":
"script":
"source": """
double height = 0;
if(doc['height'].size() == 0)
height = 170/100.0;
else
height = (double)doc['height'].value/100.0;
return doc['weight'].value / (height*height);
"""
在上面,当 height 字段缺失的情况下,我们设置一个默认值为 170,这样避免了在计算中的缺失。上面的命令返回的结果为:
"hits" :
"hits" : [
"_index" : "employee",
"_id" : "1",
"_score" : 1.0,
"fields" :
"BMI" : [
19.591836734693878
]
,
"_index" : "employee",
"_id" : "2",
"_score" : 1.0,
"fields" :
"BMI" : [
17.301038062283737
]
,
"_index" : "employee",
"_id" : "3",
"_score" : 1.0,
"fields" :
"BMI" : [
18.591130340724717
]
,
"_index" : "employee",
"_id" : "4",
"_score" : 1.0,
"fields" :
"BMI" : [
16.330381768036002
]
,
"_index" : "employee",
"_id" : "5",
"_score" : 1.0,
"fields" :
"BMI" : [
20.761245674740486
]
,
"_index" : "employee",
"_id" : "6",
"_score" : 1.0,
"fields" :
"BMI" : [
16.023073225444637
]
]
针对 id 为 2 的情况,它计算出来的 BMI 为 17.301038062283737。
由于有了新的 field API,那么我们可以简化上面的计算步骤为:
GET employee/_search?filter_path=**.hits
"script_fields":
"BMI":
"script":
"source": """
double height = (double)$('height', 170)/100.0;
return doc['weight'].value / (height*height)
"""
或者:
GET employee/_search?filter_path=**.hits
"script_fields":
"BMI":
"script":
"source": """
double height = (double)field('height').get(170)/100.0;
return doc['weight'].value / (height*height)
"""
上面的代码非常之简单明了。当 height 字段不存在时,我们使用 170 来代替。上面运行的结果为:
"hits" :
"hits" : [
"_index" : "employee",
"_id" : "1",
"_score" : 1.0,
"fields" :
"BMI" : [
19.591836734693878
]
,
"_index" : "employee",
"_id" : "2",
"_score" : 1.0,
"fields" :
"BMI" : [
17.301038062283737
]
,
"_index" : "employee",
"_id" : "3",
"_score" : 1.0,
"fields" :
"BMI" : [
18.591130340724717
]
,
"_index" : "employee",
"_id" : "4",
"_score" : 1.0,
"fields" :
"BMI" : [
16.330381768036002
]
,
"_index" : "employee",
"_id" : "5",
"_score" : 1.0,
"fields" :
"BMI" : [
20.761245674740486
]
,
"_index" : "employee",
"_id" : "6",
"_score" : 1.0,
"fields" :
"BMI" : [
16.023073225444637
]
]
从上面的结果中,我们可以看出来它是一样的结果。
注意:field API 仍在开发中,应被视为 beta 功能。 API 可能会发生变化,并且此迭代可能不是最终状态。 对于功能状态,请参阅 #78920 。某些字段与 field API 不兼容,例如文本或地理字段。 继续使用 doc 访问字段 API 不支持的字段类型。
以上是关于Elasticsearch:使用新的 field API 简化 Painless 语法和文档字段访问 - Elastic Stack 8.1的主要内容,如果未能解决你的问题,请参考以下文章
Elasticsearch:了解 Elasticsearch combined fields 和 multi match 查询
elasticsearch index 之 put mapping
elasticsearch入门使用 Mapping + field type字段类型