Hadoop之MapReduce介绍
Posted 月疯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop之MapReduce介绍相关的知识,希望对你有一定的参考价值。
MapReduce:
1、计算过程分为俩个阶段,Map和Reduce
Map阶段并行处理输入数据
Reduce阶段对Map结果进行汇总
2、Shuffle连接Map和Reduce俩个阶段
Map Task将数据写到本地磁盘
Reduce Task从每个MapTask上读取一份数据
3、仅适合离线批处理
具有很好的容错和扩展性
适合简单的批处理任务
4、缺点明显
系统开销过大、过多使用磁盘导致效率低下
执行流程:
编程模型:map阶段进行拆分,Reduce阶段进行聚合
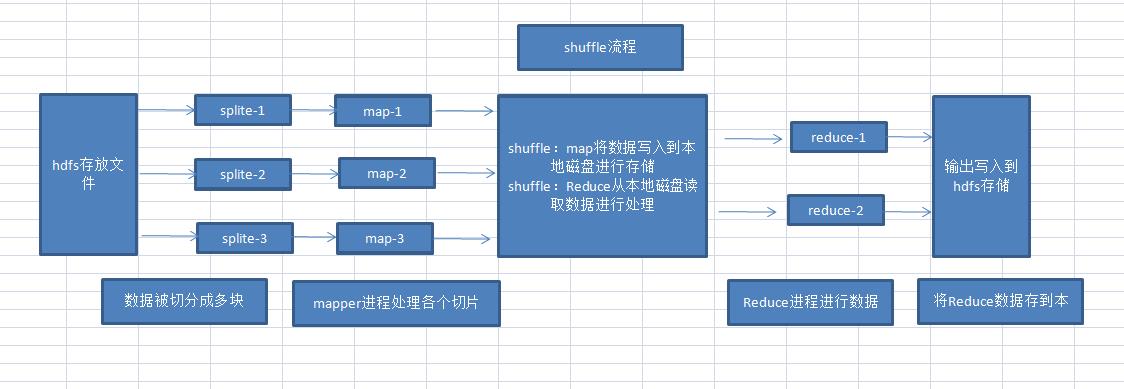
文字介绍:
1、hdfs存放的文件,进行切分成多分,交给不同的map进行处理
2、shuffle流程:map将处理的数据写入本地瓷片进行存储,Reduce从本地磁盘读取数据进行处理
3、Reduce将本地读取的数据进行聚合处理(就是放到一起整体处理,这就是批处理),然后输出到hdfs进行存储。
以上是关于Hadoop之MapReduce介绍的主要内容,如果未能解决你的问题,请参考以下文章