拥抱云原生!COS数据湖加速器GooseFS存算分离实践及性能优化
Posted QcloudCommunity
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了拥抱云原生!COS数据湖加速器GooseFS存算分离实践及性能优化相关的知识,希望对你有一定的参考价值。

导语 | GooseFS是一个分布式缓存系统。是存算分离架构中的一个重要角色,为上层计算框架和底层存储系统构建了桥梁。本文先对GooseFS的基础概念进行介绍,再对其架构及实践运用场景进行阐述,最后结合实践进行性能优化的呈现。
一、GooseFS简介
GooseFS是一个分布式缓存系统。是存算分离架构中的一个重要角色,为上层计算框架和底层存储系统构建了桥梁。
在腾讯云的大数据生态系统中,GooseFS介于计算框架和云存储(如COS,CHDFS,COSN)之间。GooseFS兼容Hadoop生态及同时支持FUSE,为大数据场景和AI场景带来了较大的性能提升。实际使用场景可提供2到10倍的加速。
二、大数据场景
(一)业务类型
ETL计算业务,主要包括以下两方面:
入仓任务:主要进行日志或埋点的收集,对其进行清洗转换然后入仓,该类任务一般通过实时、分钟级或小时级调度进入数据仓库。
主题计算任务:对入仓任务落地的数据进行归纳、关联 及计算,最后按照主题或业务进一步生成通用且具有价值的数据,该类任务一般通过小时级、天级或周级调度。
BI分析业务,主要进行数据分析、业务数据探查、报表制作等。便于快速洞察数据背后的关联、趋势和逻辑。
AI计算业务,主要是依赖底层数据,进行特征计算、特征分析及模型分析迭代,为其他应用或业务赋能。
在以上复杂的大数据场景,都需要对数据进行存储,传统架构大多都依赖于HDFS,目前腾讯云CHDFS及COSN完全兼容HDFS协议,能够为大数据场景提供稳定的存储服务,这是目前最常见的存算分离架构。
(二)存算分离架构
传统大数据架构采用计算和存储混部的一体化架构,在存储和计算耦合的架构中,很难在存储负载和计算负载之间达成比较好的平衡,因为这两种负载对计算机资源的诉求不同,这大大增加了运维的成本和难度。同时随着时间推移,需要存储的数据越来越多,集群规模在不断变大,那么成本就成为一个不得不面对的问题,虽然大多数据属于冷数据,但是也没有办法删除,只能一直维持其增长态势。
为了解决传统架构的痛点,存算分离架构目前是趋势,计算一般被任务是无状态的,应该具有容错、弹性等特点,才能较好满足业务需要,存算分离恰好能够解决计算存储耦合的问题,能够允许计算集群自治。存储需要具有容量大、成本低、高可用及吞吐高等特点,目前腾讯云存储COS均能满足以上特性。但是存算分离的架构需要解决的问题是存储吞吐的衰减,虽然存算分离可以减少成本,但是却要求更高存储吞吐,往往为了能够满足计算的性能,需要提供更多带宽更多存储资源,这样又会增加成本。为了解决这样的问题,GooseFS应运而生,其既能在不影响计算任务性能的同时降低存储带宽,同时可以加速数据读取性能,让计算组件和底层存储的衔接更加平滑。
三、GooseFS架构介绍

(一)Master元数据管理
和传统分布式文件系统一样,GooseFS也是中心式架构,需要有Master专门管理文件、数据块、命名空间等元数据,Master主要功能是管理GooseFS的元数据,同时和Worker保持心跳,维护整个集群拓扑,是整个集群的大脑,一旦故障整个集群将陷入不可用的状态,因此Master需要保证高可用。目前GooseFS支持两种高可用部署方案,其一是借助Zookeeper和分布式文件系统(HDFS/CHDFS/COSN),Zookeeper保障Master选主和热备,分布式文件系统用来做Journal日志的存储和恢复。其二是Master实现自治,通过Raft一致性协议保证高可用,不依赖外部组件进一步增加系统稳定性。
(二)Worker数据缓存管理
Worker负责实际的数据存储、读写、淘汰、加载和数据跃迁。文件被切割成block存储在Worker中,Master则服务block于Worker的映射关系,用作数据读取寻址。Worker会周期向Master做心跳汇报,将block信息report到Master,Master接收到心跳做相应信息的更新,之后Master会在响应Worker心跳时,携带给Worker下发的指令,如删除block等。对比HDFS的DataNode,GooseFS的Worker增加了淘汰、加载、数据跃迁三个过程,GooseFS作为缓存,淘汰是指当Worker数据被写满之后冷数据会按照一定算法被淘汰(如常见的LRU算法)。而当客户端请求的数据不在Worker中的话,会从底层存储去加载,按照局部性原理,期望下次数据读取会直接命中缓存,减少IO延时这就是对应加载流程。最后Worker同时可以支持MEM、SSD和HDD作为缓存介质,而其性能分别从高到低,所以需要保证热度越高的数据放在性能更好的介质中,所以就会有数据跃迁的过程及Worker会根据block的热度,将block在多种缓存介质之间搬迁。
(三)SDK及Proxy
GooseFS的SDK兼容HDFS及FUSE,用于支持大数据及AI的生态,同时GooseFS还支持通过自己的协议来访问,提供很多HDFS所不具备的能力,以便应对不同特殊场景。虽然GooseFS是一个分布式文件系统,但通过部署Proxy能够兼容S3协议访问,Proxy是无状态的,主要负责协议转换及请求转发,所以通过扩缩容可以支持不同规模的吞吐。GooseFS虽然定位是一个分布式文件系统,但其主要作用是对底层存储进行缓存,提升计算任务性能。为了能够屏蔽缓存对业务的侵入,GooseFS的SDK支持透明加速功能,如大数据场景可以把缓存当做一个插件,进行绑定和解绑,这一系列操作对于业务都是无感知的。这样的无损降级方式,对版本升级、运维及灰度发布都比较友好,更加保障了业务的稳定性。
(四)数据调度服务
默认情况下GooseFS可以被动完成对底层存储的缓存,无需其他额外的操作,然而对于某些极要求性能的场景来说,读取数据需要100%命中缓存才能满足性能需要。为了满足这些特殊场景的需要,需要有额外的服务来维护这些数据调度任务。数据调度服务主要负责数据预热及数据持久化等任务的调度,用来满足极端性能场景。调度主要由JobMaster和JobWorker组成,JobMaster负责所有任务管理及调度请求的接收,支持高可用部署;JobWorker负责接收JobMaster分配的Task,具体执行数据升降任务。
四、关键优化
(一)透明加速

目前多数客户的大数据架构依然采用传统架构和无缓存的存算分离架构,而且很多任务和计算组件已经对存储有依赖,如hive元数据会存储文件位置和路径(hdfs://xxx或ofs://xxx),部分计算任务对于数据存储的文件路径硬编码在代码里。如何保障在不侵入业务的前提下,透明的使用缓存对计算任务加速,成为GooseFS遇到的第一个挑战。初期方案是改造GooseFS中的SDK,基本思路是实现HCFS接口,定制属于GooseFS的FileSystem。在FileSystem中对请求的路径做映射转换(GooseFS是通过底层文件系统的挂载,实现数据缓存,所以GooseFS的文件路径可以和底层存储路径对应起来)例如GooseFS将hdfs的路径hdfs://usr/挂载成为gfs://usr,那么路径hdfs://usr/123请求到达时可以识别到挂载点为gfs://usr,那么可以将hdfs://usr/123转换为gfs://usr/123 进而实现对GooseFS的访问。上线初期,透明加速方案可以很好的工作,但是随着时间的推移,几个问题便出现。例如GooseFS需要进行重要的运维和升级,那么需要将流量卸载到底层存储上,这时流量切换就需要修改core-site.xml配置文件,而配置文件生效需要重启基础计算组件如yarn或hive。这样就会对业务有感知,少量作业或任务可能会失败。
为了解决这样的问题我们放弃通过修改core-site.xml来切换流量,而是将配置控制在GooseFS的配置文件中,每次修改客户的配置就可以进行流量切换,这就就解决了计算组件需要重启的问题。方案上线之后,失败的任务减少了很多,但是还会有极少量的失败任务,继续查找问题--为什么对配置进行的修改还会有客户端的配置没有修改呢。经过对计算任务的时序分析之后,我们找到了问题所在,就是修改了配置,但是对于已经实例化的客户端是不生效的,因为GooseFS的客户端在初始化的时候才会读取配置。如果配置修改之后,计算任务不重新获取客户端,及一个客户端被长期持有,那么配置的修改是不生效的。为了解决这个问题,我们在Client中做了配置文件的定时加载,能够让配置热生效而不是重新实例化客户端,上线之后流量切换做了任务0失败,业务无感知,这对于客户的体验是极好的。在运行期间,我们又接到纯写路径不经过GooseFS的需求,需要对配置黑名单的路径过滤;默认挂载点的需求,无需传输文件路径Schema实现请求转换,经过多番迭代,如图形成了我们最终的方案。最终线上有过多次调优和运维,都需要做流量切换,业务均无感知。
(二)系统稳定性优化
一个分布式系统,不论有多少功能上的亮点或者多强的性能,稳定性一定是最重要的,同时系统稳定性也是所有研发伙伴需要长期面对的一个问题。GooseFS在上线初期一样遇到了系统稳定性问题。主要问题集中在Master 内存泄漏、HA出现异常、元数据规模膨胀及元数据同步带来的一系列问题。
Master内存缓慢增长
在服务上线一个月左右随着数据的累积和业务量的增长,出现Master的老年代占用一直在增长,没有下降趋势,开始分析可能是元数据增长带来的内存占用增多,导致常驻内存数据累积。但是随着时间的推移和我们对元数据的估算发现内存占用的增长不可能是元数据增长导致的,本能的以为是JVM的GC性能出现了问题。接着对Master的JVM进行了一系列调优,首先垃圾回收器采用G1,同时对其参数做了多次调优,Master内存增速变慢。但是随着业务量的上升,很快Master内存增速变得更快了,甚至触发了一次fullgc导致的主从切换。我们发现主从切换后,新主的old内存占用下降了很多,庆幸的是在对Master进行调优的期间增加了gc日志,查阅gc日志发现,触发一次fullgc后,原来的主节点老年代内存并没有被回收多少。这时才意识到可能出现了内存泄漏的情况,拿到master的dump文件之后,同时结合代码分析,发现几处可能的内存泄漏点。为了能够复现内存泄漏我们增加了大量的监控,比如block维度的监控,inode维度的监控等。在测试环境经过反复的压测,通过监控共发现三个内存泄漏点,其中最严重的当属Block的内存泄漏。因为对于Block如果泄漏,删除的文件对应Block也不会被删除,内存问题会一直累积。
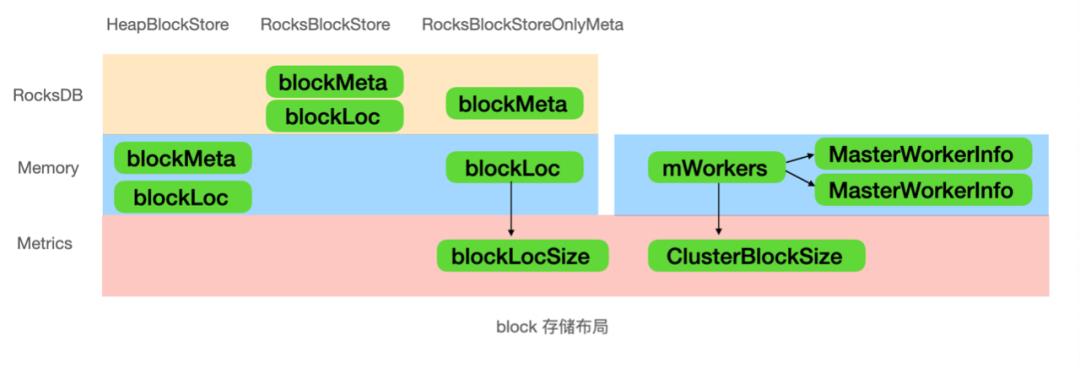
Master的内存主要由文件元数据、Block数据和Worker维度的block数据组成。如上图,block存储布局中,分为两部分blockMeta存储所有block的元数据,而blockLoc存储block的在worker中的存储位置。我们支持三种block存储模式分别是HeapBlockStore,RocksBlockStore及 RocksBlockStoreOnlyMeta,分别可以应对不同的场景,线上我们使用RocksBlockStoreOnlyMeta,及BlockMeta存储在Rocksdb中,而blockLoc存储在内存中(能够提供很好的location查找性能)。对blockLoc数据量和Worker维度的block数量增加监控指标,如图分别对应blockLocSize和ClusterBlockSize。测试发现对于文件或目录被删除之后,blockLocSize不会下降,而ClusterBlockSize则表现正常。通过分析代码逻辑,原来为了加速文件删除速度,block数据通过Worker的心跳实现异步删除,这里出现了逻辑漏洞,导致了blockLoc数据不会被删除,出现内存泄漏。经过对几个内存泄漏点的修复,线上内存终于稳定。
HA出现异常
如架构介绍中描述GooseFS的master支持ZK+分布式文件存储和基于Raft自治的两种高可用部署方式。上线初期业务量不是很大,GooseFS的Master是基于ZK部署,分为主备两个节点,同时和计算组件的Master (ResourceManager等) 混合部署。随着业务规模的上升,ZK出现超时、gc等不稳定的情况,而底层的journal存储也出现偶发的时延抖动,导致journal flush时延TP99大约30ms左右,GooseFS表现出来的是某些写请求时延较长。而且journal存储有时会发生文件损坏。遇到多种问题之后,我们意识到对ZK及其他文件系统的依赖会导致系统很不稳定。同时伴随着运维的压力的逐渐增加(如深夜或凌晨进行运维),最终决定切换基于Raft的部署模式来解决以上问题。GooseFS使用开源的Java Raft库 Apache Ratis。上线前期经历了1.0版本的压测,该组件还存在不稳定的情况,如会发生raft log不能被回收的情况。升级Ratis到2.0版本之后,不稳定问题在压测中均没有出现了。于是我在线上切换了Raft部署模式,终于HA的问题得到解决,同时journal flush的时延TP99从20ms下降到7ms左右,对元数据操作性能提升巨大。

本以为Master终于可以稳定运行了,但是内存缓慢增长的问题再度出现了。通过对Master dump文件的分析,发现是Ratis占用了大量内存,翻阅其源代码发现,Ratis会为每个raft log在内存维护一份索引数据,只有snapshot完成之后,之前的raft log才会被删除,同时内存中的索引才会被释放。查看线上Snapshot的状态,发现在某个时间点之后Snapshot不再继续进行了,这样就导致Raft log不断堆积。在对GooseFS Snapshot状态机转换增加一系列的监控后发现,Ratis在不断重试触发Snapshot制作流程,而Snapshot的状态机却卡在一个状态上不能继续推进下去了,最终导致raft log泄漏。结合线上日志以及Snapshot制作流程分析,发现grpc的拦截上有些问题,最终对Snapshot的超时检测和重试逻辑做了优化,问题成功得到解决。
元数据规模膨胀
随着数据量的增多,元数据急剧膨,Master有限的内存已经不足以存储所有元数据。GooseFS元数据支持内存及内存+Rocksdb两种存储模式,后者可以支撑更大量级的元数据。上线初期我们使用存内存存储元数据,经历过两次内存扩容,最终决定切换元数据存储模式,线上切换为内存+Rocksdb的元数据存储之后,元数据存储盘io利用率飙升很高,从原有的20%上升到70%。虽然io没有打满,但这样的io利用率可能不足以应对突发的流量洪峰。GooseFS Master元数据存储实际使用两个Rocksdb,但是这两rocksdb 部署在一块磁盘上,没有能够完全利用到多磁盘优势。GooseFS 经过优化,通过日志缩减,日志滚动模式调整,以及元数据支持多盘部署,将磁盘io利用率降了下来。同时经过测试元数据规模到达10亿级别,元数据访问性能也不会有明显衰减。
元数据主动同步
GooseFS支持底层存储的元数据被动同步,如当需要读取一个文件的时候,GooseFS中不存在,那么会从底层存储中获取其元数据,并同步到GooseFS中,但是如果同步任务太多则会影响元数据的性能,为了能够减少这种被动元数据同步带来的元数据性能衰减。我们开发了各种数据迁移工具所对应的元数据主动同步方案,如经典的Distcp或云上的CosDistcp,只需要增加一些配置,就可以把迁移之后的路径记录下来,然后定时将元数据同步到GooseFS。这样通过主动同步元数据到GooseFS就可以避免很多元数据同步请求集中爆发的情况,能够保障尽可能少的影响元数据的正常访问。
经过四个多月的稳定性优化,GooseFS得以长期稳定运行。
(三)Master元数据性能优化
GooseFS元数据支持内存+Rocksdb的存储模式,可以减少元数据增长给内存带来的压力。生产环境的元数据虽然量大,但是一般会有冷热之分,GooseFS的目标就是将热数据存储在内存,冷数据存储在Rocksdb,尽可能减少对元数据操作的性能影响。GooseFS中将内存到Rocksdb元数据流转称之为下沉,反之Rocksdb到内存的模式为加载。如当元数据请求到来的时候,会优先操作内存,元数据不存在则触发加载,元数据占用的内存空间被打满会触发下沉。实现冷热存储的关键就在于如何处理冷热数据的交换。加载的过程会比较简单,优先访问内存,不存在则从Rocksdb获取数据。下沉的过程会复杂一些,当内存空间被写满之后需要挑选哪一批数据下沉到Rocksdb中去。上线初期我们仅提供随机下沉策略,如下图使用ConcurrentHashMap来存储内存中的元数据,当数据写满之后,会有淘汰线程(Evicate Thread)遍历ConcurrentHashMap的迭代器,选取一批数据进行淘汰。由于ConcurrentHashMap特殊的数据结构,为了保证所有数据均有机会被淘汰掉,淘汰线程每次进行淘汰都会从同一个Iterator去获取数据,如图淘汰线程在t0、t1及t2时刻会从Iterator中获取数据,而ConcurrentHashMap的迭代器会保证内部每个Segment均会被遍历到。

上线初期这样的策略运行稳定表现良好,随着计算任务的增多,监控发现下沉非常频繁,导致mixed gc频繁触发,元数据性能受到影响,甚至触发full gc,经过多轮jvm调优虽然full gc触发频率变少,但是仍然会触发。我们经过一次大的升级将Open jdk8升级到Kona jdk11,才避免了full gc,但是仍然不可避免频繁的mixed gc。我们分析频繁的下沉是热数据被反复的在内存和Rocksdb之间交换导致的,是数据交换策略出现了问题,经过对计算任务特点的分析,我们决定增加LRU数据交换策略来支持线上场景。如下图每个Segment其实是一个LRU Cache,多个Segment是为了提升并发性能,因为经典的LRU实现是加锁的,而多个Segment可以减少锁的临界区,数据读写通过hash算法将请求打入某个Segment。对于Segment,经典的LRU实现,会导致两个问题,第一在put的时候进行数据淘汰,会增加元数据操作时延,第二在put的时候对两个key加锁,在文件系统中会有死锁的可能。为了避免这些问题,在Segment中只维护无界LRU队列,数据下沉则交给独立的淘汰线程。为了保证每个Segment淘汰机会均等,淘汰进行在每次淘汰的时候都会从每个Segment的LruQueue中获取数据,最终组成一批待下沉数据进行淘汰,如图淘汰线程在t0、t1及t2时刻均会获取一个LruIterator,LruIterator会维护从所有Segment中获取的数据,然后淘汰线程通过遍历Lru的迭代器进行数据淘汰。LRU策略上线之后,GC触发频率得到很大改善,rename性能提升了近5倍,worker的心跳性能提升近6倍。

值得一提的是,数据下沉频率大大减少,下图分别是上线前后的元数据下沉频率对比,从一分钟好几次下降到一个小时左右一次,效果提升十分明显,后续我们会根据不同场景研发对应数据交换策略,不断优化元数据的性能。


五、总结
GooseFS在稳定性和性能上做了很多优化,前提是能够有全方位的监控,上线以来GooseFS增加了30多项监控,修复及优化了很多稳定性和性能问题。中间历经多次升级和运维,遇到紧急问题常常需要深夜和凌晨处理。加入GooseFS的存算分离架构,相比原始的存算一体方案,为某客户降低50%的整体成本,提升29%的计算作业性能,同时GooseFS峰值可以承接约60%多的读带宽,极大降低底层存储的压力和存储成本。
作者简介

张腾
腾讯后台研发工程师
腾讯后台研发工程师,毕业于西安电子科技大学。目前主要从事腾讯COS数据湖加速器GooseFS的开发工作,从事文件系统及分布式存储开发多年,有丰富的存储经验。
推荐阅读

以上是关于拥抱云原生!COS数据湖加速器GooseFS存算分离实践及性能优化的主要内容,如果未能解决你的问题,请参考以下文章