神经网络简述
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了神经网络简述相关的知识,希望对你有一定的参考价值。
参考技术A 机器学习中谈论的神经网络是指“神经网络学习”,或者说,是机器学习和神经网络这两个学科领域的交叉部分[1]。在这里,神经网络更多的是指计算机科学家模拟人类大脑结构和智能行为,发明的一类算法的统称。
神经网络是众多优秀仿生算法中的一种,读书时曾接触过蚁群优化算法,曾惊讶于其强大之处,但神经网络的强大,显然蚁群优化还不能望其项背。
A、起源与第一次高潮。有人认为,神经网络的最早讨论,源于现代计算机科学的先驱——阿兰.图灵在1948年的论文中描述的“B型组织机器”[2]。二十世纪50年代出现了以感知机、Adaling为代表的一系列成功,这是神经网络发展的第一个高潮[1]。
B、第一次低谷。1969年,马文.明斯基出版《感知机》一书,书中论断直接将神经网络打入冷宫,导致神经网络十多年的“冰河期”。值得一提的是,在这期间的1974年,哈佛大学Paul Webos发明BP算法,但当时未受到应有的重视[1]。
C、第二次高潮。1983年,加州理工学院的物理学家John Hopfield利用神经网络,在旅行商问题上获得当时最好结果,引起轰动;Rumelhart等人重新发明了BP算法,BP算法迅速走红,掀起神经网络第二次高潮[1]。
D、第二次低谷。二十世纪90年代中期,统计学习理论和支持向量机兴起,较之于这些算法,神经网络的理论基础不清晰等缺点更加凸显,神经网络研究进入第二次低谷[1]。
E、深度学习的崛起。2010年前后,随着计算能力的提升和大数据的涌现,以神经网络为基础的“深度学习”崛起,科技巨头公司谷歌、Facebook、百度投入巨资研发,神经网络迎来第三次高潮[1]。2016年3月9日至15日,Google人工智能程序AlphaGo对阵韩国围棋世界冠军李世乭,以4:1大比分获胜,比众多专家预言早了十年。这次比赛,迅速在全世界经济、科研、计算机产业各领域掀起人工智能和深度学习的热烈讨论。
F、展望。从几个方面讨论一下。
1)、近期在Google AlphaGo掀起的热潮中,民众的热情与期待最大,甚至有少许恐慌情绪;计算机产业和互联网产业热情也非常巨大,对未来充满期待,各大巨头公司对其投入大量资源;学术界的反应倒是比较冷静的。学术界的冷静,是因为神经网络和深度神经网络的理论基础还没有出现长足的进步,其缺点还没有根本改善。这也从另一个角度说明了深度神经网络理论进步的空间很大。
2)、"当代神经网络是基于我们上世纪六十年代掌握的脑知识。"关于人类大脑的科学与知识正在爆炸式增长。[3]世界上很多学术团队正在基于大脑机制新的认知建立新的模型[3]。我个人对此报乐观态度,从以往的仿生算法来看,经过亿万年进化的自然界对科技发展的促进从来没有停止过。
3)、还说AlphaGo,它并不是理论和算法的突破,而是基于已有算法的工程精品。AlhphaGo的工作,为深度学习的应用提供了非常广阔的想象空间。分布式技术提供了巨大而廉价的计算能力,巨量数据的积累提供了丰富的训练样本,深度学习开始腾飞,这才刚刚开始。
一直沿用至今的,是McChlloch和Pitts在1943年依据脑神经信号传输结构抽象出的简单模型,所以也被称作”M-P神经元模型“。
其中,
f函数像一般形如下图的函数,既考虑阶跃性,又考虑光滑可导性。
实际常用如下公式,因形如S,故被称作sigmoid函数。
把很多个这样的神经元按一定层次连接起来,就得到了神经网络。
两层神经元组成,输入层接收外界输入信号,输出层是M-P神经元(只有输出层是)。
感知机的数学模型和单个M-P神经元的数学模型是一样的,如因为输入层只需接收输入信号,不是M-P神经元。
感知机只有输出层神经元是B-P神经元,学习能力非常有限。对于现行可分问题,可以证明学习过程一定会收敛。而对于非线性问题,感知机是无能为力的。
BP神经网络全称叫作误差逆传播(Error Propagation)神经网络,一般是指基于误差逆传播算法的多层前馈神经网络。这里为了不占篇幅,BP神经网络将起篇另述。
BP算法是迄今最为成功的神经网络学习算法,也是最有代表性的神经网络学习算法。BP算法不仅用于多层前馈神经网络,还用于其他类型神经网络的训练。
RBF网络全程径向基函数(Radial Basis Function)网络,是一种单隐层前馈神经网络,其与BP网络最大的不同是采用径向基函数作为隐层神经元激活函数。
卷积神经网络(Convolutional neural networks,简称CNNs)是一种深度学习的前馈神经网络,在大型图片处理中取得巨大成功。卷积神经网络将起篇另述。
循环神经网络(Recurrent Neural Networks,RNNs)与传统的FNNs不同,RNNs引入定向循环,能够处理那些输入之间前后关联的问题。RNNs已经在众多自然语言处理(Natural Language Processing, NLP)中取得了巨大成功以及广泛应用[5]。RNNs将起篇另述。[5]
[1]、《机器学习》,周志华著
[2]、《模式识别(第二版)》,Richard O.Duda等著,李宏东等译
[3]、《揭秘IARPA项目:解码大脑算法或将彻底改变机器学习》,Emily Singerz著,机器之心编译出品
[4]、图片来源于互联网
[5]、 循环神经网络(RNN, Recurrent Neural Networks)介绍
语义分割相关网络简述
1、Fully Convolution Networks (FCNs) 全卷积网络
相应连接:Arxiv
我们将当前分类网络(AlexNet, VGG net 和 GoogLeNet)修改为全卷积网络,通过对分割任务进行微调,将它们学习的表征转移到网络中。然后,我们定义了一种新的架构,它将深的、粗糙的网络层的语义信息和浅的、精细的网络层的表层信息结合起来,来生成精确和详细的分割。我们的全卷积网络在 PASCAL VOC(在2012年相对以前有20%的提升,达到了62.2%的平均IU),NYUDv2 和 SIFT Flow 上实现了最优的分割结果,对于一个典型的图像,推断只需要三分之一秒的时间。
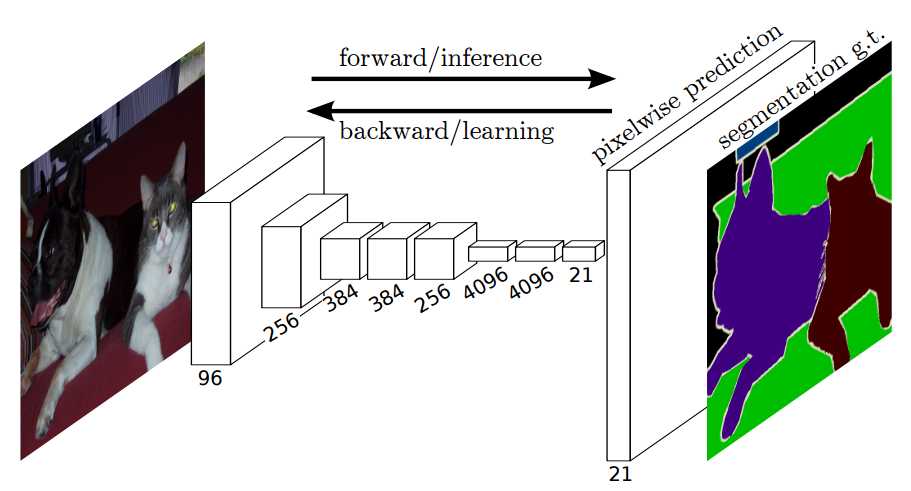
FCN端到端的密集预测流
关键点:
1、端到端预测,做pixel-wise级别的预测
2、对AlexNet、VGG等延展(全连接层转换成全卷积层)
3、fine-tune相关的网络
4、任意输入,输出分类热力图map(因为输出类没有确定,所以可以任意输入)
5、特征是由编码器中的不同阶段合并而成的,它们在语义信息的粗糙程度上有所不同
6、低分辨率语义特征图的上采样使用经双线性插值滤波器初始化的反卷积操作完成
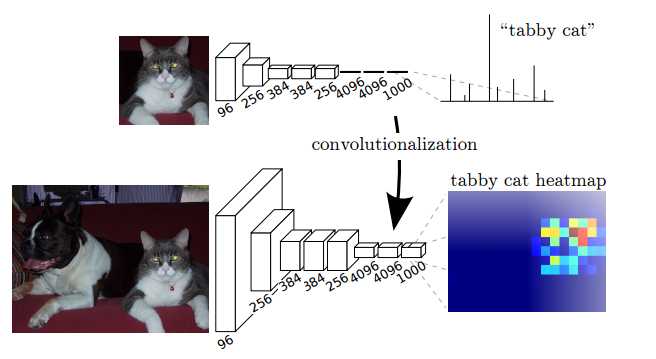
第2点: 将全连接层转换成卷积层,使得分类网络可以输出一个类的热图
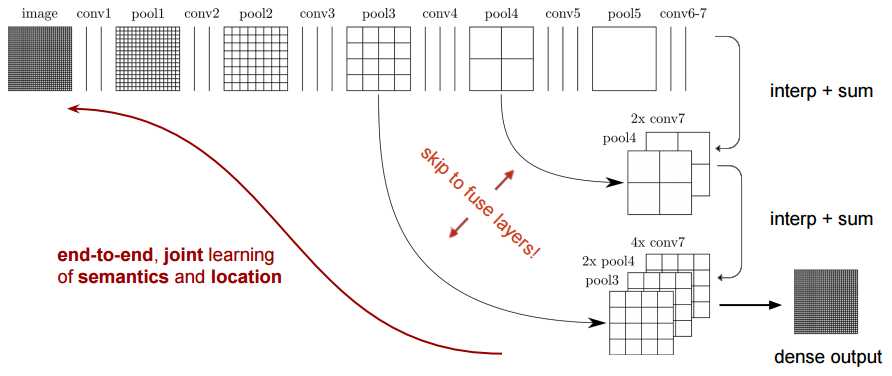
第5点:FCN-8s 网络架构
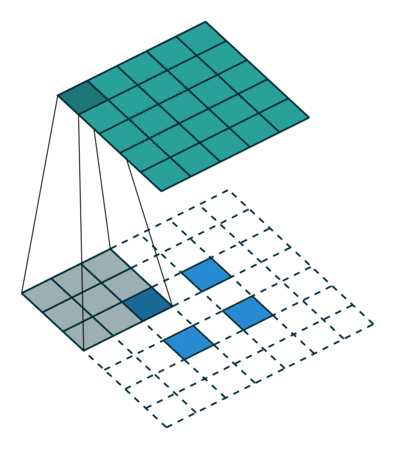
反卷积概念图
2、SegNet
相应连接:Arxiv
SegNet 的新颖之处在于解码器对其较低分辨率的输入特征图进行上采样的方式。具体地说,解码器使用了在相应编码器的最大池化步骤中计算的池化索引来执行非线性上采样。这种方法消除了学习上采样的需要。经上采样后的特征图是稀疏的,因此随后使用可训练的卷积核进行卷积操作,生成密集的特征图。我们将我们所提出的架构与广泛采用的 FCN 以及众所周知的 DeepLab-LargeFOV,DeconvNet 架构进行比较。比较的结果揭示了在实现良好的分割性能时所涉及的内存与精度之间的权衡。
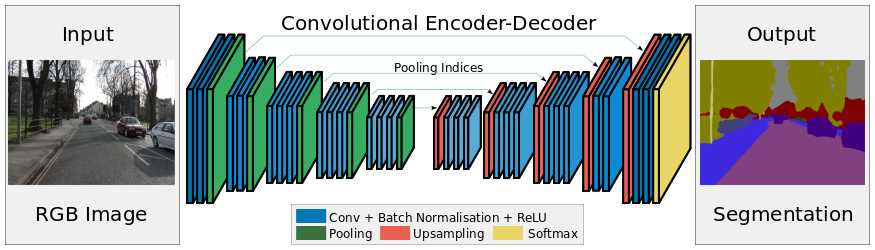
SegNet 架构
关键点:
1、在解码器中使用反池化对特征图进行上采样,并在分割中保持高频细节的完整性
2、编码器不使用全连接层(和 FCN 一样进行卷积),因此是拥有较少参数的轻量级网络
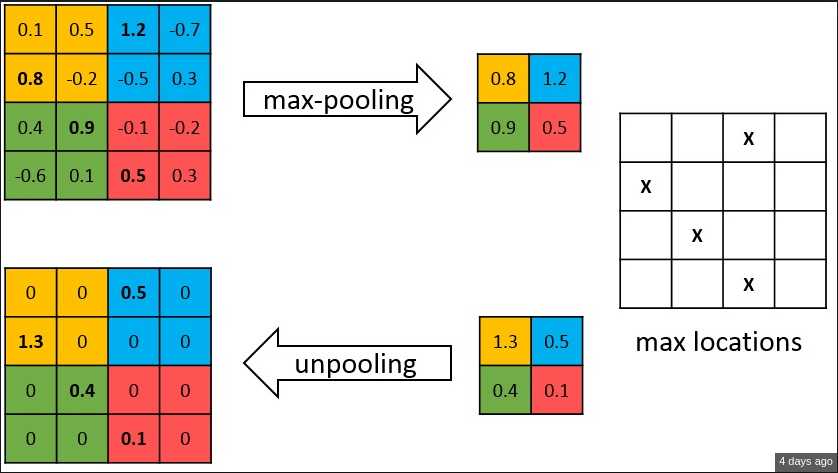
反池化
如上图所示,编码器中的每一个最大池化层的索引都被存储起来,用于之后在解码器中使用那些存储的索引来对相应的特征图进行反池化操作。虽然这有助于保持高频信息的完整性,但当对低分辨率的特征图进行反池化时,它也会忽略邻近的信息。
3、U-Net
相应连接:
以上是关于神经网络简述的主要内容,如果未能解决你的问题,请参考以下文章