大数据实战之MapReduce基础介绍
Posted 进击的鱼豆腐
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据实战之MapReduce基础介绍相关的知识,希望对你有一定的参考价值。

牛年大吉
祝大家牛年大吉,希望新的一年里能顺顺利利,学业进步,事业有成!
MapReduce的定义
在hadoop中核心的部分主要分为两项,一是作为存储的hdfs,二是作为计算的mapreduce,本文将对mapreduce做一个基础介绍。
mapreduce是一个分布式运算程序的编程框架,是用户基于hadoop进行数据分析应用的核心框架。
利用mapreduce工作的流程是,编写业务逻辑代码->整合自带默认组件->本地测试->发布在hadoop上并发运行。

MapReduce的优缺点
优点
易于编程
只需要实现一些接口,便能简单地完成一个分布式程序,并且这个分布式程序可以分布在大量廉价的PC机器上运行,所以mapreduce易于编程的特点也使得mapreduce变得非常流行。
良好的拓展性
当计算资源不能满足计算要求时,可以动态地增加机器来扩展计算能力。
高容错性
因为mapreduce程序是运行在大量廉价的PC机器上,所以当其中一台机器挂了,其计算任务会转移到其它节点上运行,这样的特点使得任务不会直接运行失败,而这个过程由hadoop内部自动处理,无需人工参与。
适合PB级以上数据的离线处理
mapreduce程序可以实现上千台节点并发工作,具有强大的数据处理能力。
缺点
运行速度慢,不擅长实时计算
mapreduce运行速度缓慢,无法在毫秒或秒级内返回结果。
不擅长流式计算
流式计算的输入是动态的,而mapreduce的数据集是静态的,不能动态变化。
不擅长DAG计算
DAG计算是指多个应用之间有依赖关系,前一个应用的输出是后一个应用的输入。mapreduce能够做这种操作,但这样会造成大量的磁盘IO,导致性能低下,所以mapreduce并不适合做这种串联型应用的工作。
MapReduce核心思想
mapreduce主要分为两个阶段Map阶段和Reduce阶段,Map阶段的task互不干扰,并行执行,Reduce阶段的task也互不干扰,并行执行。关键在于Reduce的task中的输入数据依赖于Map阶段的输出,下面通过经典的wordcount实例来具体体会mapreduce的工作流程。

wordcount:统计文本中每一个单词出现的总数量。
给定初始文本

Map阶段中,程序从文本中按行读取数据,按空格分隔形成键值对,MapTask启动的个数依据切片个数决定,切片规则为:
1. 当文件大小(单位为MB)与切片大小(默认为128MB)的比值大于1.1时,则对文件切分,切片大小为128MB,剩余部分继续计算。
2. 每个文件如果不切分,单独启动一个MapTask。
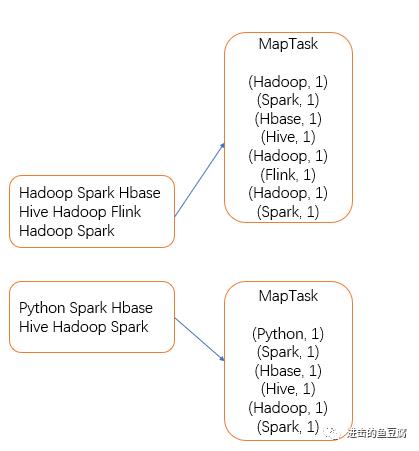
处理后的键值对会输出到环形缓冲区(默认大小为100M),如果环形缓冲区的数据达到80%,则会另外启动一个线程将数据溢写到磁盘,此时,如果开启了combine则会进行预聚合操作,即将一个MapTask内的相同单词数量相加。溢写过程中会对数据进行快速排序,溢写出的分区默认为一个,如果有其它需求,可自定义分区规则(例如按照首字母分配,前13个字母和后13个字母分配到不同的分区,最终进入到两个reduce里面,输出为两个文件,这样统计的就是首字母分别为前13个字母和后13个字母的单词个数),溢写之后,会对同一个分区的文件进行归并排序(如果溢写出了多个文件。另外注意的是:溢写如果没有溢写出文件,则直接拉取内存中的数据进行排序再写入磁盘),等待Reduce拉取数据。

ReduceTask默认为一个,ReduceTask启动的个数是通过参数手动设置的(如果分区数有多个,也要设置相同数量的reduce个数。键值对的分发规则是,key的哈希值对reduce个数取余),这里reduce为一个,所有键值对被拉取到一个ReduceTask中,对key进行分组合并。
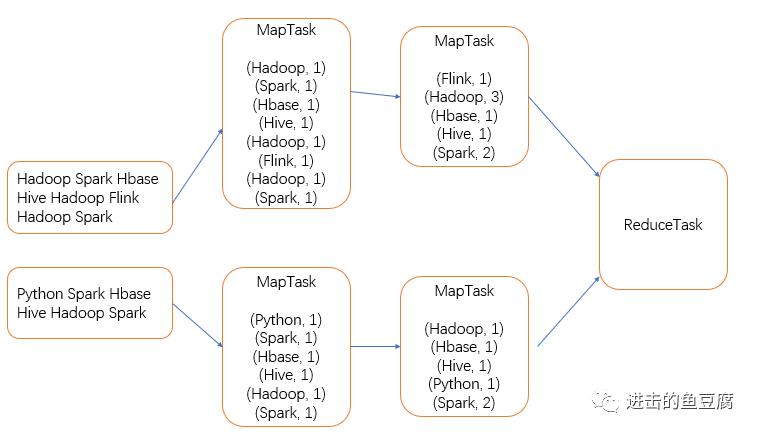
输出到磁盘
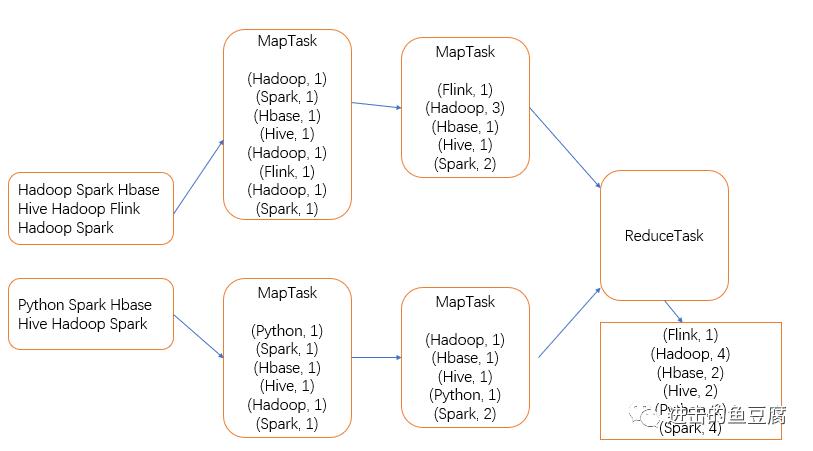

以上便是mapreduce的核心思想及运行流程,下一节会带来具体的mapreduce程序编写,跟我一起来学习吧。

扫描二维码获取
更多精彩
进击的鱼豆腐
以上是关于大数据实战之MapReduce基础介绍的主要内容,如果未能解决你的问题,请参考以下文章