Mathorcup杯大数据挑战赛复赛 B题 二手车估价思路及Python实现
Posted Better Bench
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mathorcup杯大数据挑战赛复赛 B题 二手车估价思路及Python实现相关的知识,希望对你有一定的参考价值。
目录
相关链接
题目
问题一:在初赛问题 2 的基础上,如果需要你们对车辆的成交周期进行准确预估,你们会采取什么方式建模?请你们使用附件 4“门店交易训练数据”构建交易周期预测模型,并对附件 5“门店交易验证数据”进行预测,并将预测结果保存在附件 6“门店交易模型结果”文件中,注意不要修改格式。其中附件 5“门店交易验证数据”只包括附件 4“门店交易训练数据”前 1 至 4 个字段。附件 5 的所有 carid 等相关信息都包含在附件2“估价验证数据”中。
问题二:车辆在门店售卖过程中,除了要对在库车辆未来成交周期准确预测,更需要对库存(假设门店在评估周期内场地和工作人员情况保持不变)进行有效管理,以保障在成本(车辆有资金占用成本,停车位占用成本)最小化的情况下,最大化门店的销售利润。车辆的价格是影响车辆成交非常重要的因素,门店在做库存管理时,需要根据在库车辆情况、新收车辆情况,对车辆进行销售定价或调价,一方面使得热销车辆以更合适的价格成交,保全门店利润,同时也要对滞销车辆进行降价促销,以避免更大的损失,基于此,假设你们是门店的店长,你们能决策的是何时对某个车辆是否进行调价,以及调整多大幅度,以保障门店的经营目标(最小化成本的情况下,最大化门店毛利润)达成,这里不考虑员工的人力成本等成本。请你们自己抽象问题的数学模型描述,构建门店经营模型,并给出模型的求解思路和算法步骤,这里假设经营目标一个月评估一次。
根据问题 1、2 的解答完善初赛论文,明确你们的思路、模型、方法和结果。
1 思路
1.1 第一问
是一个回归问题
用附件4作为训练集,附件5作为测试集,用LGB回归模型进行回归预测,预测出来的值向上取整。涉及交易周期的计算,这点需要注意,。。。请下载完整思路
回归模型的特征构造,除了以下我提供的baseline的特征交叉,还有其他特征构造方法。如下
参考:特征构造的方法
(1)单一变量的基础转换:x, x^2,sqrt x ,log x, 缩放
(2)如果变量的分布是长尾的,应用Box-Cox转换(用log转换虽然快但不一定是一个好的选择)
(3)你也可以检查残差(Residuals)或是log-odds(针对线性模型),分析是否是强非线性。
(4)对于基数比较大的数据,对于分类变量,创造一个表示每种类别发生频率的特征是很有用的。当然,也可以用占总量的比率或是百分比来表示这些类别。
(5)对变量的每一个可能取值,估计目标变量的平均数,用结果当做创造的特征。
(6)创造一个有目标变量比率的特征。
(7)选出最重要的两个变量,并计算他们相互之间、以及与其它变量之间的二阶交叉作用并放入模型中,比较由此产生的模型结果与最初的线性模型的结果。
(8)如果你想要的解决方案更平滑,你可以应用径向基函数核(Kadial Basis function kernel) 。这就相当应用一个平滑转换。
(9)如果你觉得你需要协变量(Covariates ),你可以应用多项式核,或者明确添加它们的协变量。
(10)高基数特征:在预处理阶段,通过out-of-fold平均转换成数值变量。
。。。。
1.2 第二问
题目要求:是否降价、降价幅度、降价时间三件事的数学模型
简单思考的话,也可以是一个回归问题,要做复杂的话,是一个规划问题。因为这题是没有数据的,要以规划来做的话,就是纯理论数学建模。以下我给出的思路及实现。
。。。略,请下载完整思路
问题二完整思路及Python实现代码 下载
2 实现
2.1 TXT转CSV
import scipy.stats as st
import pandas as pd
import seaborn as sns
from pylab import mpl
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
tqdm.pandas()
import warnings
warnings.filterwarnings('ignore')
# plt.rcParams['font.sans-serif'] = ['STSong']
# mpl.rcParams['font.sans-serif'] = ['STSong'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False
import csv
import os
import pickle
filepath = "./data/附件5:门店交易验证数据.txt"
fh = open(r'./data/.csv'.format("file5"), "w+", newline='')
writer = csv.writer(fh)
writer.writerow(["carid", "pushDate", "pushPrice", "updatePriceTimeJson"])
with open(filepath, 'r', encoding="utf-8") as f:
# try:
res = []
for line in f.readlines():
d = [x for x in line.strip().split('\\t')]
res.append(d)
writer.writerows(res)
f.close()
fh.close()
2.2 数据预处理
df4 = pd.read_csv('./data/file4.csv')
df5 = pd.read_csv('./data/file5.csv')
(1)计算交易周期
# 去除没卖出的样本
df_trans = df4[df4.withdrawDate.notna()]
。。。。略,请下载完整代码 https://mianbaoduo.com/o/bread/YpiXlpZx
train_cols = ['pushDate','pushPrice','transcycle']
df_train = df_trans[train_cols]
test_cols = ['pushDate','pushPrice']
df_test = df5[test_cols]
df_train

import scipy.stats as st
import seaborn as sns
import matplotlib.pyplot as plt
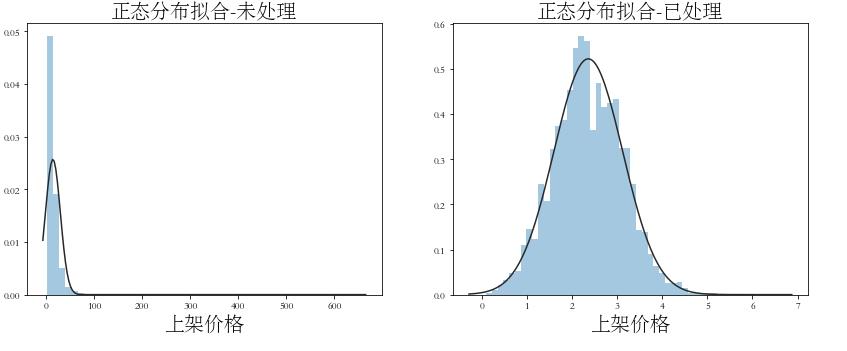
plt.figure(figsize=(14, 5))
plt.subplot(122)
plt.title('正态分布拟合-已处理', fontsize=20)
sns.distplot(np.log1p(df_train['pushPrice']), kde=False, fit=st.norm)
plt.xlabel('上架价格', fontsize=20)
plt.subplot(121)
plt.title('正态分布拟合-未处理', fontsize=20)
sns.distplot(df_train['pushPrice'], kde=False, fit=st.norm)
plt.xlabel('上架价格', fontsize=20)
plt.savefig('img/上架价格正态分布拟合.png',dpi=300)
(2)提取时间特征
# # 时间处理(提取年月日)
df_train['pushDate'] = pd.to_datetime(df_train['pushDate'])
df_test['pushDate'] = pd.to_datetime(df_test['pushDate'])
df_train['pushDate_year'] = df_train['pushDate'].dt.year
df_train['pushDate_month'] = df_train['pushDate'].dt.month
df_train['pushDate_day'] = df_train['pushDate'].dt.day
df_test['pushDate_year'] = df_test['pushDate'].dt.year
df_test['pushDate_month'] = df_test['pushDate'].dt.month
df_test['pushDate_day'] = df_test['pushDate'].dt.day
del df_train['pushDate']
del df_test['pushDate']
(3)数据分布的转换
df_train['pushPrice'] = np.log1p(df_train['pushPrice'])
df_test['pushPrice'] = np.log1p(df_test['pushPrice'])
df_train.columns
Index([‘pushPrice’, ‘update_price’, ‘barging_times’, ‘barging_price’, ‘transcycle’, ‘pushDate_year’, ‘pushDate_month’, ‘pushDate_day’], dtype=‘object’)
(4)特征交叉
#定义交叉特征统计
def cross_cat_num(df, num_col, cat_col):
for f1 in tqdm(cat_col):
g = df.groupby(f1, as_index=False)
for f2 in tqdm(num_col):
feat = g[f2].agg(
'__max'.format(f1, f2): 'max', '__min'.format(f1, f2): 'min',
'__median'.format(f1, f2): 'median',
'__sum'.format(f1, f2): 'sum',
'__mad'.format(f1, f2): 'mad',
)
df = df.merge(feat, on=f1, how='left')
return(df)
### 用数值特征 与类别特征做交叉
cross_num = ['pushPrice']
cross_cat = ['pushDate_year', 'pushDate_month','pushDate_day']
data_train = cross_cat_num(df_train, cross_num, cross_cat) # 一阶交叉
data_test = cross_cat_num(df_test, cross_num, cross_cat) # 一阶交叉
data_train.shape
(8000, 20)
2.3 模型训练
(1)模型训练
from sklearn import metrics
from sklearn.model_selection import KFold
import lightgbm as lgb
import pandas as pd
from sklearn.model_selection import KFold
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import StandardScaler
train = data_train
test = data_test
train_y = train['transcycle']
del train['transcycle']
scaler = StandardScaler()
train_x = scaler.fit_transform(train)
test_x = scaler.fit_transform(test)
from sklearn import metrics
params =
'boosting_type': 'gbdt',
'objective': 'regression_l1',
'metric': 'mae',
'num_leaves': 31,
'learning_rate': 0.05,
'feature_fraction': 0.9,
'bagging_fraction': 0.8,
'bagging_freq': 5,
'verbose': -1,
def MAE_metric(y_true, y_pred):
return metrics.mean_absolute_error(y_true, y_pred)
folds = 5
kfold = KFold(n_splits=folds, shuffle=True, random_state=5421)
preds_lgb = np.zeros(len(test_x))
for fold, (trn_idx, val_idx) in enumerate(kfold.split(train_x, train_y)):
import lightgbm as lgb
print('-------fold -------'.format(fold))
x_tra, y_trn, x_val, y_val = train_x[trn_idx], train_y.iloc[trn_idx], train_x[val_idx], train_y.iloc[val_idx]
train_set = lgb.Dataset(x_tra, y_trn)
val_set = lgb.Dataset(x_val, y_val)
# lgb
lgbmodel =。。。。略,请下载完整代码
val_pred_xgb = lgbmodel.predict(
x_val, predict_disable_shape_check=True)
preds_lgb += lgbmodel.predict(test_x,
predict_disable_shape_check=True) / folds
val_mae = MAE_metric(y_val, val_pred_xgb)
print('lgb val_mae '.format(val_mae))
-------fold 0------- lgb val_mae 15.108706443185115 -
------fold 1------- lgb val_mae 15.755760771009792
-------fold 2------- lgb val_mae 16.597388380375197
-------fold 3------- lgb val_mae 15.483798531878621
-------fold 4------- lgb val_mae 15.278992579304203
(2)将预测结果存储为TXT
import math
file5 = pd.read_csv('./data/file5.csv')
submit_file = pd.DataFrame(columns=['id'])
submit_file['id'] = file5['carid']
# 向上取整
submit_file['transcycle'] = [math.ceil(i) for i in list(preds_lgb)]
submit_file['transcycle'].astype(int)
i = 0
with open('./submit/附件6:门店交易模型结果.txt','a+', encoding='utf-8') as f:
for line in submit_file.values:
if i==0:
i += 1
continue
else:
i += 1
f.write((str(line[0])+'\\t'+str(line[1])+'\\n'))
完整思路及代码下载 见顶部链接
以上是关于Mathorcup杯大数据挑战赛复赛 B题 二手车估价思路及Python实现的主要内容,如果未能解决你的问题,请参考以下文章
2021年MathorCup高校数学建模挑战赛——大数据竞赛A题
2021 年 MathorCup 高校数学建模挑战赛-赛道A二手车估价完整方案的40页论文和代码
2021 年 MathorCup 高校数学建模挑战赛—赛道A二手车估价问题4 问题三思路和数据及参考资料
2021 年 MathorCup 高校数学建模挑战赛-赛道A二手车估价问题二 方案和python实现代码