Python小爬虫之协程爬虫快速上手
Posted Huterox
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python小爬虫之协程爬虫快速上手相关的知识,希望对你有一定的参考价值。
文章目录
前言
爬虫是个好东西,最近要用用这玩意,所以顺便把以前的小东西给发出来,水几篇博客~
协程
首先明确一点,线程不是多线程,线程本质上还是单线程,但是这个线程的特点是当当前线程进入到IO状态的时候,CPU会自动切换任务从而提高系统的整体运行效率。没错这个协程其实就和操作系统的多道处理机制是一样的。实现的效果有点类似使用多线程,或者线程池,但是协程是更加轻量级的,本质上就是一个单线程在来回切换。
协程快速上手
那么接下来我们先来体会一下这个协程的功效。
在python里面使用协程,也就是异步,我们需要掌握两个关键字,await 和 async。当然还有一个支持协程的库,asyncio。
我们先来看看代码。
import asyncio
import time
# 协程函数
async def do_some_work(x):
print('doing: ', x)
await asyncio.sleep(2)
return 'done '.format(x)
# 协程对象
xs = [1,2,3]
# 将协程转成task,并组成list
tasks = []
start = time.time()
for x in xs:
c = do_some_work(x)
tasks.append(asyncio.ensure_future(c))
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
print(time.time()-start
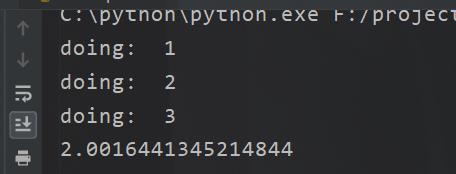
咋一看我们好像是实现了多线程,那好我把代码改一下。


看到没6秒,怎么会这样咧,如果是多线程显然必然是2秒。所以协程不是多线程,这是第一点
那好既然不是多线程,为啥刚刚是两秒呢。
协程异步运行
这个其实很简单,在此之前我们得先来说说一个方法
asyncio.sleep(2)
就是这个有什么特殊的嘛,有的,特殊点就是这个sleep相当于在进行io操作,所以明白我什么意思了不
这个sleep就是IO操作
我们这里开起来3个异步,所有的IO都交个了系统执行,所以最后我们只花了2秒。
工作流程
好了,我们现在已经体会了这个结果,那么我们是时候来说说why了。
首先第一个关键字 async 是声明这个方法,代码块是一个异步的玩意,相当于申明
await 是什么意思呢,这个就是我们为什么是两秒的“秘诀”了。这个玩意,当发现被它修饰的东西是个耗时的IO操作的时候,它就会告诉操作系统去执行IO操作,让CPU去切换其他的任务,在一个单线程程序里面,可以有多个任务。
任务管理
我们说了那两个关键字,那么问题来了,谁来告诉操作系统,谁来给我干活呢。这个时候就需要用到asyncio喽。

没错就是这部分代码。
当然协程的创建还有很多方法,只不过在爬虫里面这个用的比较多罢了,所以我这里只写这一个,事实上三个。(这个和java里面的furtertask有点类似)
aiohttp
现在到了咱们的异步爬取了,请求一,爬取资源是什么,这个其实就是一个IO操作嘛。所以我们就可以使用异步,不过这个时候,我们不能再用requests了。
得用这个,先下载
pip install aiohttp
import asyncio
import time
import aiohttp
#随便访问三次bing主页吧
urls = ["https://cn.bing.com/?FORM=Z9FD1",
"https://cn.bing.com/?FORM=Z9FD1",
"https://cn.bing.com/?FORM=Z9FD1"]
async def get_page(url):
print("开始爬取网站", url)
#异步块,在执行异步方法的时候加上await才能切换,不然就是串行咯
async with aiohttp.ClientSession() as session:
async with await session.get(url) as resp:
page = await resp.text()
print("爬取完成->",url)
return page
tasks = []
start = time.time()
for url in urls:
c = get_page(url)
tasks.append(asyncio.ensure_future(c))
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
print(time.time()-start)
那么这个aiohttp这个玩意呢,怎么说呢,里面有很多方法是和request类似的,例如刚刚的那个方法就是和requests.Session()是一样滴(高度相似)
异步保存
都说了这个了,自然还有aiofiles啦
import asyncio
import time
import aiohttp
import aiofiles
#随便访问三次bing主页吧
urls = ["https://cn.bing.com/?FORM=Z9FD1",
"https://cn.bing.com/?FORM=Z9FD1",
"https://cn.bing.com/?FORM=Z9FD1"]
async def get_page(url):
print("开始爬取网站", url)
#异步块,在执行异步方法的时候加上await才能切换,不然就是串行咯
async with aiohttp.ClientSession() as session:
async with await session.get(url) as resp:
page = await resp.text()
print("爬取完成->",url)
# async with aiofiles.open("a.html",'w',encoding='utf-8') as f:
# await f.write(page)
# await f.flush()
# await f.close()
with open("a.html",'w',encoding='utf-8') as f:
f.write(page)
f.flush()
f.close()
return page
tasks = []
start = time.time()
for url in urls:
c = get_page(url)
tasks.append(asyncio.ensure_future(c))
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
print(time.time()-start)
先说明一下这个不一定比直接写入文件块,而且有些第三方库并不支持!
异步回调
我们现在异步保存了文件,问题来了我想要直接拿到结果,然后解析呀。所以我们得来个异步回调。


import asyncio
import time
import aiohttp
import aiofiles
#随便访问三次bing主页吧
urls = ["https://cn.bing.com/?FORM=Z9FD1",
"https://cn.bing.com/?FORM=Z9FD1",
"https://cn.bing.com/?FORM=Z9FD1"]
async def get_page(url):
print("开始爬取网站", url)
#异步块,在执行异步方法的时候加上await才能切换,不然就是串行咯
async with aiohttp.ClientSession() as session:
async with await session.get(url) as resp:
page = await resp.text()
print("爬取完成->",url)
return page
def parse(task):
page = task.result() #得到返回结果
print(len(page))
tasks = []
start = time.time()
for url in urls:
c = get_page(url)
task = asyncio.ensure_future(c)
task.add_done_callback(parse)
tasks.append(task)
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
print(time.time()-start)
好了这个就是异步的玩意,这里也是为啥我用的是 未来任务,因为可以拿到参数嘛,在java里面的话就是那个callabel呗。
接下来还有个神级工具 scapy 稍后更新(看情况吧,周五呢!)
以上是关于Python小爬虫之协程爬虫快速上手的主要内容,如果未能解决你的问题,请参考以下文章