2021 年 MathorCup 高校数学建模挑战赛—赛道A二手车估价问题的数据分析及可视化
Posted Better Bench
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021 年 MathorCup 高校数学建模挑战赛—赛道A二手车估价问题的数据分析及可视化相关的知识,希望对你有一定的参考价值。
代码下载
https://mianbaoduo.com/o/bread/YpaWlZ5p
1 Txt转为CSV
略。。。。
完整代码下载:https://mianbaoduo.com/o/bread/YpaWlZ5p
2 宏观查看数据
读取数据
train = pd.read_csv('file1.csv')
test = pd.read_csv('file2.csv')
train.info()
RangeIndex: 30000 entries, 0 to 29999
Data columns (total 36 columns):Column Non-Null Count Dtype
0 carid 30000 non-null int64
1 tradeTime 30000 non-null object
2 brand 30000 non-null int64
3 serial 30000 non-null int64
4 model 30000 non-null int64
5 mileage 30000 non-null float64
6 color 30000 non-null int64
7 cityId 30000 non-null int64
8 carCode 29991 non-null float64
9 transferCount 30000 non-null int64
10 seatings 30000 non-null int64
11 registerDate 30000 non-null object
12 licenseDate 30000 non-null object
13 country 26243 non-null float64
14 maketype 26359 non-null float64
15 modelyear 29688 non-null float64
16 displacement 30000 non-null float64
17 gearbox 29999 non-null float64
18 oiltype 30000 non-null int64
19 newprice 30000 non-null float64
20 anonymousFeature1 28418 non-null float64
21 anonymousFeature2 30000 non-null int64
22 anonymousFeature3 30000 non-null int64
23 anonymousFeature4 17892 non-null float64
24 anonymousFeature5 30000 non-null int64
25 anonymousFeature6 30000 non-null int64
26 anonymousFeature7 11956 non-null object
27 anonymousFeature8 26225 non-null float64
28 anonymousFeature9 26256 non-null float64
29 anonymousFeature10 23759 non-null float64
30 anonymousFeature11 29539 non-null object
31 anonymousFeature12 30000 non-null object
32 anonymousFeature13 28381 non-null float64
33 anonymousFeature14 30000 non-null int64
34 anonymousFeature15 2420 non-null object
35 price 30000 non-null float64
dtypes: float64(15), int64(14), object(7)
训练集有3W行数据
test.info()
Data columns (total 35 columns):
#Column Non-Null Count Dtype
0 carid 5000 non-null int64
1 tradeTime 5000 non-null object
2 brand 5000 non-null int64
3 serial 5000 non-null int64
4 model 5000 non-null int64
5 mileage 5000 non-null float64
6 color 5000 non-null int64
7 cityId 5000 non-null int64
8 carCode 5000 non-null int64
9 transferCount 5000 non-null int64
10 seatings 5000 non-null int64
11 registerDate 5000 non-null object
12 licenseDate 5000 non-null object
13 country 4604 non-null float64
14 maketype 4625 non-null float64
15 modelyear 4894 non-null float64
16 displacement 5000 non-null float64
17 gearbox 5000 non-null int64
18 oiltype 5000 non-null int64
19 newprice 5000 non-null float64
20 anonymousFeature1 4660 non-null float64
21 anonymousFeature2 5000 non-null int64
22 anonymousFeature3 5000 non-null int64
23 anonymousFeature4 3137 non-null float64
24 anonymousFeature5 5000 non-null int64
25 anonymousFeature6 5000 non-null int64
26 anonymousFeature7 1685 non-null object
27 anonymousFeature8 4584 non-null float64
28 anonymousFeature9 4587 non-null float64
29 anonymousFeature10 3769 non-null float64
30 anonymousFeature11 4927 non-null object
31 anonymousFeature12 4999 non-null object
32 anonymousFeature13 4740 non-null float64
33 anonymousFeature14 5000 non-null int64
34 anonymousFeature15 281 non-null object
dtypes: float64(12), int64(16), object(7)
测试集有5000行数据
3 查看缺失值
msn.matrix(train)

msn.matrix(test)

carCode、modelyear、country、maketype、a1、a11缺失值较少,可以选择填充或者删除该行缺失值a4、a7、a8、a9、a10、a13、a15缺失值较多,可以直接不要这个字段的列
测试集缺失值和训练集相似,和训练集同样的处理方式
4 查看异常值
只取缺失值较少或没有的字段分析
column = [ "brand", "serial", "model", "mileage", "color", "cityId", "carCode", "transferCount", "seatings",
"country", "maketype", "modelyear", "displacement", "gearbox", "oiltype", "newprice", "anonymousFeature1", "anonymousFeature2",
"anonymousFeature3", "anonymousFeature5", "anonymousFeature6", "anonymousFeature14","price"]
fig = plt.figure(figsize=(80,60),dpi=75)
for i in range(len(column)):
plt.subplot(8,4,i+1)
sns.boxplot(train[column[i]],orient= 'v',width=0.5)
plt.ylabel(column[i],fontsize = 40)
plt.show()
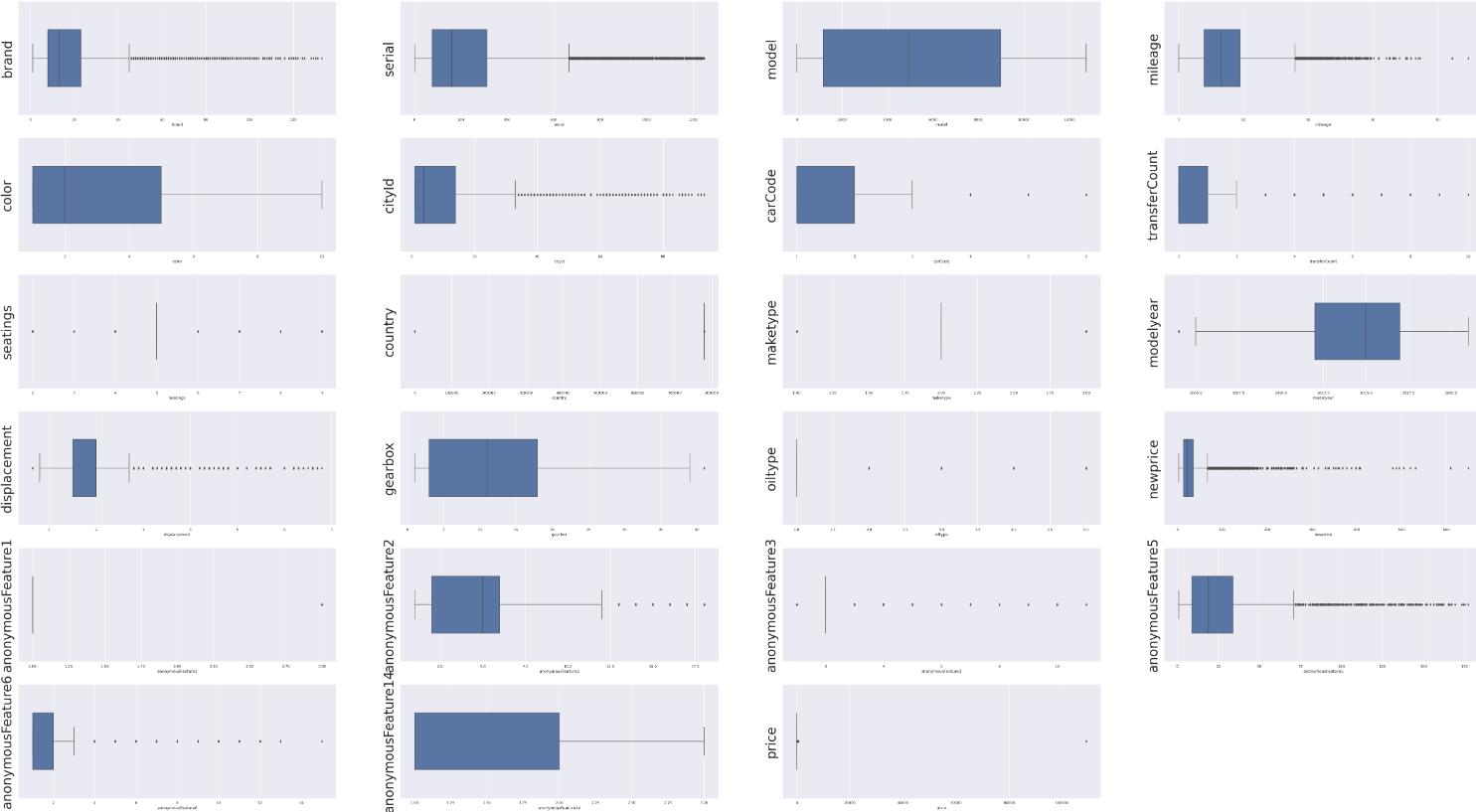
5 查看分布
(1)查看所有特征字段的数据分布
# 所有字段的分布
dist_cols = 6
dist_rows = len(test.columns)
plt.figure(figsize=(4*dist_cols,4*dist_rows))
i = 1
for col in column:
if col =='price':
continue
ax = plt.subplot(dist_rows,dist_cols,i)
ax = sns.kdeplot(train[col],color='Red',shade= True)
ax = sns.kdeplot(test[col],color='Blue',shade=True)
ax.set_xlabel(col)
ax.set_ylabel('Frequency')
ax = ax.legend(['train','test'])
i+=1
plt.show()
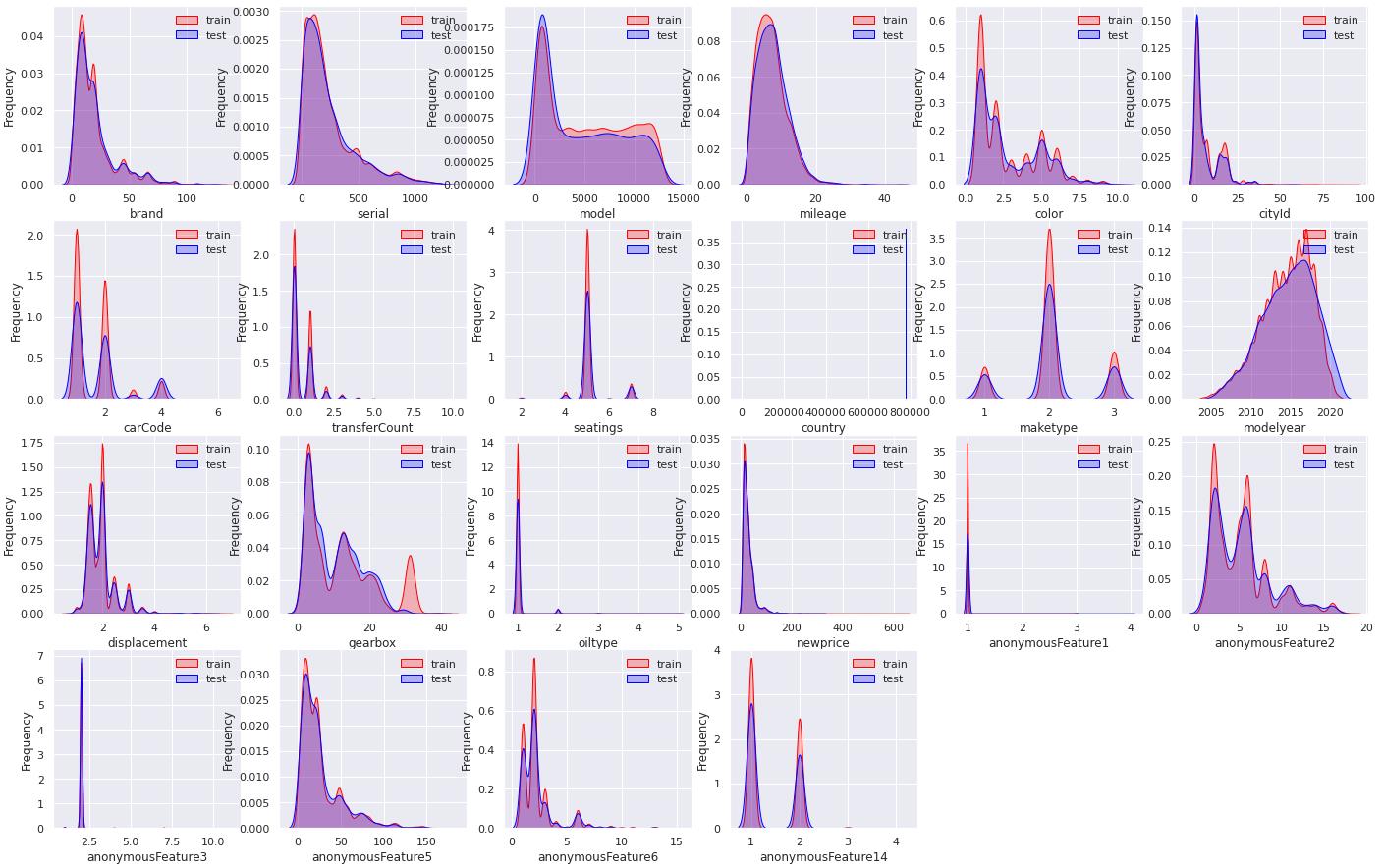
训练集和测试集的每个字段数据分布近似
(2)查看price字段的数据分布
train['price'].describe()
count 30000.000000
mean 18.062224
std 629.444049
min 0.050000
25% 6.100000
50% 10.479900
75% 18.000000
max 109000.000000
Name: price, dtype: float64
存在异常值,平均在20左右
# 价格分布
y_p = train[train['price'] <= 200]
## 3) 查看预测值的具体频数
plt.hist(y_p['price'], orientation='vertical',
histtype='bar', color='red')
plt.show()
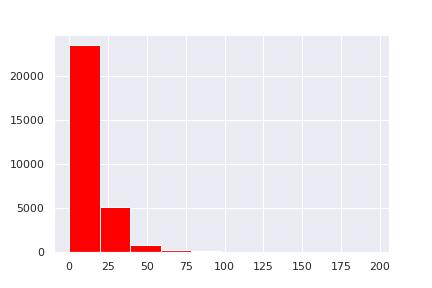
大于200的有20个,平均在75以下
(3)查看price小于75的数据的分布
sns.kdeplot(train[train['price'] < 75]['price'], color='Red', shade=True)
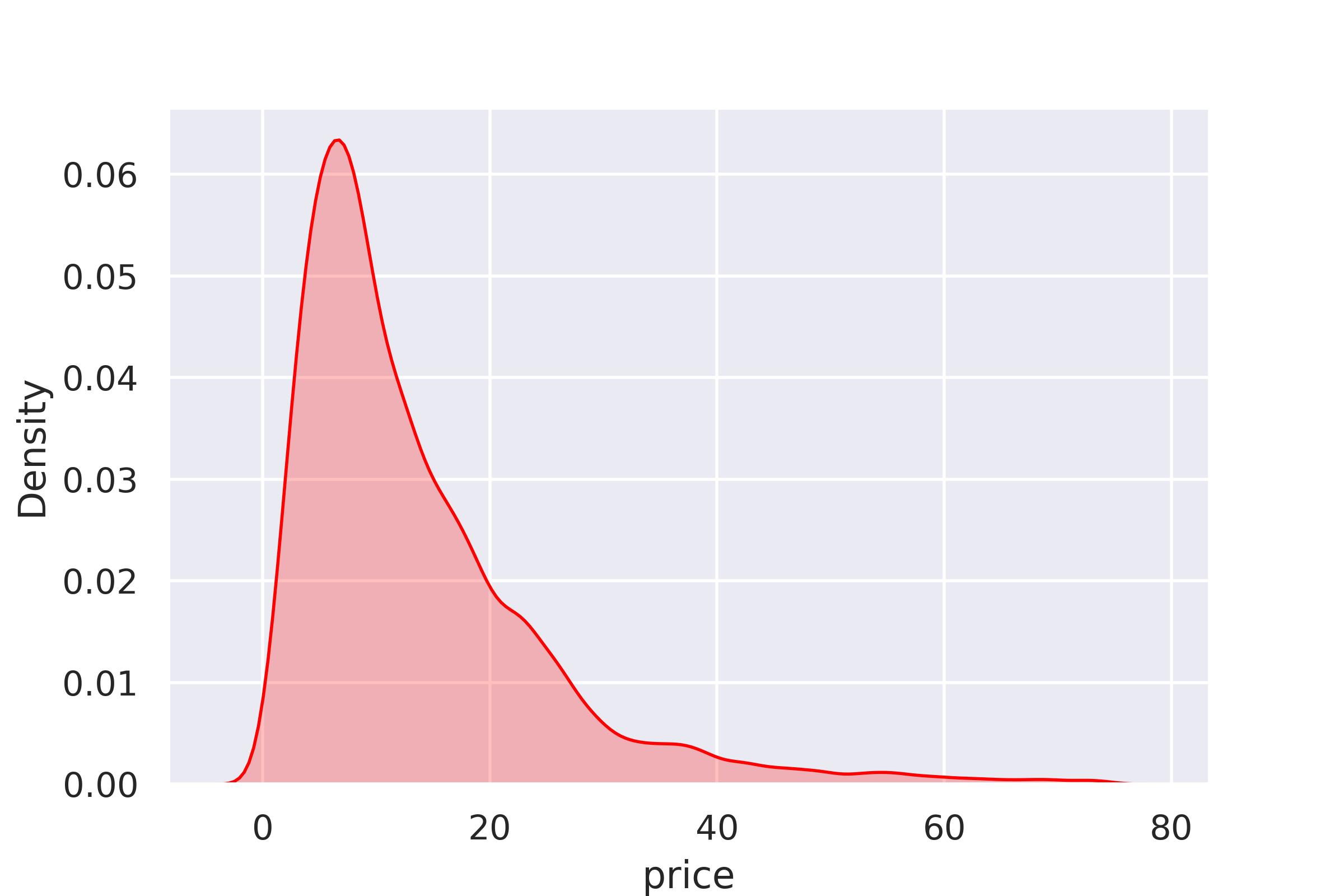
数据分布并不符合正态分布,是右偏数据,回归中对数据分布较为敏感,如果不符合正态分布需要进行数据转换成近似正态分布
# 使用对数的右偏变换函数,将数据分布转为近似正态分布
train = train[train['price']<=75]
train['price'] = np.log1p(train['price'])
# 拟合转换后的数据分布
y = train['price']
plt.title('Normal')
sns.distplot(y, kde=False, fit=st.norm)
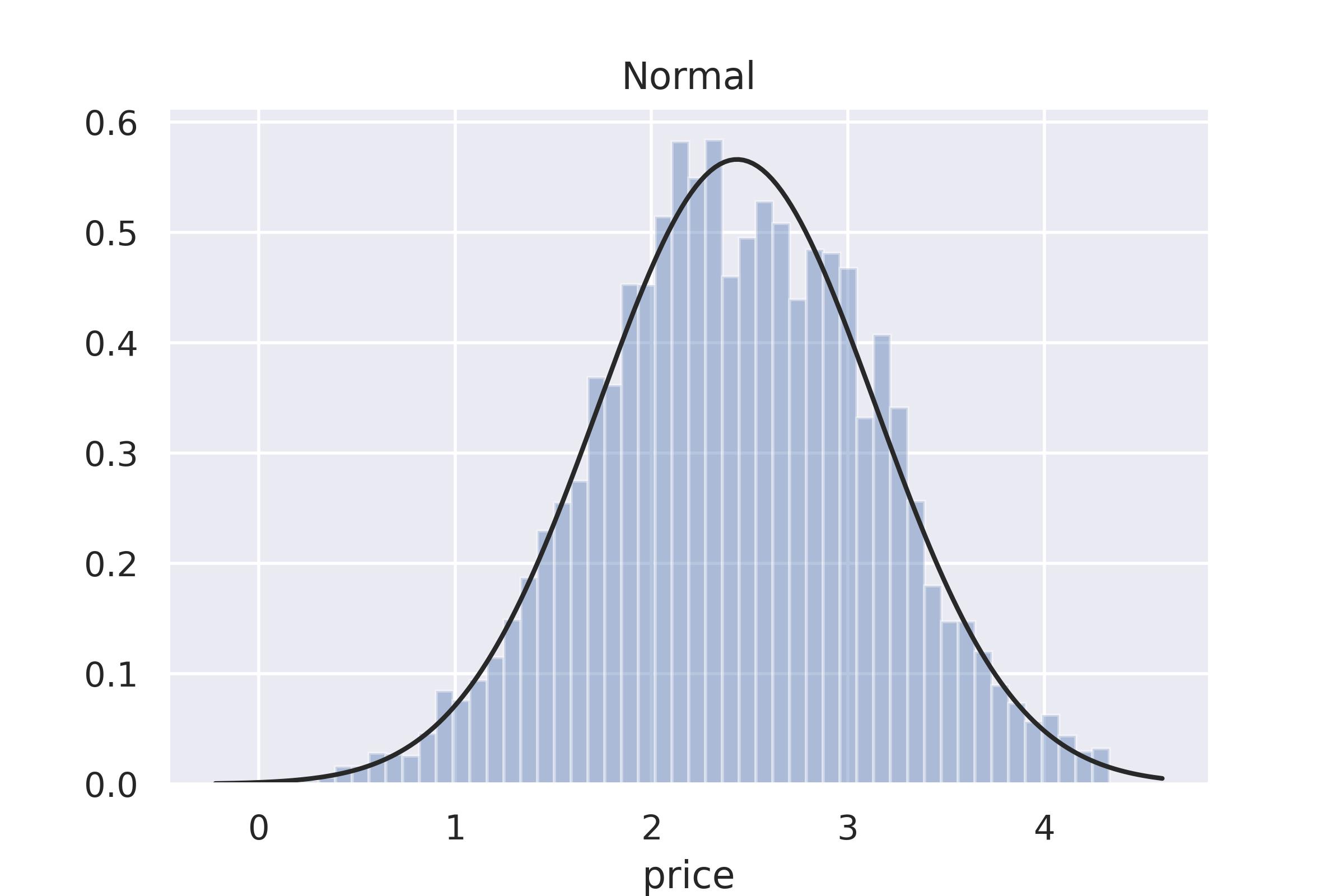
数据变换后,数据分布近似正态分布
6 查看相关性
k = len(column)
col = corr.nlargest(k,'price')['price'].index
cm = np.corrcoef(train[col].values.T)
hm = plt.subplots(figsize = (30,30))
hm = sns.heatmap(train[col].corr(),annot=True,square=True)
plt.show()
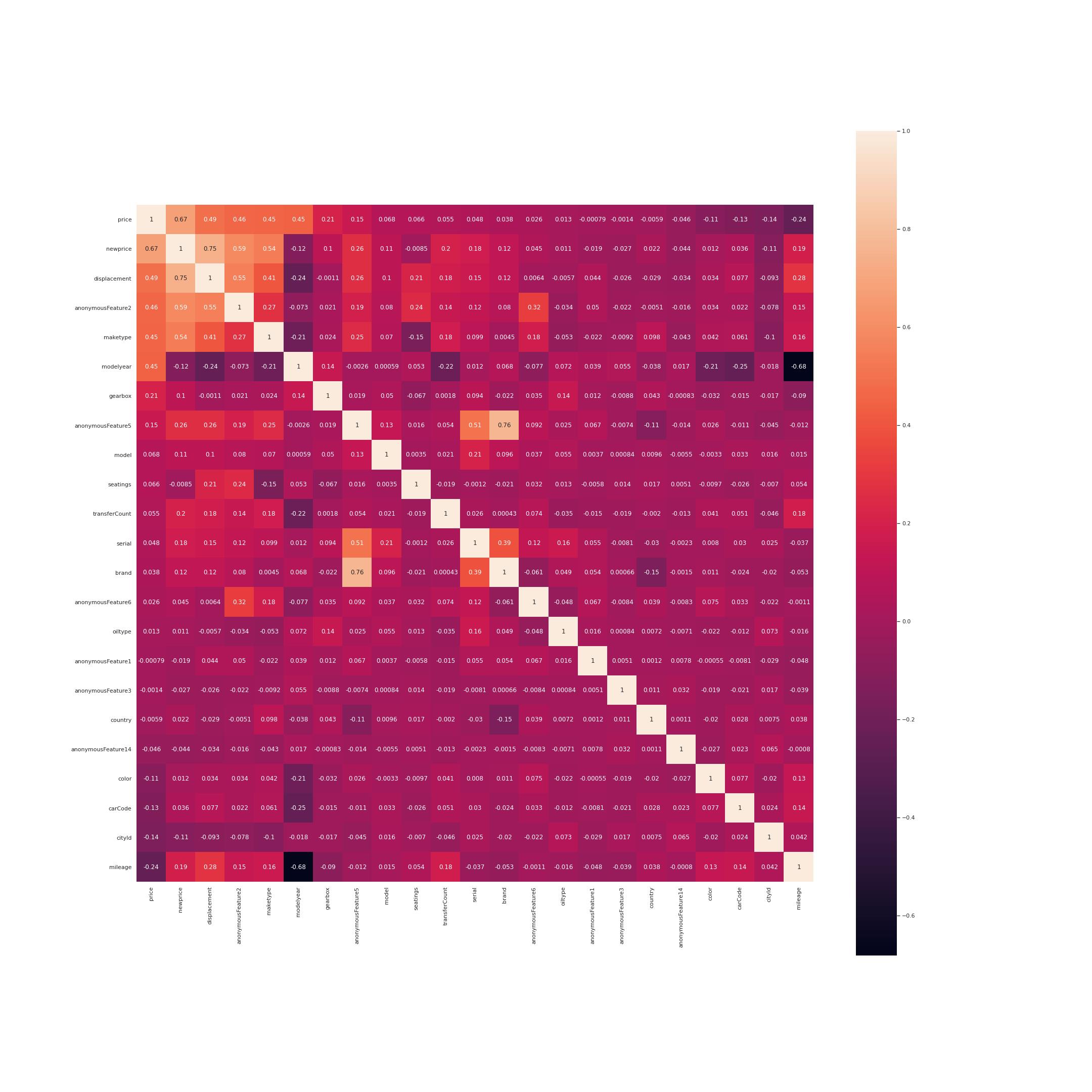
newprice、displacement、a_2、maketype、modelyear、gearvox、a_5、model、seatings、transfercount、serial、brand、a_6、oiltype与价格较为相关,且按相关强度排序,其他都是负相关
7 特征类别统计
train.columns
train.brand.value_counts()#类别特征
train.serial.value_counts()#类别特征
train.model.value_counts()#类别特征
....
总结:t所有特征可分为三种,时间特征、类别特征和数值特征。对可分类的连续特征可以进行分桶,对分类特征进行特征交叉,交叉主要获得的是特征交叉后的总数、方差、最大值、最小值、平均数、众数、峰度等。
(1)时间特征
modelyear
registerDate
licenseDate
(2)类别特征
- 离散类别特征
brand、serial、model、color、cityId、carCode、seatings、country、maketype、gearbox、oiltype、anonymousFeature1、anonymousFeature2、anonymousFeature3、anonymousFeature5、anonymousFeature6、anonymousFeature14
- 连续类别特征
mileage
(3)数值特征
newprice
transfercount
displacement
以上是关于2021 年 MathorCup 高校数学建模挑战赛—赛道A二手车估价问题的数据分析及可视化的主要内容,如果未能解决你的问题,请参考以下文章
2021 年 MathorCup 高校数学建模挑战赛—赛道A二手车估价问题4 问题三思路和数据及参考资料
数学建模MATLAB应用实战系列(138)-2021年MathorCup高校数学建模挑战赛A题思路解析(附代码)
2021年MathorCup高校数学建模挑战赛——大数据竞赛A题
2021年MathorCup高校数学建模挑战赛A二手车估价问题数学建模